

🔬 Research Summary by Nabeel Seedat and Fergus Imrie
Nabeel Seedat is a PhD student at the University of Cambridge (van der Schaar lab).
Fergus Imrie is a post-doctoral researcher at the University of California, Los Angeles (van der Schaar lab).
[Original paper by Nabeel Seedat, Fergus Imrie, and Mihaela van der Schaar]
Overview: Revolutionary advances in machine learning (ML) algorithms have captured the attention of many. However, to truly realize the potential of ML in real-world settings, we need to consider many aspects beyond new model architectures. In particular, a critical lens on the data used to train the ML algorithms is a crucial mindset shift. This paper introduces a data-centric AI framework called DC-Check, as an actionable checklist for practitioners and researchers to elicit such data-centric considerations through the different stages of the ML pipeline: Data, Training, Testing, and Deployment. DC-Check is the first standardized framework to engage with data-centric AI and aims to promote thoughtfulness and transparency before system development.
Introduction
The rise of AI-powered applications in industries like e-commerce, finance, manufacturing, and medicine profoundly impacts how we live and work. However, developing reliable systems can be challenging, as evidenced by numerous high-profile failures, such as gender and racial biases in Twitter’s image cropping algorithm [1] and Google Health’s diabetic retinopathy system, which failed on images with lower quality than development [2]. Even more alarmingly, 85% of industrial AI/ML systems are projected to produce incorrect results due to biases in the data or algorithms [3].
This is where DC-Check comes in: we aim to change this reality and bring a data-centric approach to AI development. By focusing on the data, we aim to create AI systems that are not only highly predictive but also reliable and trustworthy.
DC-Check: the actionable Data-centric AI guide
Data-centric AI is an important new avenue to enable reliable machine learning. However, there currently is no standardized process to facilitate and communicate the design of data-centric AI systems — making the agenda hard to engage with. DC-Check solves this by providing an actionable checklist for all stages of the ML pipeline.
For practitioners & researchers
DC-Check is aimed at both practitioners and researchers, providing a set of questions to guide users to think critically about the impact of data on each stage of the pipeline, along with practical tools and techniques.
Beyond a documentation tool
DC-Check supports practitioners and researchers in achieving greater transparency and accountability about data-centric considerations for ML pipelines.
Key Insights
Data-centric AI has emerged as an essential concept to improve ML systems in practice [4,5,6,7]. However, there’s still a gap in how to make data-centric AI a reality, especially with the lack of standardized processes around the key design considerations necessary for data-centric AI. This makes it difficult for practitioners to engage with the concept of data-centric AI and apply it to their work. DC-Check aims to solve this with an actionable checklist covering all stages of the ML pipeline, providing a guide for building data-centric AI systems.
What is Data-centric AI, and why do we need it?
The current paradigm in machine learning is model-centric AI. The data is considered a fixed and static asset (e.g., tabular data in a .csv file, a database, a language corpus, or an image repository). The data is often considered external to the machine learning process, with the focus on model iteration, whether it is new model architectures, novel loss functions, or optimizers – to improve predictive performance for a fixed benchmark.
Of course, these considerations are important — but we need more for reliable ML systems. We believe the current focus on models and architectures as a panacea in the ML community is often a source of brittleness in real-world applications. In DC-Check, we outline why the data work, often undervalued as merely operational, is key to unlocking reliable ML systems in the wild.
Contrasting model-centric AI, in data-centric AI, we give data center stage. Data-centric AI views model or algorithmic refinement as less important and instead seeks to improve the data used by ML systems systematically.
In DC-Check, we call for an expanded definition of data-centric AI such that a data-centric lens applies to end-to-end machine learning pipelines. Our definition is as follows:
Definition
Data-centric AI encompasses methods and tools to systematically characterize, evaluate, and monitor the underlying data used to train and evaluate models. At the ML pipeline level, this means that the considerations at each stage should be informed in a data-driven manner.
We term this a data-centric lens. Since data is the fuel for any ML system, we should focus on the data sharply. Yet, rather than ignoring the model, we should leverage the data-driven insights as feedback to improve the model systematically.
DC-Check offers a comprehensive and data-centric approach to AI, guiding the design of the entire machine-learning pipeline. This checklist is designed for both practitioners and researchers, offering practical tools and techniques to address data-centric challenges and a set of questions to guide users to think critically about the impact of data on each stage of the pipeline.
DC-Check is more than just a documentation tool; it promotes transparency and accountability by highlighting the data-centric considerations necessary for reliable ML systems. This level of transparency is critical for decision-makers in organizations, regulators, and policymakers to make informed decisions about AI systems.
DC-Check covers the following four key stages of the machine learning pipeline. By engaging with data-centric considerations from the outset, we can build machine learning systems that are reliable, robust, and capable of adapting to real-world conditions.
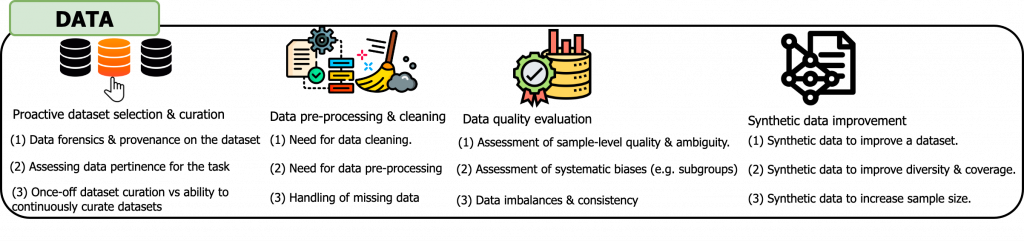
Data:
Considerations to improve the quality of data used for model training, such as proactive data selection, data curation, and data cleaning
Training:
Considerations based on understanding the data to improve model training, such as data-informed model design, domain adaptation, and robust training
Testing:
Considerations around novel data-centric methods to test ML models include informed data splits, targeted metrics and stress tests, and evaluation of subgroups.

Deployment:
Considerations based on data post-deployment, such as data and model monitoring, model adaptation and retraining, and uncertainty quantification

Between the lines
DC-Check is a checklist-style framework that guides the development of reliable ML pipelines using a data-centric approach. As ML applications become more widespread, the traditional mindset of optimizing only for predictive performance on benchmark tasks is no longer enough, and it’s time for the ML community to shift to a more comprehensive and systematic approach to ensure reliability in the real world.
With DC-Check’s actionable steps, we can ensure the data-centric spirit is ingrained in the development process from the start rather than post-hoc when failure strikes. The DC-Check website (https://www.vanderschaar-lab.com/dc-check/) is an evolving resource for engaging with and using the framework.
DC-Check is not just a tool to help build better ML systems; it’s also a call to action for the research community. A data-centric approach is key to moving away from a purely performance-driven mindset and towards a more systematic and comprehensive approach to building reliable ML systems, making DC-Check a valuable resource for anyone developing ML systems.
References
[1] Rumman Chowdhury. Sharing learnings about our image cropping algorithm, May 2021.
[2] Emma Beede, Elizabeth Baylor, Fred Hersch, Anna Iurchenko, Lauren Wilcox, Paisan Ruamviboonsuk, and Laura M Vardoulakis. A human-centered evaluation of a deep learning system deployed in clinics for the detection of diabetic retinopathy. In Proceedings of the 2020 CHI conference on human factors in computing systems, pages 1–12, 2020.
[3] Katie Costello and Meghan Rimol. Gartner identifies the top strategic technology trends for 2021. Gartner, 2021
[4] Andrew Ng. 2021. MLOps: from model-centric to data-centric AI. Online unter https://www. deeplearning. ai/wp-content/uploads/2021/06/MLOps- From-Model-centric-to-Data-centricAI.pdf (2021).
[5] Weixin Liang, Girmaw Abebe Tadesse, Daniel Ho, L Fei-Fei, Matei Zaharia, Ce Zhang, and James Zou. 2022. Advances, challenges and opportunities in creating data for trustworthy AI. Nature Machine Intelligence 4, 8 (2022), 669–677.
[6] Neoklis Polyzotis and Matei Zaharia. 2021. What can Data-Centric AI Learn from Data and ML Engineering? arXiv preprint arXiv:2112.06439 (2021).