

🔬 Research Summary by Lennart Heim, a Research Scholar at the Centre for the Governance of AI and Research Fellow at Epoch.
[Original paper by Jaime Sevilla, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, and Pablo Villalobos]
NOTE: This post was written based on work done in 2022.
Overview: Compute required for training notable Machine Learning systems has been doubling every six months — growing by a factor of 55 million over the last 12 years. This paper curates a dataset of 123 ML models and analyses their compute requirements. The authors find three distinct trends and explain them in three eras: Pre Deep Learning era, the Deep Learning era starting in 2012, and a new emerging Large-Scale trend in 2016.
Introduction
Computational resources (in short, compute) are a necessary resource for ML systems. Next to data and algorithmic advances, compute is a fundamental driver of advances in AI, as the performance of machine learning models tends to scale with compute. In this paper, the authors study the amount of compute required — measured in the number of floating point operations (FLOP) — for the final training run of milestone ML systems. They curate a dataset of 123 ML models over the last 50 years, analyze their training compute, and explain the trends in three eras.
Key Insights
Three Eras
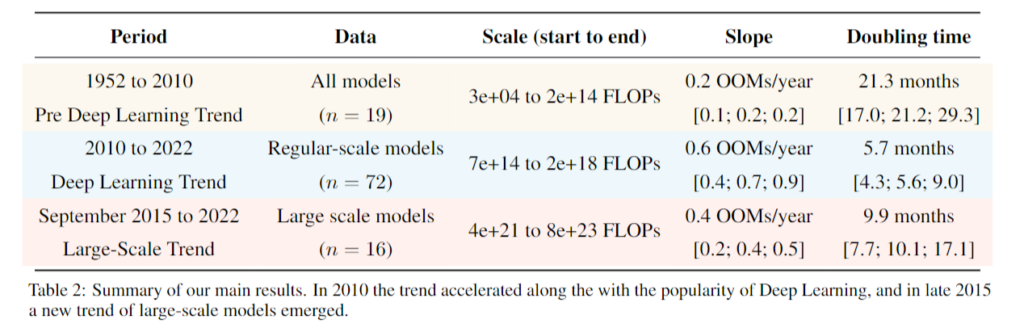
The authors find that before the Deep Learning era, training compute approximately followed Moore’s law, doubling every 20 months. With the emergence of the Deep Learning era between 2010 and 2012, the doubling time speeds up to 5 to 6 months.
More recently, they found a new separate trend of large-scale models, which emerged in 2015 and 2016 with massive training runs sponsored by large private corporations. This trend is distinct in two to three orders of magnitude (OOMs) more compute required than systems following the previous Deep Learning era trend. They find a doubling time of 10 months for these systems.
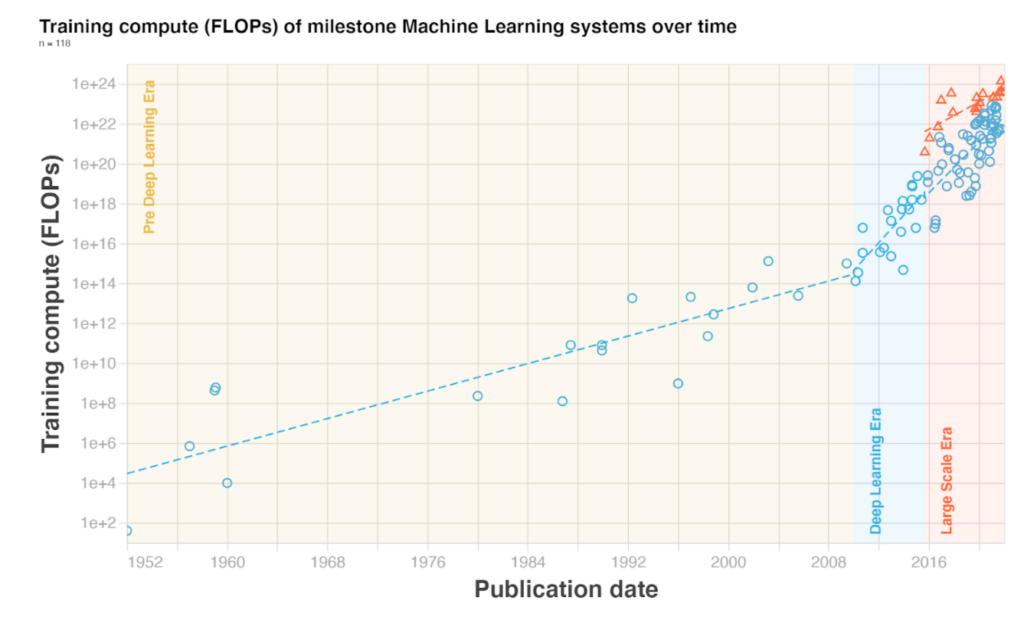
Slower than previously reported
OpenAI’s analysis from 2018 finds a 3.4-month doubling from 2012 to 2018. Their analysis suggests a 5.7-month doubling time from 2012 to 2022.
The paper’s analysis differs in three points: (I) the number of samples, (II) the extended period, and (III) the identification of a distinct large-scale trend. Of these, either the period or the separation of the large-scale models is enough to explain the difference between the results. However, a doubling time of 6 months is still enormously fast and probably unsustainable in the future, with training these systems costing three digits million.
Public dataset and visualization
The dataset stemming from this paper is public and is continuously updated. You can use it for your analysis. The authors are also maintaining an interactive visualization which you can explore here.
Between the lines
Growth in training compute is unprecedented and largely enabled by increased spending on compute. In contrast, the performance of the best-performing high-performance computer has only grown by a factor of ≈245x in the same period (compared to the 50M growth in training compute). Consequently, participating at the cutting edge of ML research has become more costly. Cutting-edge research in ML has become synonymous with access to large compute budgets or computing clusters and the expertise to leverage them. This is highlighted by the fact that since 2015 all compute training record-setting models stemming from the industry. The overall share of academia has significantly declined over time.
In response to this compute divide, nations are exploring plans to support academic and governmental researchers by providing them with more compute. The US’s National AI Research Resource (NAIRR) is the most prominent example.