


🔬 Research Summary by Patrick Zschech, Sven Weinzierl, Nico Hambauer, Sandra Zilker, and Mathias Kraus.
Patrick Zschech is an Assistant Professor at FAU Erlangen-Nürnberg, focussing on the design and analysis of intelligent information systems based on modern AI technologies and machine learning algorithms.
Nico Hambauer is a Graduate Student at FAU Erlangen-Nürnberg, focusing on data analytics and AI modeling for expert systems in business, industry, and health.
Sven Weinzierl is a postdoctoral researcher at FAU Erlangen-Nürnberg. His research interests focus on data-driven decision support in organizations. This includes the design and use of innovative machine learning and deep learning solutions.
Sandra Zilker is a researcher and Ph.D. candidate at FAU Erlangen-Nürnberg, focussing on business analytics, specifically predictive and prescriptive process monitoring.
Mathias Kraus is an Assistant Professor for Data Analytics at FAU Erlangen-Nürnberg. His research interests cover applied machine learning with a focus on interpretable and explainable artificial intelligence.
[Original paper by Patrick Zschech, Sven Weinzierl, Nico Hambauer, Sandra Zilker, and Mathias Kraus]
Overview: Generalized additive models (GAMs) are a promising type of interpretable machine learning model. In GAMs, predictor variables are modeled independently in a non-linear way to generate so-called shape functions. Such shape functions can capture arbitrary patterns while remaining fully interpretable. As the community has brought forth several advancements in the field, we investigate a series of innovative GAM extensions and assess their suitability for various regression and classification tasks. More specifically, we examine the prediction performances of five different GAM variants compared to six traditional machine learning models. We demonstrate no strict trade-off between model interpretability and model accuracy for prediction tasks on tabular data.
Introduction
Explainable artificial intelligence (XAI) is currently receiving huge attention as the field demands more transparency about the internal decision logic of machine learning (ML) models. However, most techniques subsumed under XAI, such as SHAP and LIME, provide post-hoc-analytical explanations. These explanations must be considered with caution as they can only be used to explain predictions of already known instances and therefore try to reconstruct the cause of a generated prediction through approximation. Thus, a final validation for model behavior under unseen conditions is prohibited.
In this blog post, we want to draw your attention to approaching model transparency by building intrinsically interpretable ML models. In general, the idea of intrinsically interpretable ML models is to constrain the model structure such that the resulting models provide a better understanding of how predictions are generated. One of the most promising directions in this area is concerned with generalized additive models (GAMs) (Hastie and Tibshirani, 1986; Lou et al., 2012). In GAMs, input variables are mapped independently in a non-linear manner, and the mappings are summed up afterward. Thus, GAMs include additive model constraints yet drop the linearity constraint of a simple logistic/linear regression model. This way, it is still possible to extract univariate mappings from the model, where each mapping shows the relation between a single input feature and the response variable. These mappings are commonly known as shape functions. Since shape functions can take any arbitrary form, GAMs typically achieve much better prediction accuracies than simple linear models (Figure 1). However, as they do not contain high-order interactions between features, they can be easily interpreted by model users and developers for decision assessment or model debugging purposes.


Figure 1: Difference between shape functions of a simple linear regression model on the left and a generalized additive model (GAM) on the right. While a simple regression model is subject to strict linearity, the shape functions of GAMs can capture arbitrary patterns.
In our study, we investigate a series of advanced GAM extensions. Specifically, we perform a comprehensive evaluation study in which we apply five GAMs and six commonly used ML models on twelve regression and classification datasets to compare their predictive performance and assess their suitability for the community. Our results demonstrate that modern GAM extensions, being fully interpretable, can achieve competitive prediction results. Therefore, they provide a technically equivalent but ethically more acceptable alternative to black-box models.
Key Insights
Experimental setup
For our cross-model comparison, we performed a series of computational experiments and examined the following five GAM approaches, for which publicly accessible implementations are available:
- Splines (Hastie and Tibshirani, 1986),
- Explainable boosting machine (EBM) (Nori et al., 2021),
- Neural additive model (NAM) (Agarwal et al., 2021),
- GAMI-Net (Yang et al., 2021a), and
- Enhanced explainable neural network (ExNN) (Yang et al., 2021b).
The implementations are provided by the respective authors of the proposed models, except for splines, for which we used the Python package pyGAM. Additionally, the following benchmark models were included for a broader comparison:
- Linear/logistic regression (LR),
- Decision tree (DT),
- Random forest (RF),
- Gradient boosting machine (GBM),
- XGBoost (XGB), and
- Multi-layer perceptron (MLP).
For implementing these models, we used the corresponding Python packages from the scikit-learn library, except for XGB, where we used the XGBoost library. To provide a fair comparison, we integrated all implementations into a shared environment to run the experiments under the same conditions (i.e., workstation with single GPU NVIDIA Quadro RTX A 5000, 8 CPU cores, 16 Threads, 24 GB VRAM and 64 GB RAM, Python 3.6.8, and Tensorflow 2.3.0). Implementation-wise, we used the respective packages at their stable state in November 2021 and utilized the hardware accelerations the packages provide at this point. Considering the choice of hyperparameters, we pursued the approach of leaving the models in their default configurations or using the settings recommended by the respective authors. Further details on the implementation and hyperparameter settings are given in our full paper.
Benchmark datasets
To evaluate the models, we chose twelve datasets with corresponding prediction tasks. The datasets are summarized in Table 1. To ensure a comprehensive evaluation, we assessed the predictive performance of all models on a wide range of benchmark scenarios. That is, we chose twelve regression/classification tasks. They cover seven (binary) classification (CLS) and five regression (REG) tasks. The number of observations ranges from 205 to 103,904, and the number of predictors varies between 8 and 99 with a mixed combination of numerical and categorical features. Thus, we consider a variety of settings for assessing the models. When loading the datasets, we removed IDs and variables that cause noticeable data leakage, cleaned missing values, removed categorical features with more than 25 distinct values to reduce computational complexity as we one-hot encoded these, and converted the targets into a common format. Apart from that, we kept the datasets in their default structure without extensive pre-processing.

Table 1: Overview of used benchmark datasets for classification (CLS) and regression (REG) tasks.
Evaluation of prediction performances
We used 5-fold cross-validation to measure the out-of-sample performance on each test fold and calculated the mean and standard deviation across all values. For classification, we measured the F1-score, and for regression, we calculated the root mean square error (RMSE). In Table 2, we highlight the results of our experiments for the classification tasks. The best-performing model(s) for the respective dataset are highlighted in bold numbers. Furthermore, we underline the best-performing interpretable models. Notably, GAMI-Net, Splines, and ExNN outperform the other interpretable models mainly for the classification task. We find XGB to be the overall best black-box model.

Table 2. Predictive performance for classification tasks measured by F1-score.
The results for the regression tasks are summarized in Table 3. For this task, it turns out that EBM is highly competitive in terms of performance. It is the best interpretable model for all five datasets and even the best overall model on two datasets. XGB and RF are the best overall models three out of five times.

Table 3. Predictive performance for regression tasks measured by RMSE.
When black-box models show the best performance, we observe that the scores are very close to the intrinsically interpretable models, especially the GAMs. With some overlap, the interpretable GAMs also achieved competitive results for five out of 12 datasets. For the regression tasks, the largest difference in RMSE is 0.019 (Bike: EBM 0.06 vs. XGB 0.041), whereas, for classification, the largest difference measured by F1-score is only 0.012 (Water: GAMI-Net 0.634 vs. MLP 0.646; airline: ExNN 0.951 vs. XGB 0.963).
Evaluation of Model Interpretability
To assess the GAMs’ interpretability, we examined and compared the visual outputs of the different models. The assessment is based on the example of the adult dataset (Kohavi, 1996). It contains about 30,000 observations and 15 socio-demographic and job related features from the 1994 Census database. The prediction task is determining if a person earns more than $50,000 annually. After training all models on the entire dataset, we generated feature plots to visualize the resulting shape functions. Figure 2 summarizes exemplary plots for (a) Splines, (b) EBM, and (c) GAMINet, whereas Figure 3 shows selected excerpts for (d) NAM and (e) ExNN, respectively.
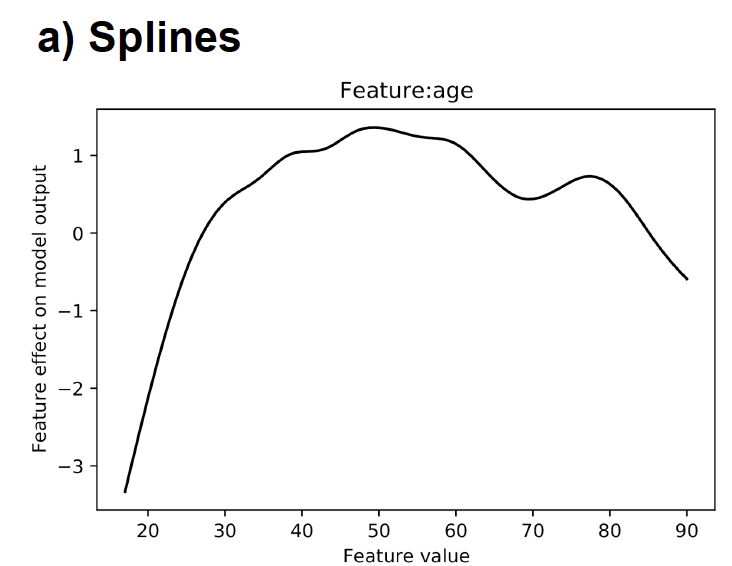
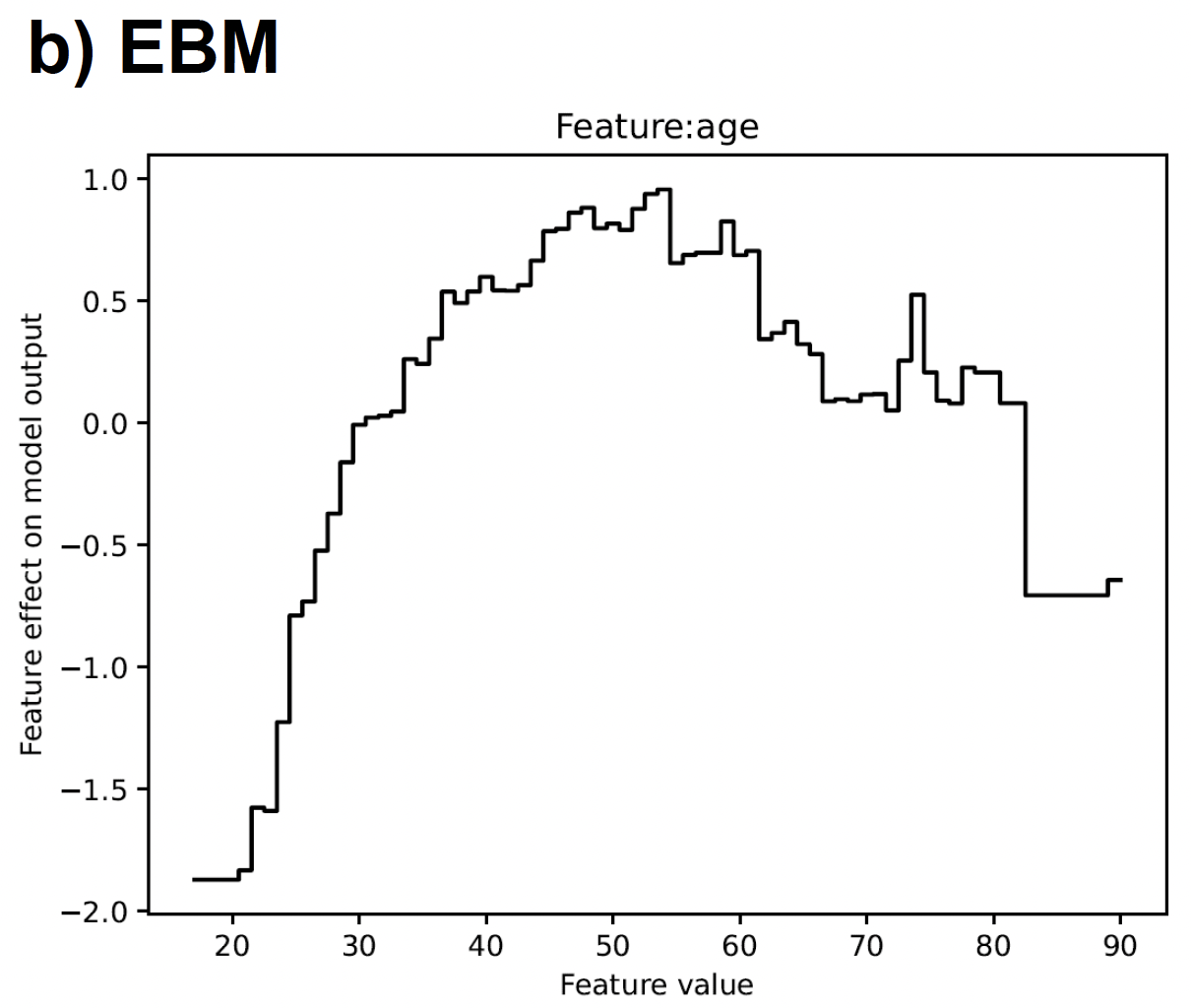

Figure 2. Excerpt of visual model output for the feature age in the adult dataset. The target variable is whether a person makes more than $50,000 annually, and the y-axis shows the contribution toward the respective class.
Focusing on the first group of models (a-c), it can be seen that all models provide the same output representation, i.e., it is displayed which impact a single feature has on the target variable (i.e., income > $50,000 annually). The x-axis represents the feature values, and the y-axis represents the impact on the target variable (i.e., positive impact for y > 0 and negative impact for y < 0). A positive impact means that this contributes toward the label defined as one. In our case, the label set is defined as y belonging in {1,0}, where class 1 represents an income higher than $50,000 and class 0 represents an income less or equal to $50,000. More illustrative, the higher the y-value of a respective feature value, the higher the contribution to the probability of the underlying sample being class 1.
The shape functions show that the different GAM versions learn different patterns and relations from the training data depending on the underlying model structure. In the case of Splines (a), for example, it is observable that the feature age has a positive effect on the target variable from a value of about 30 years and that the effect continues to increase until about 50 years. After this point, the impact slightly decreases until 70 years, where we observe another turn toward a higher effect until 80 years. The other two models capture similar effects for that feature. However, since EBM (b) relies on an ensemble of decision tree learners, the shape function is piecewise linear, resulting in a steplike curve with sharp jumps at discrete values. On this basis, more granular patterns are captured. Thus, we see more peaks with smaller ranges at certain feature values.
On the other hand, the shape plot of GAMI-Net (c) shows a smooth behavior similar to that of Splines. Overall, such learned representations can be easily understood for interpretation as they graphically reveal non-linear patterns that simple LR models cannot represent. Furthermore, in contrast to post-hoc analytical methods, the plots directly display the actual decision logic of the final models without any approximations.
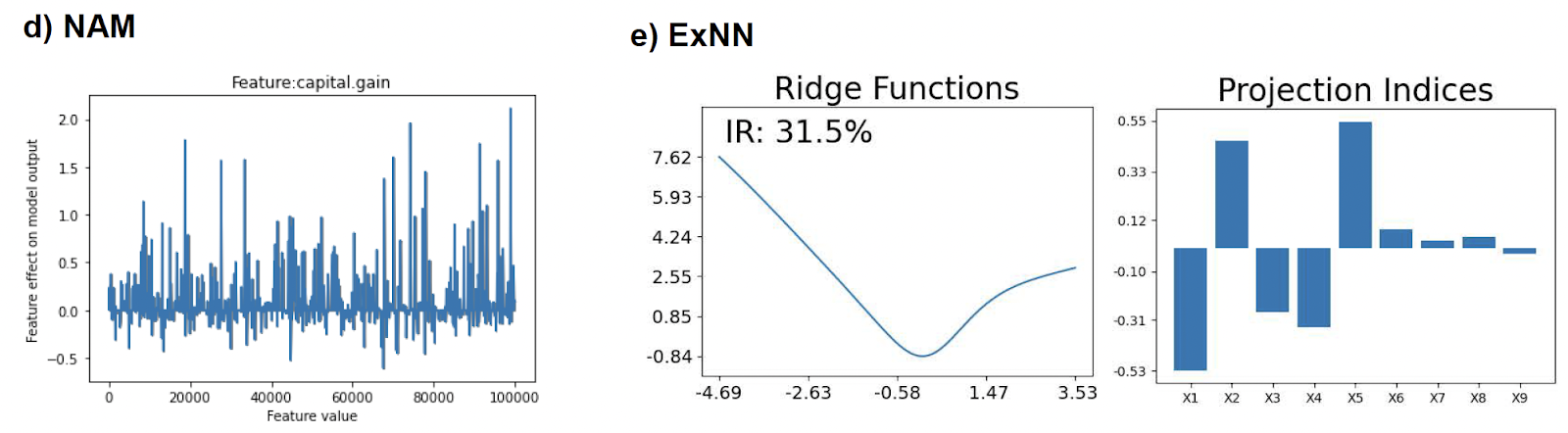
Figure 3. Excerpt of visual model output for NAM and ExNN. Since these feature lower interpretability of the shape plots, they are separated here from the previous figure.
The other two models, NAM and ExNN, were excluded from our previous considerations because they have shown fundamentally different behavior. Due to the strong overfitting effects of NAM, which we could not resolve without intensive hyperparameter tuning, the model produces extremely jagged shape functions, as shown in Figure 3 on the left side. As such, we could not generate comprehensible feature plots, which will be part of subsequent studies when tuning all models for specific data properties. The ExNN, on the other hand, is a special case as it is based on the structure of an additive index model. For the interpretation of the model, this means that not only a single feature is covered by a corresponding shape function but that the entire set of features can provide partial contributions to this shape. Figure 3 on the right side shows an example of such an output, which is hardly interpretable in a meaningful way if many features are involved.
Between the lines
Often, there is the erroneous belief that prediction accuracy must be strongly sacrificed for interpretability/transparency, which is why complex black-box models seemed to be favored over interpretable approaches during the past decade of ML research (Rudin and Radin, 2019). However, with our study, we have demonstrated the opposite, as there are seemingly innovative ML models that can combine both aspects. Consequently, we argue that advanced GAMs such as EBM or GAMI-Net should be firmly established as first-choice models in predictive modeling projects as we see their large potential for developing and applying transparent ML for high-stake decision tasks in research and industry alike.
Against this background, we also see an important role of these models in socio-technical disciplines. Due to their flexibility to capture complex patterns and their simplicity in producing easily understandable outputs, white-box models provide a technically equivalent but ethically more acceptable alternative to black-box models. In the past, we saw many examples of bias issues and fairness problems reported in ML applications. Prominent examples stem from recruiting applications where women have been discriminated against or in pretrial detention and release decisions with skewed predictions against African Americans. While detecting biases in training data is considered a tedious task, with advanced GAMs, such distortions can be better spotted using shape functions within the final model to avoid racial, sexual, and other discrimination.
References
Agarwal, R., L. Melnick, N. Frosst, X. Zhang, B. Lengerich, R. Caruana, and G. E. Hinton (2021a). “Neural additive models: Interpretable machine learning with neural nets.” arXiv preprint arXiv:2004.13912.
Hastie, T. and R. Tibshirani (1986). “Generalized Additive Models.” Statistical Science 1 (3).
Lou, Y., R. Caruana, and J. Gehrke (2012). “Intelligible models for classification and regression.” In:Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and datamining KDD ’12. Beijing, China: ACM Press, p. 150.
Nori, H., S. Jenkins, P. Koch, and R. Caruana (2019). “InterpretML: A Unified Framework for Machine Learning Interpretability.” arXiv:1909.09223 [cs, stat].
Rudin, C. (2019). “Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.” Nature Machine Intelligence 1 (5), 206–215.
Yang, Z., A. Zhang, and A. Sudjianto (2021a) “GAMINet: An explainable neural network based on generalized additive models with structured interactions.” Pattern Recognition 120, 108192.
Yang, Z., A. Zhang, and A. Sudjianto (2021b). “Enhancing Explainability of Neural Networks Through Architecture Constraints.” IEEE Transactions on Neural Networks and Learning Systems 32 (6), 2610–2621.