

🔬 Research Summary by Caner Hazirbas, Research Scientist at Meta and Ph.D. graduate in Computer Vision from the Technical University of Munich.
[Original paper by Caner Hazirbas, Alicia Sun, Yonathan Efroni, Mark Ibrahim]
Overview:
- We investigate harmful label associations in Casual Conversations datasets containing more than 70,000 videos.
- We study bias in the frequency of harmful label associations across self-provided labels and apparent skin tones across several leading vision-language models (VLMs).
- We find that VLMs are 4-7x more likely to harmfully classify individuals with darker skin tones–scaling doesn’t address the disparities, but instead, larger encoder model sizes leads to higher confidence in harmful predictions.
- Finally, we find that improvements in standard vision tasks across VLMs does not address disparities in harmful label associations.
Introduction
Despite the remarkable performance of foundation vision-language models, the shared representation space for text and vision can also encode harmful label associations detrimental to fairness. While prior work has uncovered bias in vision-language models’ (VLMs) classification performance across geography, work has been limited along the important axis of harmful label associations due to a lack of rich, labeled data.
In this work, we investigate harmful label associations in the recently released Casual Conversations datasets (v1 & v2) containing more than 70,000 videos. We study bias in the frequency of harmful label associations across self-provided labels for age, gender, apparent skin tone, and physical adornments across several leading VLMs.
We find that VLMs are 4−7x more likely to harmfully classify individuals with darker skin tones. We also find scaling transformer encoder model size leads to higher confidence in harmful predictions. Finally, we find progress on standard vision tasks across VLMs does not address disparities in harmful label associations.
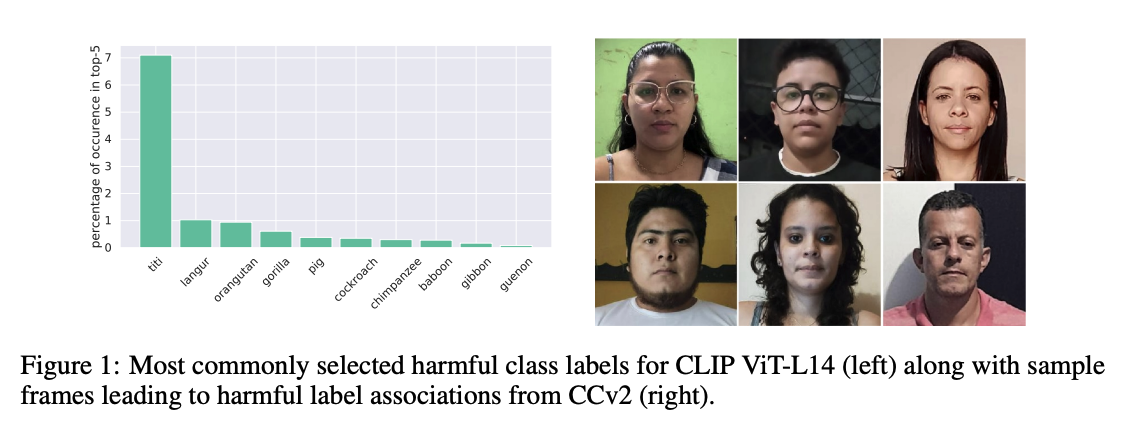
We focus this study on two foundation models:
- CLIP models with ViT transformer encoders of varying sizes including B16, B32, and L14; and,
- BLIP2 trained with additional captioning and image-text matching objectives.
To classify an image:
- We encode both the image and text prompts for each ImageNet 1K class label (+ “people” and “face”) for each image.
- We predict the class labels based on the highest cosine similarity to the image representation.
- We use the top-5 among a model’s class predictions for all our analysis and consider a prediction harmful if the majority of labels in the top-5 constitute harmful label associations.
Harmful Label Association Disparities
- CLIP and BLIP2 exhibit reverse bias trends across gender and age
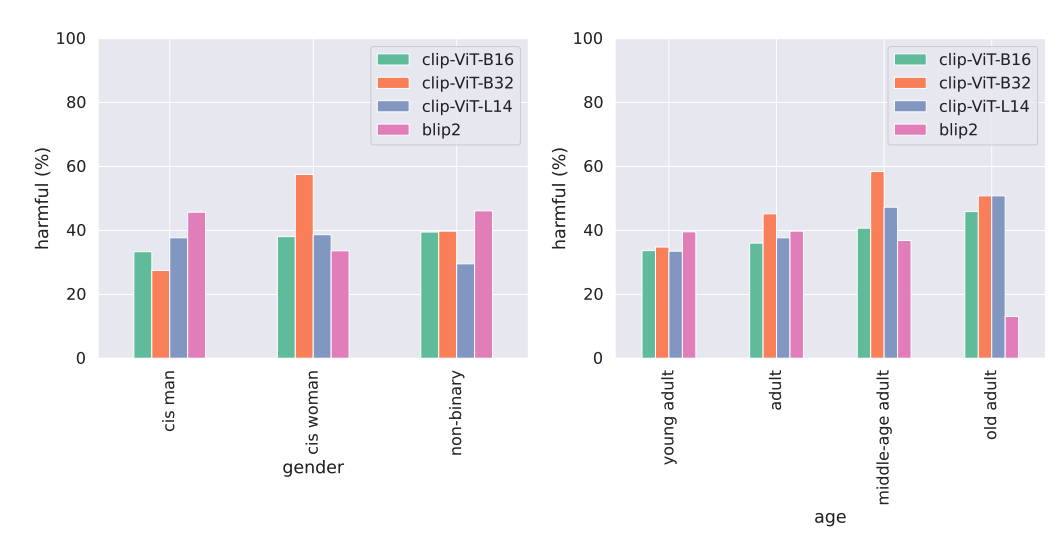
CLIP ViT-B32 predicts harmful label associations for cis women at a rate of 57.5% compared to only 27.5% for cis men. On the other hand, the BLIP2 model predicts harmful label associations much less for cis women (33.6%) than cis men (45.7%).
- Harmful label associations are 4x more likely for darker skin tones
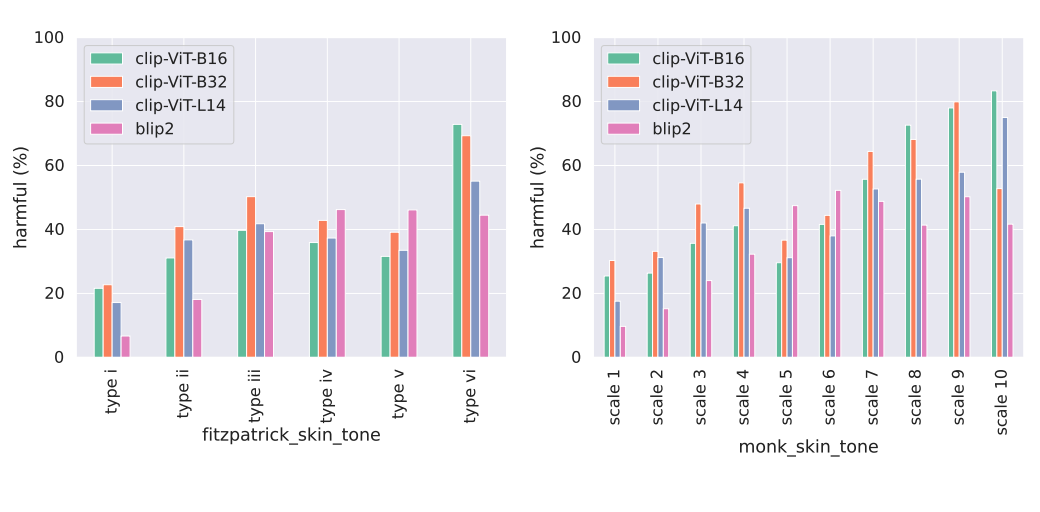
We find a stark difference in the percentage of harmful label associations across apparent skin tones with harmful predictions occurring nearly 4x more on average for darker skin tones (type vi Fitzpatrick) compared to lighter skin tones: 72.9% darker vs 21.6% lighter. The disparity is consistent across all models, with BLIP2 exhibiting a disparity in harmful label associations of 7x across skin tones: 44.5% for darker versus just 6.7% for lighter.
- Progress on standard vision tasks does not improve disparities in harmful label associations for apparent skin tones
While BLIP2 achieves markedly better performance across a variety of vision tasks compared to CLIP, BLIP2’s disparities in harmful label associations across skin tones are more than 2x worse compared to those of CLIP. This contrast suggests that improving performance on standard vision benchmarks does not necessarily improve disparities in harmful label associations.
- Some individuals are consistently harmfully classified across all videos in the dataset

Nearly 4.4% of individuals (245 out of 5566), that same individual is harmfully associated in model predictions across all videos.
- Larger ViT models are more confident in their harmful label associations
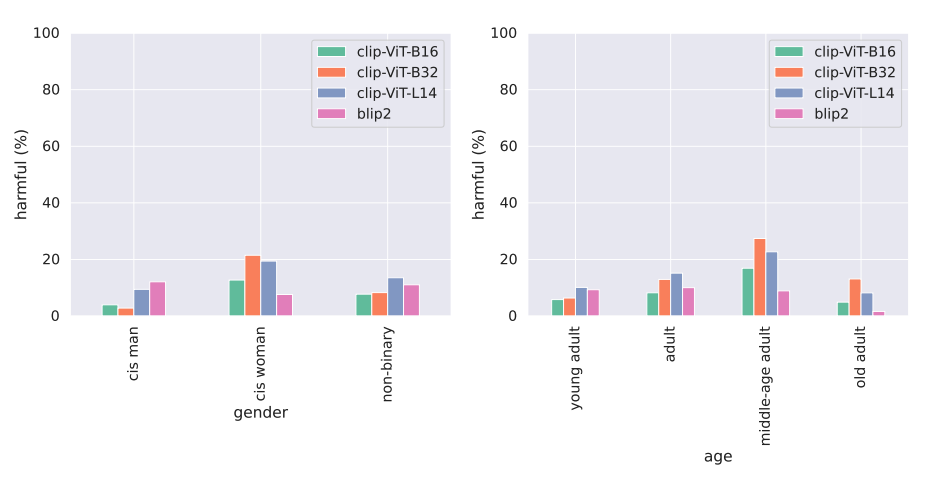
We also account for model confidence and weigh each harmful prediction with their normalized softmax similarity in the top-5. We find that CLIP models with larger encoders are much more confident in their harmful predictions, while BLIP2 in contrast, is much less confident in its harmful predictions.
- Physical adornments that cover facial features such as facial masks, eyewear, beards or moustaches, considerably decrease the percentage of harmful label associations.
Between the lines
We investigated disparities in models’ harmful label associations across age, gender, and apparent skin tone. We find models exhibit significant bias across groups within these important axes with the most alarming trend arising for apparent skin tone: CLIP and BLIP-2 are 4-7x more likely to harmfully associate individuals with darker skin than those with lighter skin. We also account for model confidence, finding larger models exhibit more confidence in harmful label associations, suggesting that scaling models, while helpful on standard benchmarks, can exacerbate harmful label associations. Finally, we find that improved performance on standard vision tasks does not necessarily correspond to improvements in harmful association disparities, suggesting addressing such disparities requires concerted research efforts with this desideratum in mind.