


🔬 Research Summary by Lin Guan, a Ph.D. student at the School of Computing and Augmented Intelligence at Arizona State University, working at the Yochan Lab (AI Lab) under the supervision of Dr. Subbarao Kambhampati.
[Original paper by Lin Guan, Karthik Valmeekam, and Subbarao Kambhampati]
Overview: Reinforcement learning or reward learning from human feedback (e.g., preferences) is a powerful tool for humans to advise or control AI agents. Unfortunately, it is also expensive since it usually requires a prohibitively large number of human preference labels. In this paper, we go beyond binary preference labels and introduce Relative Behavioral Attributes, which allow humans to efficiently tweak the agent’s behavior through judicious use of symbolic concepts (e.g., increasing the softness or speed of the agent’s movement).
Introduction
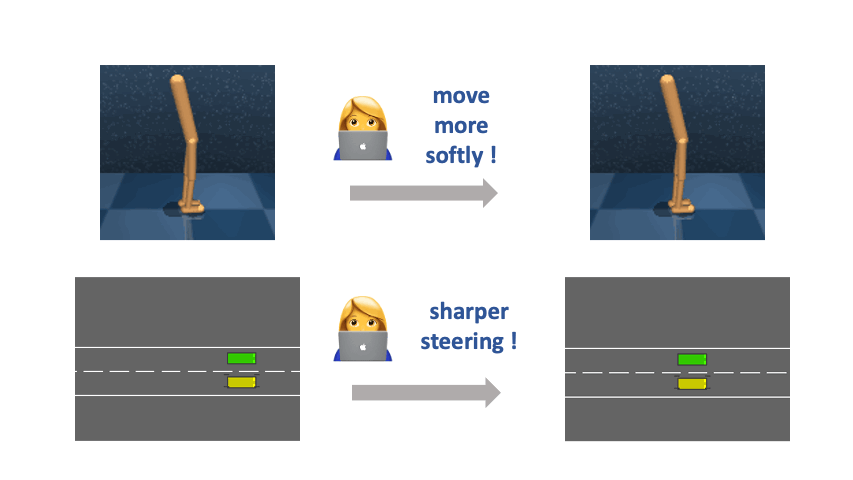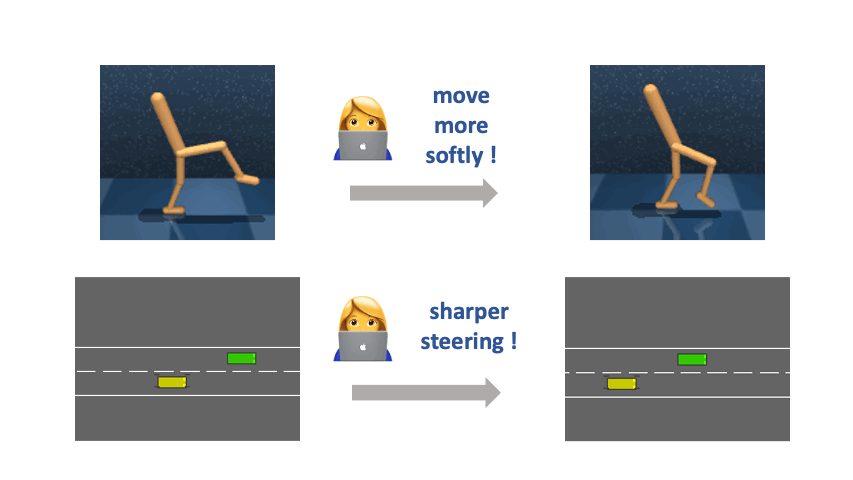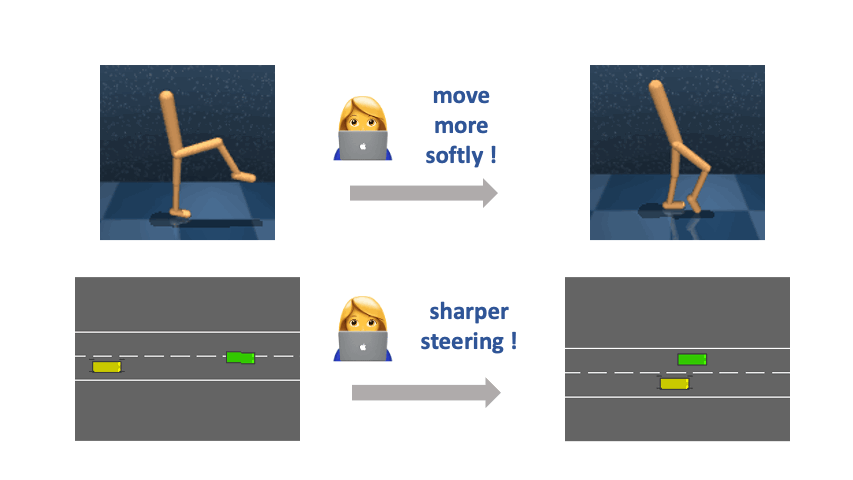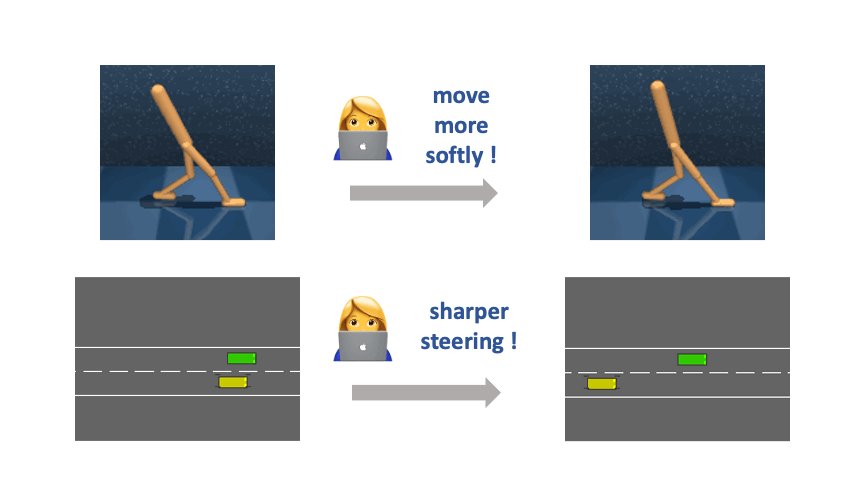
A central problem in building versatile intelligent agents is specifying and customizing agent behaviors. Interactive reward learning from trajectory comparisons (also known as reinforcement learning from human feedback or RLHF) is one way to allow humans to convey their objectives by expressing preferences over short clips of agent behaviors. The most significant advantage of RLHF is that it can be used in tacit-knowledge tasks (e.g., to define specific motion styles of a robot or to assess the quality of natural-language summaries generated by a summarization model) wherein constructing closed-form symbolic reward functions is infeasible. However, due to the limited information a binary label can carry, RLHF is a highly impoverished way for end users to communicate their objectives.
Restricting human feedback to binary comparisons can sometimes be unnecessarily inefficient because, in many real-world scenarios, users know how the agent should change its behavior along meaningful axes to fulfill their underlying purpose better, even if a closed-form symbolic specification is infeasible. Hence, we propose a new paradigm of reward specification supported by Relative Behavioral Attributes (RBA), aiming to enable end users to semantically control the relative strength of the presence of some properties in complex agent behaviors such as decreasing the “step size” or increasing the “movement softness.” We demonstrate that in multiple continuous control tasks, with learned RBAs, users can obtain desired agent behaviors with over an order of magnitude fewer human labels than the RLHF baseline.
Key Insights
The Overall Framework
The idea of RBA is relatively straightforward — our goal is to construct a single parametric reward function that takes attribute-level human feedback as input. Then by optimizing the reward, the intelligent agent can adjust its behavior in the specified direction. Such an attribute-parameterized reward function is essentially learning a family of rewards corresponding to behaviors with diverse attribute strengths. In our paper, we present two computational frameworks to realize the functionalities of RBA.
RBA is intended to bring the best of closed-form symbolic specification and pairwise trajectory comparison (i.e., RLHF) approaches. For one, similar to symbolic specification, RBA offers a semantically richer and more natural mode of communication, such that the hypothesis space of user intents or preferences can be significantly reduced each time the system receives attribute-level feedback from the user, thereby improving the overall feedback complexity significantly. Moreover, behavioral attributes, as a shared symbolic vocabulary between humans and inscrutable reward models, can be reused to serve future users and support diverse objectives. This is also an advantage over the original single-purpose or user-specific RLHF.
On the other hand, our framework is similar to RLHF in that neither requires the users to give an exact closed-form description of the task. Also, we both employ a single parametric network to encode all the task knowledge. The difference, however, is that our model not only encodes the tacit knowledge (e.g., how a robot can walk naturally with the constraints of softness and step size) but also allows end users to set the explicit parts through symbolic feedback.
Constructing the Attribute-Parameterized Reward & Interacting with End Users
Unlike the original RLHF, our framework distinguishes between the agent builders (engineers) and the end users. Accordingly, it involves two phases. In the first phase, the agent builders provide annotated training samples to construct the reward function. Here, we assume the agent builders have access to an unlabelled offline behavior dataset demonstrating different ways to carry out a task. There are many publicly accessible behavior corpora, such as the Waymo Open Dataset for autonomous driving tasks and large-scale motion clip data for character control (Peng et al., 2018a). For simplicity, we omit the details of the training sample format and the underlying network architectures. But in general, labeled training samples contain multiple ordered sequences of trajectories, and the orderings are determined by the strength of different attributes in each trajectory. An attribute-parameterized reward model is supposed to capture these attribute-conditioned orderings and to produce behaviors with diverse attribute strengths according to feedback from the end users.
Once an attribute-parameterized reward is learned, in the second phase, any incoming new users can leverage it to personalize the agent behavior through multiple rounds of a query. In each round of interaction, the agent presents the user with a trajectory that optimizes the current reward. The user then provides feedback on whether the current behavior is desirable. If unsatisfied, the user can also express their intent to increase or decrease the strength of specific attributes. The agent will then adjust the input parameters of the reward function based on the collected feedback. This human-agent interaction process repeats until the user is satisfied with the latest agent behavior.
We verified the effectiveness of our framework on four tasks with nine different behavioral attributes, showing that once the attributes are learned, end users can produce desirable agent behaviors relatively effortlessly by providing feedback just around ten times. This is over an order of magnitude less than that required by the RLHF baseline.
Between the lines
RLHF is clearly an essential technology for building advisable and personalizable AI models. However, there is still a long way to go to make it more affordable for small businesses or individuals. Our research lab has always believed that the way to economize RLHF systems should be multi-modal, ideally at the concepts or language level. Before this paper, we explored augmenting binary feedback with visual explanation (Guan et al., 2021) and argued for building a symbolic lingua franca (Kambhampati et al., 2022). As argued by (Kambhampati 2021), enabling users to specify their preferences in terms of symbols meaningful to them can also improve interpretability and reduce unintentional mislearning, thereby reducing the propagation of unintended biases. In the future, we aim to further enhance the data complexity of RBAs, especially in terms of reducing the annotation efforts needed from the agent builders. We also plan to explore the applications of RBAs in domains other than continuous control.