


🔬 Research Summary by Carlos Mougan, a Ph.D. candidate at the University of Southampton within the Marie Sklodowska-Curie ITN of NoBias.
[Original paper by Carlos Mougan, Jose M. Alvarez, Gourab K Patro, Salvatore Ruggieri and Steffen Staab]
Overview: Protected attributes (such as gender, religion, or race) are often presented as categorical features that need to be encoded before feeding them into an ML algorithm. Encoding these attributes is paramount as they determine the way the algorithm will learn from the data. Categorical feature encoding has a direct impact on the model performance and fairness. In this work, we investigate the accuracy and fairness implications of the two most well-known encoders: one-hot encoding and target encoding.
Introduction
Sensitive attributes are central to fairness and so are their handling throughout the machine learning pipeline. Many machine learning algorithms require categorical attributes to be suitably encoded as numerical data before being fed to algorithms.
What are the implications of encoding categorical protected attributes?
In previous fairness works, the presence of sensitive attributes is assumed, and so is their feature encoding. Given the range of available categorical encoding methods and the fact that they often must deal with sensitive attributes, we believe this first study on the subject to be highly relevant to the fair machine learning community.
What encoding method is best in terms of fairness? Can we improve fairness with encoding hyperparameters? Does having a fair model imply having a less performant ML model?
Key Insights
Types of induced bias
Two types bias are induced when encoding categorical protected attributes, to illustrate this types of induced bias we use the famous Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) dataset:
- Irreducible bias: The primary problem of unfairness is acquired from the use of protected attributes. It refers to (direct) group discrimination arising from the categorization of groups into labels: more data about the compared groups do not reduce this type of bias. In the COMPAS dataset, criminal ethnicity was paramount when determining recidivism scores; the numerical encoding of large ethnicity groups such as African-Americans or Caucasian may lead to discrimination, which is an unfair effect coming from the irreducible bias.
- Reducible bias: arises due to the variance when encoding groups that have a small statistical representation, sometimes even only very few instances of the group. Reducible bias can be found and introduced when encoding the ethnicity category Arabic, which is rarely represented in the data, provoking a large sampling variance that ends in an almost random and unrealistic encoding.
Encoding methods
Handling categorical features is a common problem in machine learning, given that many algorithms needs to be fed with numerical data. We review two of the most well-known traditional methods:
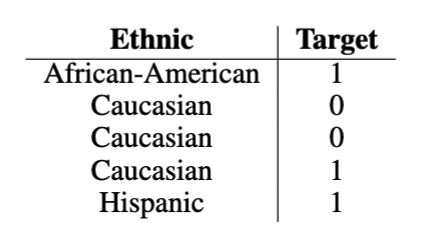
An illustrative example of a feature that need to be encoded
- One hot encoding: Is the most established encoding method for categorical features, is also the default method within the fairness literature. This encoding method constructs orthogonal and equidistant vectors for each category.
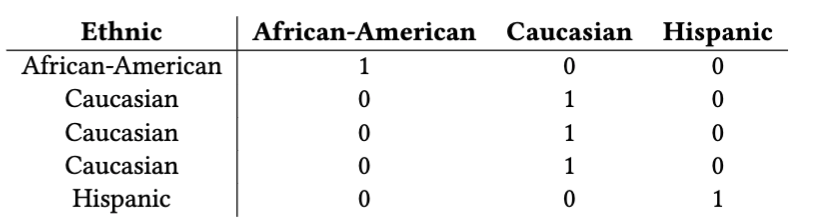
One Hot Encoding over illustrative example
- Target Encoding: categorical features are replaced with the mean target value of each respective category. This technique handles high cardinality categorical data and categories are ordered. The main drawback of target encoding appears when categories with few samples are replaced by values close to the desired target. This introduces bias to the model as it over-trusts the target encoded feature and makes the model prone to overfitting and reducible bias.
Furthermore, this type of encoding allows a regularization hyperparameter of adding Gaussian noise to the category.
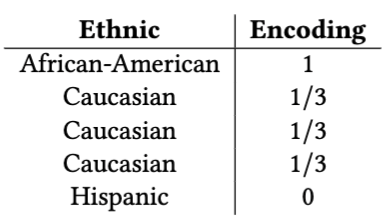
Target Encoding over illustrative example.
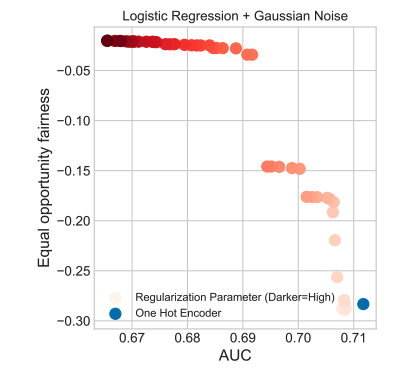
Figure: Comparing one-hot encoding and target encoding regularization (Gaussian noise) for the Logistic Regression over COMPAS dataset. The protected group is African-American. The reference group is Caucasian. Red dots regard different regularization parameters: the darker the red the higher the regularization. Blue dot regards the one-hot encoding.
In the above experiment, we showed that the most used categorical encoding method in the fair machine learning literature, one-hot encoding, discriminates more in terms of equal opportunity fairness than target encoding. However, target encoding shows promising results. Target encoding using Gaussian regularization show improvements under the presence of both types of biases, with the risk of a noticeable loss of model performance in the case of over-parametrization.
Between the lines
In recent years we have seen algorithmic methods aiming to improve fairness in data-driven systems from many perspectives: data collection, pre-processing, in-processing, and post-processing steps. In this work, we have focused on how the encoding of categorical attributes (a common pre-processing step) can reconcile model quality and fairness.
A common underpinning of much of the work in fair ML is the assumption that trade-offs between equity and accuracy may necessitate complex methods or difficult policy choices [Rodolfa et al.]
Since target encoding with regularization is easy to perform and does not require significant changes to the machine learning models, it can be explored in the future as a suitable complementary for in-processing methods in fair machine learning.
Acknowledgments
This work has received funding from the European Union’s Horizon 2020 research and innovation program under Marie Sklodowska-Curie Actions (grant agreement number 860630) for the project ‘’NoBIAS – Artificial Intelligence without Bias’’
Disclaimer
This work reflects only the authors’ views and the European Research Executive Agency (REA) is not responsible for any use that may be made of the information it contains.