


🔬 Research Summary by Bang An, a Ph.D. student at the University of Maryland, College Park, specializing in trustworthy machine learning.
[Original paper by Bang An, Zora Che, Mucong Ding, and Furong Huang]
Overview: This paper addresses the issue of fairness violations in machine learning models when they are deployed in environments different from their training grounds. A practical algorithm with fair consistency regularization as the key component is proposed to ensure model fairness under distribution shifts. Our work is published in NeurIPS 2022.
Introduction
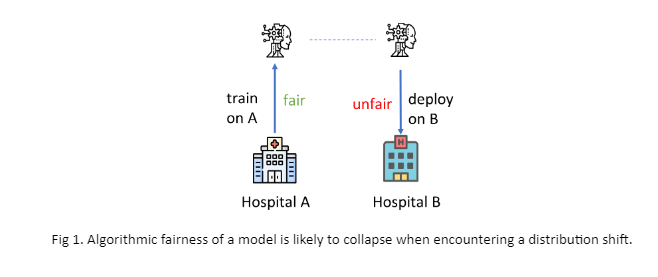
The increasing reliance on ML models in high-stakes tasks has raised a major concern about fairness violations. Although there has been a surge of work that improves algorithmic fairness, most are under the assumption of an identical training and test distribution. In many real-world applications, however, such an assumption is often violated as previously trained fair models are often deployed in a different environment, and fairness collapse has been observed in some recent work. For example, (Schrouff et al., 2022) found that a model that performs fairly according to the metric evaluated in “Hospital A” shows unfairness when applied to “Hospital B.” In this paper, we study how to maintain fairness under distribution shifts.
Key Insights
Research Problem: Transferring Fairness under Distribution Shifts
In this paper, we consider the case where we have labeled data in the source domain and unlabeled data in the target domain. We can train a fair model with the labeled source data with existing methods such as adversarial learning (Madras et al., 2018). However, we observe that the model is no longer fair in the target domain. We investigate how to adapt the fair source model to a target domain with the goal of achieving both accuracy and fairness in both domains.
What are Distribution Shifts?
We characterize distribution shifts by assuming two domains share the same underlying data generation process where data is generated from a set of latent factors with a fixed generative model, and the shift is caused by the shift of the marginal distribution of some factors. We categorize distribution shifts into three types:
1) Domain shift, where source and target distributions comprise data from related but distinct domains (e.g., train a model in hospital A but test it in hospital B).
2) Subpopulation shift, where two domains overlap, but relative proportions of subpopulations differ (e.g., the proportion of female candidates increases at test time).
3) Hybrid shift, where domain shift and subpopulation shift happen simultaneously.
We find domain shift more challenging for transferring fairness since the model’s performance is unpredictable in unseen domains. Our analysis suggests we encourage consistent fairness under different factor values.
Our Approach: A Self-training Method with Fair Consistency Regularization
We draw inspiration from recent progress on self-training in transferring accuracy under domain shifts (Wei et al., 2020). As illustrated in Fig 2, we suppose source and target domains are faces from two different datasets, and image transformations (e.g., illumination change) can connect domains. Existing works have shown that consistency regularization, which encourages consistent predictions under transformations of the same input, can propagate labels from source to target, thus transferring accuracy. However, they do not consider fairness.
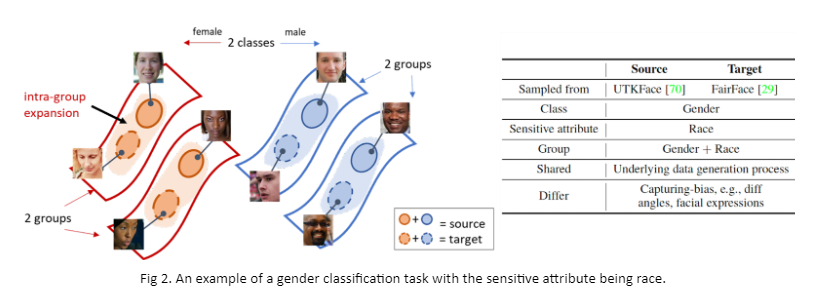
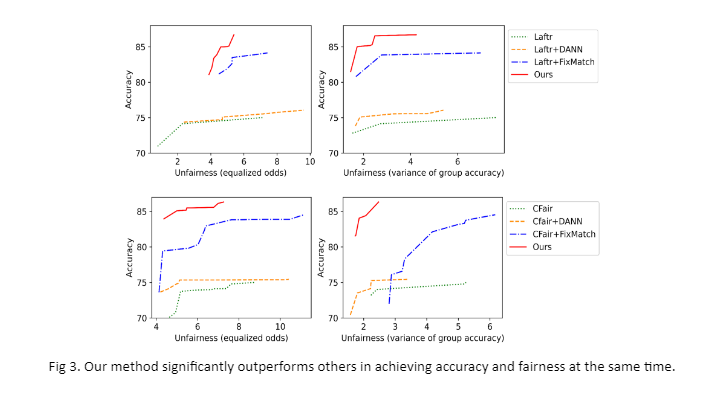
Taking demography into consideration, we propose fair consistency regularization. Specifically, we encourage similar consistency in different groups. By reweighting the consistency loss of each group dynamically according to the model’s performance, the algorithm encourages the model to pay more attention to the high-error group while training. Our method results in a model that is fair in source and has similar consistency across groups. It directly results in similar accuracy across groups in the target domain so that we can transfer fairness. We evaluate our method under different types of distribution shifts with the synthetic and real datasets. For example, Fig 3 shows that our method significantly outperforms others in achieving accuracy and fairness simultaneously.
Between the lines
We investigate an important but less explored real-world problem. Our algorithm has the potential to greatly improve the fairness of machine learning models, especially when they are deployed in environments different from their training grounds. However, like other self-training methods, one limitation of our method is the reliance on a well-defined data transformation set. Future work will relax this limitation for application to more real-world problems.