


✍️ Original article by Abhinav Raghunathan, the creator of EAIDB who publishes content related to ethical ML / AI from both theoretical and practical perspectives.
This article is a part of our Ethical AI Startups series that focuses on the landscape of companies attempting to solve various aspects of building ethical, safe, and inclusive AI systems.
Data is incredibly delicate. With the introduction of privacy laws and the increased costs of data breaches, companies are required to employ extremely care when handling individual data — its a liability. Add to this data quality concerns (e.g. not enough data) and data bias, and the case for startups specializing in the ethical treatment and handling of data before the AI process begins becomes clear. “Data for AI” is the first of five categories that EAIDB has identified in AI startups providing ethical services because this is where solving for data privacy, bias, and observability creates trust and transparency between an AI company and their customer base.
Companies offering ethical services in this category belong to one of three different labels: data sourcing / observability, synthetic data, or data privacy.

Distribution of subcategories in EAIDB’s “Data for AI” constituents.
Data Sourcing / Observability
The first step of implementing AI is finding the right data. Sourcing data in an ethical way is much harder than one would assume. How do you know your data hasn’t been collected from a convenience sample? How do you know your labels have been assigned in an unbiased way? Companies in this space provide ways to ensure data is sourced properly (via novel collection methods or ethical labeling solutions) or offer tools to identify data biases proactively. Observability in this context goes beyond finding anomalies or identifying individual rows that might break a pipeline — it’s about catching bias issues early. This is one of the most underdeveloped areas in the data pipeline.
Synthetic Data
The majority of EAIDB’s constituents in the “Data for AI” space are synthetic data companies. Synthetic data is essentially an acknowledgement that holding real data is more of a liability than an asset in many instances (e.g. healthcare, finance, any usage of individual data). Generating synthetic data involves identifying distributions over each variable in the dataset and their interactions between one another and creating an entirely new set that mimics these distributions. For vision datasets, this often becomes an interdisciplinary effort with intellectual representation in 3D Graphics, physics, and AI. Other approaches are GANs or statistical methods.
The end result is data that looks exactly the same to a machine learning algorithm, but no longer contains personally-identifying information (PII) or other sensitive attributes. Data breaches no longer yield information that traces back to a real individual. Datasets can also be generated in a way that decreases data bias and increases representation.
Data Privacy
This category is self-explanatory — there’s clearly a need for protecting individual privacy in data. The “privacy boom” occurred in the mid-2010s with the advent of techniques such as differential privacy in 2006 and followed the “cybersecurity boom” of the late 2000s. There are not many companies focusing solely on data privacy (outside of cybersecurity, which has many market maps of its own) but those that fit into this category target data transfer, permissions, and control.
Trends
The synthetic data market is growing, fast.
“Companies are turning away from the ‘move fast and break things’ mindset,” Fairgen CTO Nathan Cavaglione says, “we’re now in the mode of ‘move fast and just make sure not to break anything.’” The ability for synthetic data to provide privacy and (limited) bias guarantees in a way that improves AI performance is being increasingly recognized by businesses worldwide. Gartner predicts that by 2024, 60% of data used in AI will be synthetically generated.
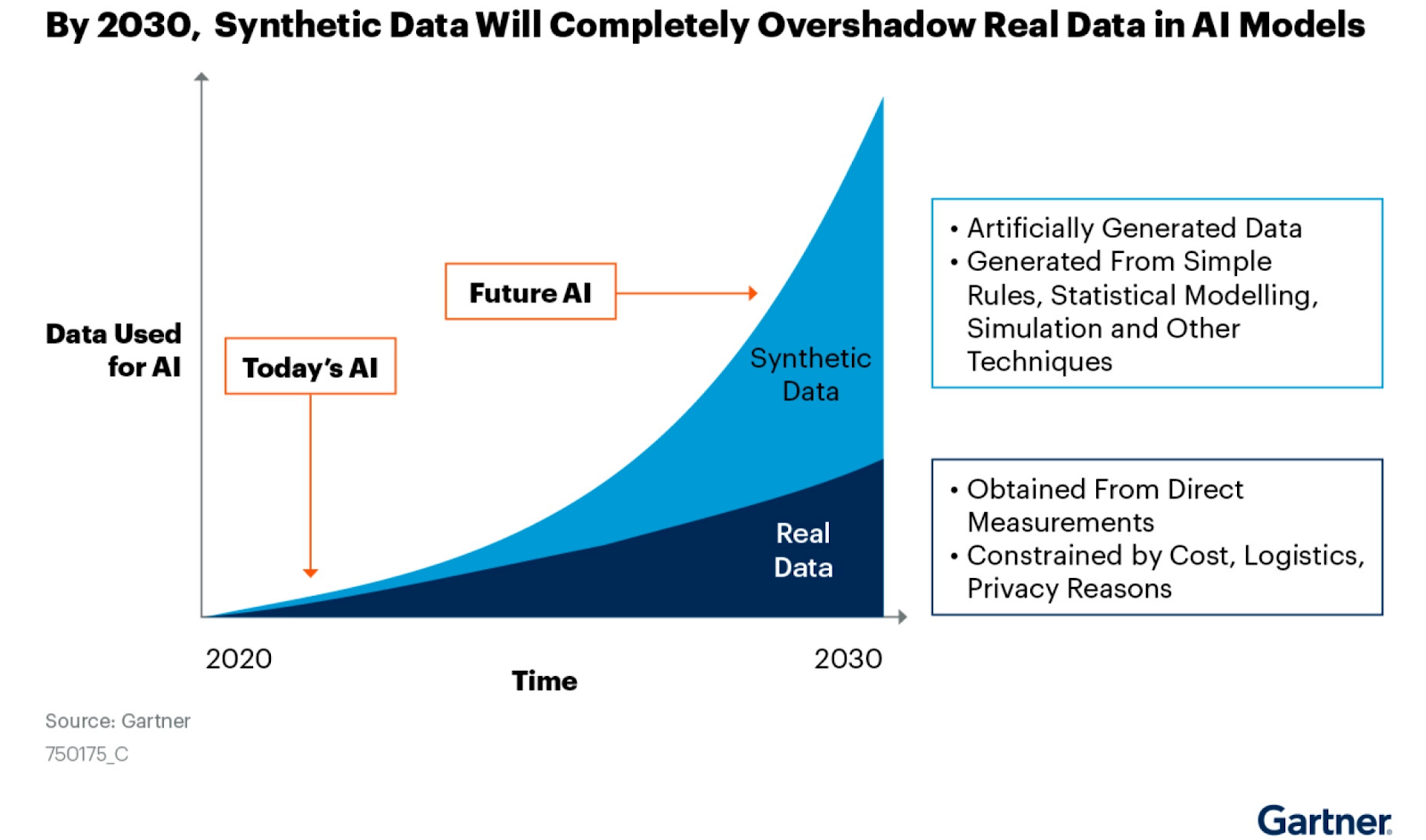
Gartner’s June 2021 report on synthetic data.
Vision dataset generation is narrowing, text / tabular data generation is widening.
Israel-based synthetic data and data debiasing solution Fairgen recently raised $2.5M in a seed round. The company focuses primarily on generating synthetic tabular data, which, as Cavaglione describes, is relatively easy to accomplish when compared to the complexity of vision datasets. Naturally, this means the standards are much higher.
Text, numbers, and distributions are easier to re-create, which is why synthetic data companies are rapidly generalizing their services across different domain spaces and data types. Fairgen intends to expand to text data.
Generating text about vehicles, for example, does not require exponentially more work than generating text about shopping. Visual data is the polar opposite — almost every specific domain brings different challenges. Israeli company Datagen tackles this problem.
Ofir Zuk, one of the founders of Datagen, maintains that “creating domain-agnostic systems is very difficult. Generating images of houses, for example, is very different from generating images of human faces.” It is much easier for vision companies to focus on a specific vertical (i.e. industrial vision sets, facial datasets, etc.), though the money really starts to flow when the same product can be used for a number of use cases. “It’s hard to reach critical mass by crawling through verticals”, Zuk says, “expanding across domains is a better way to scale.”
The control of data is shifting back to the individual.
There is a perpetually increasing concern around data privacy (spurred by recent mistreatment of individuals’ data), and the standard for customers to trust companies with their data is much higher. Naturally, the AI world mirrors this. Historically, individuals have ceded control of their own data to large companies, but now there’s a growing movement of individuals who want control of their own data. Bay Area startup Prifina attempts to store users’ wearable data in a box that only they can access. Users can run “apps” within this box (like a program that uses ML to analyze exercise routines), but data never leaves the box. Other companies like the Bangalore-based Eder Labs provide a corporate version of this, in which data is carefully permissioned down to the cell.
The need for seed data will never completely vanish.
The synthetic data scene paints a picture of data becoming a mostly machined entity. However, synthetic data (specifically tabular data) still needs to be created from a seed dataset. In the stark absence of data, synthetic generation just isn’t feasible for most scenarios. This is just one symptom of a larger fact in the data for AI industry — it takes time to put together a high-quality seed dataset upon which synthetic generation can be applied.
The process of curating a dataset today is machine-assisted (through providers like Snorkel or Scale), but is increasingly involving humans. Companies like co:census attempt to provide another option for data gathering through the use of surveys, public comments, audio transcriptions, and social media. “Humans are playing a bigger role in data collection and validation than ever before — companies are testing their data quality by having users around the world upload edge cases and adversarial examples,” Humans in the Loop CEO Iva Gumnishka says. The treatment of seed datasets has its own set of solutions that are more related to governance than generation. “Companies are now adopting approaches like data documentation, data sheets, nutrition labels, and templates for reporting properly,” Gumnishka says, “data accountability is not such a straightforward problem to solve.” Humans in the Loop, based in Bulgaria, focuses on sourcing and validating diverse datasets (always with a human in the loop) prior to use by AI.
In the modern machine learning world, approaches like GANs and complicated text-to-image algorithms (like Google’s Imagen) are still impractical for most use cases and do not provide consistent, reliable results. GANs have a tendency to “mode collapse” (i.e., high realism but extremely low image diversity) and are still heavily dependent on a seed dataset. The need for seed, Gumnishka reasons, will never quite disappear.
Barriers
Lack of uptake of synthetic data in certain industries.
As a field, synthetic data has shown a lot of promise and is rapidly being used to assuage stakeholders of privacy and data bias concerns. Europe, as the global AI policy leader, is applying regulatory pressure on companies to care about these issues as well. “Banks and telecom companies are quick to use synthetic data for AI,” Clearbox AI CEO Shalini Kurapati says, “but the one area where there is some hesitation is healthcare.” Healthcare, a safe-critical field with very strict privacy requirements, has no clear consensus on the use of sensitive data. Kurapati believes there is a lack of awareness around synthetic data that partially contributes to these issues.
Cross-culture data handling.
Data is collected differently depending on where in the world it is sourced from. Cross-cultural influences must be considered when data is collected. Unfortunately, as is the case with most subfields in AI, most companies handling data prior to ML applications are based in North America and Europe, with little to no African or South American representation. For nuanced datasets, such as facial sets in vision, cultural differences are key. Gaining diverse perspectives and making sure data is represented well in a cultural way is something no ML-assisted curation method is good at as of now. “This is exactly why we need a human in the loop,” Gumnishka says.

Regional distribution of EAIDB’s “Data for AI” constituents.
Lack of use cases outside artificial intelligence.
The barriers for growth seem to be limitations involving use cases. AI is the lifeline of synthetic data, and founders are split on whether there are sustainable use cases outside of just AI / privacy. Zuk cites synthetic media as a potential supplement for synthetic vision datasets. Some examples of existing companies in this space are Rosebud and Rephrase, though many applications of this technology come without checks for bias or discrimination.
Identifying various data biases.
The most elusive of biases is data bias. Data is formed from external methodologies and is ingrained with the circumstances of its collection. Checking for one type of bias is easy — underrepresented protected classes, for example — but building a holistic platform that looks in the data and corrects multiple types of biases is very hard. Fairgen has started work on this and has built a product that fixes demographic parity for any dataset. This is just one metric, however, where there are countless fairness metrics (often at odds with one another). Bias introduces risk, and inability to quantify “data risk” affects both founders and investors.
Being aware of the context in which the data lives.
The largest piece of the puzzle is context. The best companies can do as of now is fix “easy biases,” like under- or overrepresentation of a particular race in the data. However, understanding the context of where the data came from and what other lurking biases may be present is a ridiculously hard problem to automate because it varies on a case-by-case basis. A platform must know, for example, that crime statistics in the United States are skewed severely against racial minorities in order to understand the extent of bias in criminal justice data. Context-consciousness as a technology seems to be an almost impossible feat right now, but would be a massive step in the right, ethical direction if developed.
Outlook
Data’s meteoric rise to ubiquity has brought with it quite a few problems: privacy and bias concerns continue to radiate through the artificial intelligence community. Data observability and treatment solutions have come out of the woodwork in order to diagnose and resolve these issues. These companies have been recognized by consumers and investors alike as being part of a larger ethical data solution, and funding amounts have reflected as such.

{kind=link}
Funding rounds and timeline for EAIDB “Data for AI” constituents.
There are many views on how the ethical “Data for AI” industry might progress. Regulatory pressure, says Kurupati, will play a big role in defining companies’ motivation to treat data the way it should be treated, further fueling growth in the “Data for AI” space. Cavaglione has a longer-term thought. “There may be a time,” he says, “when companies just buy vetted synthetic data and never actually spend time making it themselves.”
Until then, bias and privacy concerns abound. There is progress being made, however, and good inputs to AI systems are the first step in assuring that its outputs are being derived and used responsibly. Data-centric AI requires that there exists a feedback loop. As Gumnishka maintains, “data needs to be continuously reviewed, refreshed, and refined during the deployment of a model — not just before it is trained.”
In the next issue of this series, we address the “ModelOps, Monitoring, & Observability” subcategory, in which startups provide services to constantly check for the effects of bad data and model bias.
EAIDB is the first publicly-available database of AI startups either providing ethical services or addressing areas of society historically riddled with bias. Learn more about the mission of EAIDB at https://eaidb.org.