


✍️ Original article by Yacine Jernite, Suhas Pai, Giada Pistilli, and Margaret Mitchell from HuggingFace.
Yacine Jernite is a researcher at Hugging Face working on exploring the social and legal context of Machine Learning systems, particularly ML and NLP datasets.
Suhas Pai is the CTO and ML Researcher at Bedrock AI and the co-chair of the Privacy working group at BigScience.
Giada Pistilli is an Ethicist at Hugging Face and a Philosophy Ph.D. candidate at Sorbonne University.
Margaret Mitchell is a researcher working on Ethical AI, currently focused on the ins and outs of ethics-informed AI development in tech.
This is part of the Social Context in LLM Research: the BigScience Approach series written by participants of several working groups of the BigScience workshop, a year-long research project focused on developing a multilingual Large Language Model in an open and collaborative fashion. In particular, this series focuses on the work done within the workshop on social, legal, and ethical aspects of LLMs through the lens of the project organization, data curation and governance, and model release strategy. For further information about the workshop and its outcomes, we encourage you to also follow:
- BigScience Blog
- BigScience Organization Twitter
- BigScience Model Training Twitter
- BigScience ACL Workshop
Introduction
Large Language Models are data-driven; i.e., the behavior of the final model (including behaviors that might run contrary to the project’s values) is highly dependent on its “training data”: the text and documents it is exposed to during its training phase. Thus, meeting the overall BigScience Workshop objectives of openness, inclusivity, and responsible research requires us to approach the ethical, legal, and governance questions raised by its data aspect with intentionality. The following blog post describes our efforts in this area.
- People: This aspect of our work focuses on direct and indirect categories of stakeholders. The direct categories include the data modelers, data owners, data custodians, and individuals directly represented in the language data we work with. The indirect stakeholders include language communities and communities represented in (or conversely absent from) the data we use to train the model.
- Ethical focus: We adopt an approach grounded in value pluralism for the overall project that explicitly asserts the need for different aspects of the work to work with different sets of (consistent) values. In the case of the data aspect, this means identifying values for sourcing and governance that explicitly acknowledge the specific needs of data in its broader context and its intrinsic rights and responsibilities.
- Legal focus: Our legal work on the data aspect has two main focuses. First, identifying legislation that is relevant to the workshop’s use of data, with a focus on data protection laws and understanding how data choices flow down to aspects of the trained model and its applications. Second, devising a flexible data agreement to facilitate data exchanges for research that respect the identified data rights.
- Governance: In order to meet all of the BigScience project’s goals of reproducibility, diversity, openness, and responsibility, we need a new data management approach between the two extrema of keeping all of the training data private or only making use of data that can be disseminated without harms. To that end, we propose an international organization for distributed data governance that enables accessible and reproducible research without compromising the data subjects’ rights.
Values of Data
Meeting the workshop’s objectives requires operationalizing its values in the training corpus collection and curation phase. Further, it should be noted that text and language are above all human-centric data, which means that they and their data subjects have inherent rights and protections, and interests that exist outside of its Machine Learning context, and which we also need to account for.
Concretely, and in the context of our goal of value pluralism (see previous blog post), this means that the data groups needed to work on outlining and implementing their own value statement to reflect both the overall project values and the latter requirements. This work led to the following list:
- Inclusion, Representation, & Non-Discrimination: Equal access to cultural resources and ability to interact with language infrastructures and technology without prejudice
- Autonomy, Consent, & Contestation: Right of individuals and communities to meaningfully control the inclusion of their language data in public resources
- Privacy: Right of individuals to control who may have access to their personal information
- Just Rewards, Licensing, & Attribution: Right to share in the financial and social benefits stemming from uses of an individual’s or communities’ language and data, including through legal controls over one’s data and the product of one’s work
- Local Knowledge & Participation: Local expressions of values and their context take precedence when making and implementing local decisions, all values and definitions are called to evolve based on actors’ needs and feedback
These values guided the efforts of project participants in their various forms of data work, which include data governance, sourcing, and final preparation.
Enabling Stakeholder Agency through Data Governance
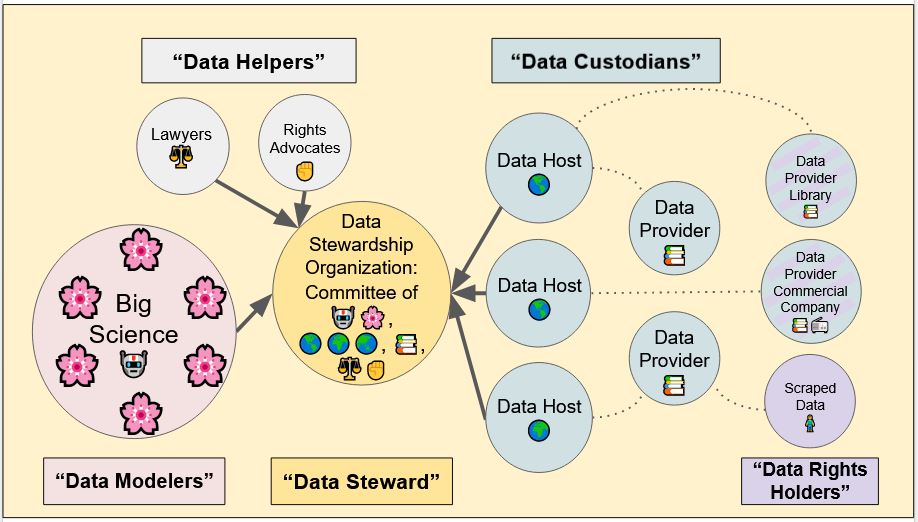
Before starting to look for or use data, we need to answer questions related to its governance. These include: what data can we use, both from a legal and value-informed perspective? How are we planning to provide transparency into the properties of the data? Will the data be disseminated in its original or processed form? And more importantly, who should be making these decisions, especially considering the international scope of the effort?
The BigScience data governance working group started working on a structure that could help address those questions in keeping with the data values outlined above. We first outlined the different roles involved in data governance, including data providers and rights holders, data custodians, modelers, and legal experts and advocates. We then proposed a structure that relies on local data hosts to centralize data from data providers in their region and support them and the researchers who want to use this data by managing access to it, providing access for subsequent projects that are compatible with the goals and values of the data rights holders, and honoring legitimate removal requests for parts of the data upon request of the latter.
We outline two salient aspects of our approach here. First, we do not equate inclusive or reproducible research with open data. On the contrary, we recognize that limiting research on language and language technology to data that can be freely disseminated introduces its own biases, and notably excludes actors and communities who want to participate in research without giving up control of their data. We enable reproducibility by promoting standardized visualizations and representations of the data that do not require dissemination, and by encouraging purpose-specific access to the data for further investigations. Second, we believe that the entity that manages the data in the long term (the data host) should belong to a region, cultural, or geopolitical entity that is close to those of the data providers and rights holders. This allows the data hosts to both better evaluate whether requests for using the data are consistent with the intent of the providers and facilitates alignment on legal rights and definitions when providers and hosts are in the same jurisdiction.
We are in the process of building up the proposed organization to make the BigScience corpus accessible after the end of the project and will be releasing the technical and organizational tools we develop to that end, including standard licensing agreements (including e.g. a data agreement to formalize relationships and reciprocal duties between data providers and data hosts), documentation of all data sources, and visualization and analysis tools for large datasets. For more information on the background, approach, and definition of this governance structure, please refer to our FAccT 2022 paper.
Data and Language Selection: Prioritizing Language Knowledge
Having an intentional governance structure allows us to start gathering text data for our corpus. At this stage, the aim is to create a collection of text sources that add up to a similar amount to those used to train other LLMs and that to the extent possible represents the diversity of use cases and contexts for which we want to make the model relevant. Given the awesome scales in question, it can be tempting to optimize the data gathering process for quantity above all, for example by starting from one very large data source such as a web crawl; however, such an approach has been criticized on several accounts, including the known and harmful selection biases it introduces, its disparate coverage of languages, and its lack of transparency and accountability. Instead, keeping with our data values, we adopted a two-step bottom-up approach to data collection that relies on the choices and expertise of native language speakers for all languages we proposed to include in the model training corpus.
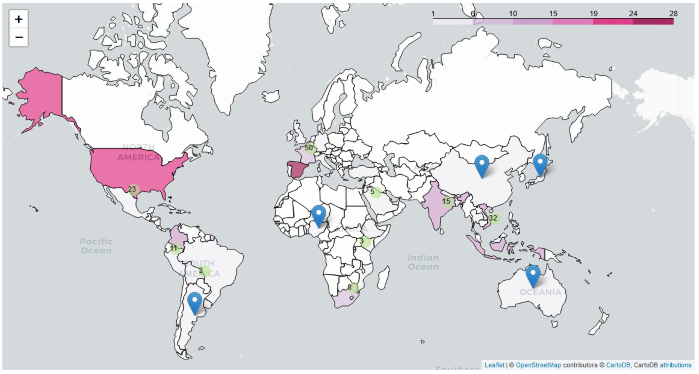
First, we built an interactive catalog and organized several events with regional ML and language technology-focused communities around the world to allow participants to share their knowledge of existing relevant language resources, including NLP datasets and primary sources such as newspapers, websites of interest, and collections of books and articles. To that end, we devised an interactive language resource catalog (with a from to add or validate an entry here) to support collaborative live knowledge-sharing events with locally-focused ML and NLP communities around the world, focusing e.g. on African language resources with Masakhane or East and South-East Asian language resources with Machine Learning Tokyo and VietAI, as well as efforts targeting Spanish sources from across Latin America and English resources from Indo-Pacific regions. You can read more about the tool and community efforts in our paper describing the approach.
After annotating and collecting the data, we then built a suite of visualization and exploration tools to gather further input from native speakers to design language-specific processing pipelines for the raw text from the identified sources and a smaller amount of additional web-crawled text. Specifically, in order to limit the risk of making assumptions that worked for English or European languages only, we built a tool to allow language speakers to choose hyper-parameters and test out various filters and organized events to gather their feedback. This process was described in more detail in a previous blog post.

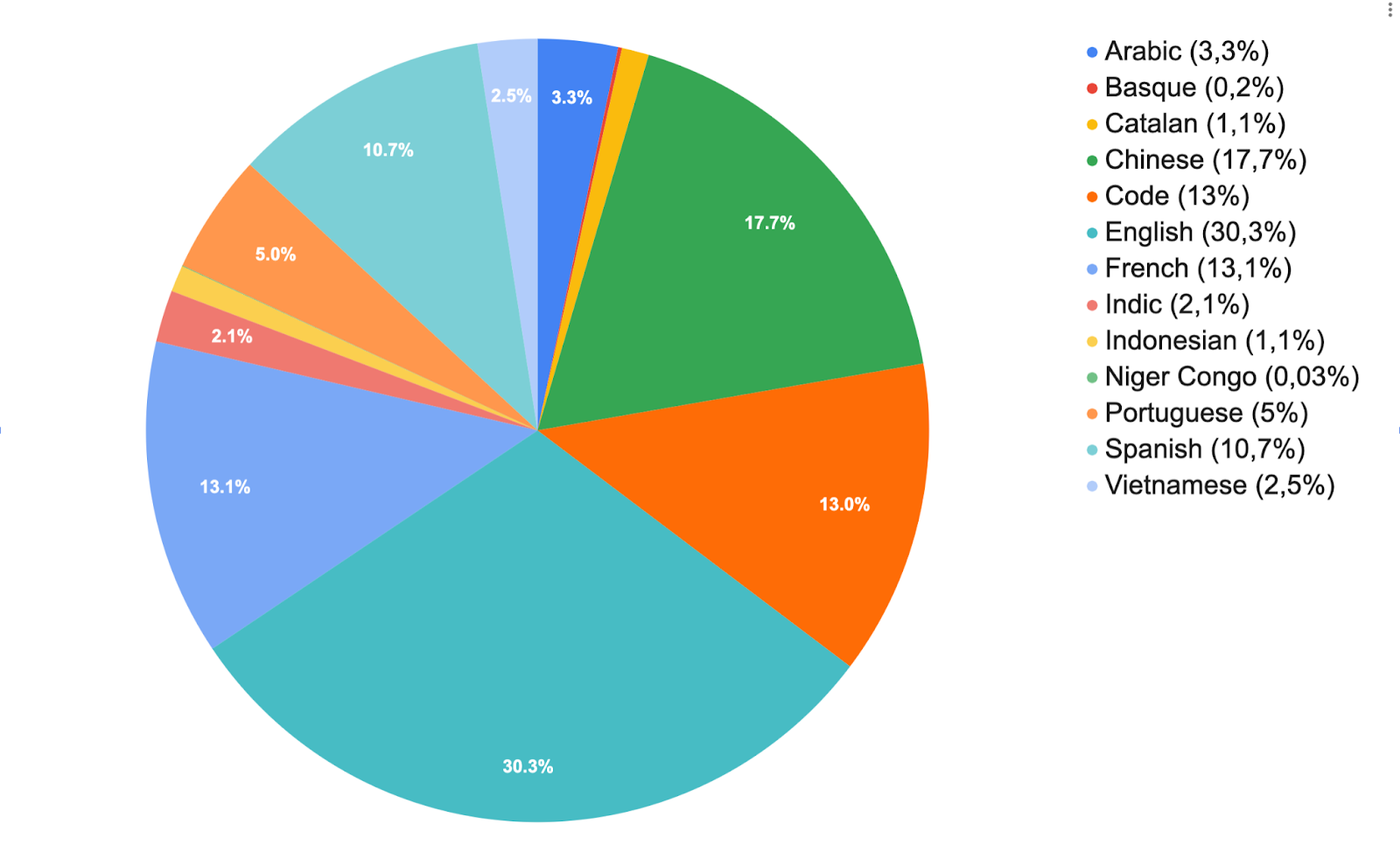
In the end, we used data from around 250 sources of variable sizes. Our approach required significant human effort to gather and process the corpus and restricted the languages covered in the project to ones to which a sufficient number of speakers managed to commit their time and energy (we ended up with a list of 46 languages, including 8 of the world’s most widely spoken languages) and was still limited to privileged varieties of the languages of interest that have the most digitized content. It also yielded a corpus with extensive source-level documentation, significant geographical and chronological coverage (depending on the languages, with some sources as old as the 13th century for Arabic and some as recent as January 2022 for French and Spanish newspapers), less reliance on selection biases that are widely considered to be a major source of harmful biases in the trained model, and prioritized the knowledge of language speakers and local stakeholders in its curation choices.
Privacy, Personal Data, and PII in Web Content
One aspect of ML training data that has been the focus of data protection regulations for decades and has received increasing attention among ML systems decelopers in recent years is the privacy of the data subjects, operationalized in particular in the form of rights of an individual to control their personal data (EU/UK) or Personal Identifying Information (PII, USA). In the data aspect of the BigScience workshop, privacy rights were the explicit focus of three of our efforts.
First, as noted above, we designed a data governance framework with the purpose of being able to honor contestation rights guaranteed by regulations such as the GDPR (e.g., requests to have one’s personal data removed from a database on the grounds of one’s right to be forgotten). Second, we developed a set of regular expressions to redact some categories or personal information from web text, and used it to replace instances of identified personal information (e.g., emails were replaced by a special PI:USER token) from the portion of our training data that came from a general web crawl (a filtered OSCAR dataset) as we thought it presented the highest privacy risk among all of our language data sources. The latter was the subject of lively conversation between members of several working groups to select which categories of information to redact depending on the precision of available identification tools, as we needed to balance the risks to data subjects with the ability of the model to learn linguistic patterns involving numbers and dates – which tested the consensus-based decision process we aimed to implement within BigScience before we eventually settled on a final set of regular expressions.
Third, in order to facilitate such decisions and make it easier for future efforts to redact personal information from text should the need arise, we also worked on developing new tools for identifying personal information in multiple languages. This project started with a two-month-long hackathon co-organized between BigScience, Ontocord, and the AISC community, bringing together 55 participants to create or annotate data for PII detection in their native languages (English, Mandarin, Arabic, Farsi, Portuguese, Yoruba, Swahili, Indonesian, and Hindi). We are in the process of designing a release strategy for this data and hope that it will help improve the performance of multilingual tools for identifying personal information so as to broaden the coverage of categories that can reliably be redacted from training data.
Conclusion and Statement of Contributions
Even more directly than the Large Language Models that are the focus of our workshop, language data itself is situated in society and needs to be handled accordingly, both within and outside of its use in training ML systems.
In line with our values and goals, this means putting language speakers at the center of the language data selection and curation process. In this way, language communities have the opportunity to be the protagonists, thus ensuring a diversity legitimized by their belonging to the cultural entities represented in the final corpus. Similarly, designing a data governance structure that upholds the agency of data providers allows them to become significant actors in shaping the technology in a way that is consistent with their interests. Throughout, our deliberations and, ultimately, the process itself were guided by the respect for the identified legal protections, the concept of privacy, and the consistency with values specified to guide our decisions and actions.
The work presented here corresponds to efforts coordinated by the BigScience Data Governance, Data Sourcing, Privacy, and Data Preparation Working Groups, and its outcomes represent the participation of both BigScience participants in these working groups and of the members of several other ML and NLP international and locally focused communities such as Masakhane, MLT, and AISC.