


Summary contributed by Sundar Narayanan, Director at Nexdigm and ethics & compliance professional.
*Authors of full paper & link at the bottom
Mini-summary:
Adversarial attacks have existed for years now. There are currently no structured legal frameworks to deal with adversarial attacks including terms of service for ML use or the regulatory framework for ML environment/ model themselves.
The paper analyses the confusing landscapes ahead for legal practitioners and the risks that are there for ML researchers in the current environment.
To drive this point home, the researchers reflect upon a specific regulation (Computer Fraud and Abuse Act) and a specific clause that defines the offence as intentional access without authorization or exceeding authorized access; obtaining any information from a protected computer; intentionally causing damage, and by knowingly transmitting a program, information, code or command.
The paper also reflects on how the courts are divided between a broad interpretation (exceeding authorized access itself is an offence) and narrow interpretation (exceeding authorized access for improper purpose).
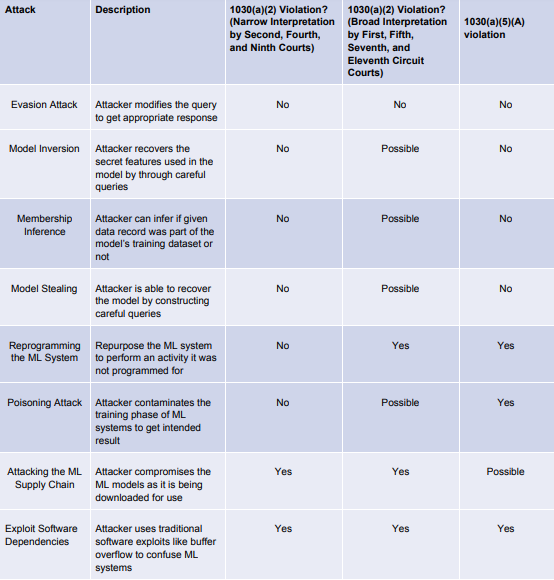
The researchers also classify the type of attacks into exploratory attacks, poisoning attacks, attack on ML environments and attack on software dependencies. The researchers conclude that in their view the Supreme Court is expected to take a narrow view and mention that the narrow view may encourage ML security researchers to pursue their efforts towards such exploits for a better robustness of the ML environments/ Models.
Full summary:
Context
- For legal practitioners, we describe the complex and confusing legal landscape of applying the CFAA to adversarial ML.
- For adversarial ML researchers, we describe the potential risks of conducting adversarial ML research.
About Computer Fraud and Abuse Act (CFAA)
- Was enacted in 1980’s but was amended multiple times. 2008 is the recent amendment.
- Has very broad definitions.
- The CFAA prohibits intentionally accessing a computer without authorization or in excess of authorization, but fails to define what “without authorization” means.
- Distribution of malicious code and denial of service attack was also included as offences.
- There was an attempt to enhance the law in 2015 under the Obama administration but this was argued to be detrimental to many of the internet activities.
- In the past, many security researchers have gotten themselves embroiled into regulatory/ enforcement tangles under CFAA (eg. Weev vs AT&T here).
Key clause considered for CFAA analysis
- Intentional Access Without or Exceeding Authorization — Section 1030(a)(2)
- Important aspects:
- Without authorization or exceeds authorized access
- Obtains any information
- On a protected computer
- Intentionally causing damage
- By knowingly transmitting a program, information, code or command
Narrow and broader interpretation of the clause
Broad interpretation: “exceed authorized access” includes accessing information on a computer system for an “improper purpose,” which usually means breaching some agreement, policy, or terms of service.
Narrow interpretation: Exceeding authorized access must be for an improper purpose for it to constitute a violation.
The research speaks about Black-box setup attacks wherein the attacker has no direct access to the training data, has no knowledge of the algorithm, and no knowledge about the features used in the algorithm.
Types of attacks:
- Exploratory attacks: Attacks that sends queries and observes data.
- Evasion attack: Tricking the ML system into misclassifying
- Model stealing: Replicate a ML model by strategically querying the model and observing the response
- Model inversion/ Membership interference: Inferring sensitive information about private training data by exploiting confidence intervals and reconstructing the features
- Reprogramming the ML system: Making the ML system do an activity that was not desired by the developer
- Poisoning attack: Attacks that taint the training data. ML models are retrained on outcomes it generates (along with human feedback in some cases) to address the shifts in data distribution. This approach could be used to poison the training data.
- Attacks on ML environment: The attacker subverts the machine learning system by tampering with the source code, build processes, or update mechanisms (e.g: Use of pre-trained models).
- Exploit software dependencies: The attacker exploits unpatched vulnerabilities in popular ML packages like numpy and tensorflow.
Assessed impacts of various types of adversarial attacks
Conclusion
The paper concludes that a narrow interpretation focused on hacking and bypassing technological barriers would be more consistent to how the Supreme Court may view the same.
The paper finally concludes that if narrow interpretation is adopted ML security researchers will be less likely chilled from conducting tests and other exploratory work on ML systems, again leading to better security in the long term.
Future research the paper opens up to:
The following are certain points of limitations in the current paper that helps in extending to future research areas. The limitations include:
- The paper looks at adversarial attack in a limited sense. For example, it does not see how the actions can be considered as a violation in general principles of law (Common Law perspective). For example, extraction of information could be tried as theft. Similarly, replication of content / model could be tried under intellectual property or other aspects from common law perspective.
- The paper is limited to select assessment of impact in light of Computer Fraud and Abuse Act. The act expects determination of intent. There are cases where intent is considered to be fraudulent or otherwise even in occasions where security researchers have identified a possible exploit.
- The paper is limited to the CFAA but there are other regulations that impact data privacy and security in general (which is the base for adversarial attack) including wiretapping, wire fraud, identity theft, access device fraud, unlawful access to stored communications, federal information security management, Gramm-Leach-Bliley, and HIPAA.
- The paper is looking at exposures from ML security attackers perspective, however, there are implications to the company whose ML security is attacked in the context of data privacy or security requirements.
- More than these, it is necessary to understand that the cases are decided based on facts and circumstances rather than a generalistic view/ interpretation of such clauses.
Original paper by Ram Shankar Siva Kumar, Jonathon Penney, Bruce Schneier, Kendra Albert: https://arxiv.org/ftp/arxiv/papers/2006/2006.16179.pdf