


🔬 Research Summary by Mingxue Xu, a second-year PhD at Imperial College London, interested in ethical and energy-efficient issues in AI systems.
[Original paper by Mingxue Xu, Tongtong Xu, and Po-Yu Chen]
Overview: There is an emerging service in the ML market offering custom training datasets for customers with budget constraints. The datasets are tailored to meet specific requirements and regulations, but customers don’t have access to the datasets except for the final ML model products. In this case, this paper provides a solution for customers to inspect the data fairness and diversity status of the inaccessible dataset.
Introduction
Are ML services products the same as software products we get used to? The answer is certainly no – an important reason is that ML services greatly depend on data-hungry and hard-to-interpret deep neural networks. Thus, its inspection process is not apparent as software. Especially for the services that access to the original training dataset is not released, it is hard to confirm if the service provider built the dataset with enough attention to issues like data diversity and fairness. At the same time, these two issues are essential to ML service pricing and compliance.
Given the ML training dataset is a private possession of the ML service provider, this work gives the first try to provide a strategy to inspect the data diversity and fairness. We formalize the inspection problem, then migrate a methodology named shadow training from the AI privacy community to our inspection problem. Assuming that the inspector can randomly sample the data entities from the open data population, we achieved a sound inspection performance in our experiments of an NLP application.
Key Insights
In the Machine Learning as a Service (MLaaS) context, our ultimate goal is to inspect data diversity and fairness in the private training set, whose access is unavailable for anyone except the service provider. Centered on this goal, the following text gives a shorthand for our work.
Why inspect?
For the private dataset in MLaaS, on the customer side, there are two issues of profit:
1. Fraud: the MLaaS provider might lie that they have the required data from the customer but, in fact, do not.
This dishonesty is difficult to detect without direct access to the training set. The performance of the ML model in the actual deployed environment is potential evidence. Still, since the data samples in the actual deployed environment do not overlap with the original training set, good ML model performance is not a sufficient condition for an honest claim by the MLaaS provider.
A model trained on a public dataset may overall outperform that on the extra-charged private training set in the actual deployment environment.
2. Compliance: there requires a low-cost measurement in terms of legal requirements (i.e., fairness). On the MLaaS provider side, fair data collection costs extra manpower and resources. However, monitoring either data collection or model production is a daunting task. And similar to the dishonest claim by the MLaaS provider, the unfairness of the training dataset is also difficult to detect through the model prediction in the actual deployed environment.
Who can inspect it?
The inspector can be the individuals/SMEs with more data and computation resources than the customer, larger enterprises with certain expertise in the customer’s business, or professional institutions authorized by the government. The inspector has the same model access as the customers.
How to inspect?
In a realistic setting, there are no exact data samples for the inspection. Thus, we take data origin [1] as an entry point. Data origins are the entities related to data generation, or in other words, “where the data is generated or what subject the data describe”.
We assume the inspector can randomly sample the data origin on the whole dataset population; thus, the sampled data origins represent the training set. Based on this assumption, we can divide the dataset-level diversity and fairness measurement into origin-level diversity and fairness measurement, which is feasible when the inspector cannot access the dataset.
After this, we empirically prove the values of origin-level diversity and fairness measurement maintained across disjointed datasets, with the assistance of the Kolmogorov–Smirnov Test in statistics and statistical sampling in quality assurance in manufacturing and service industries.
Then we should decide if the known data origins, along with their data diversity and fairness measurements, exist in the inaccessible dataset. We implement this module via shadow training in the AI privacy community, originally for membership inference problems [2]. The overview of this process is in Figure 1.
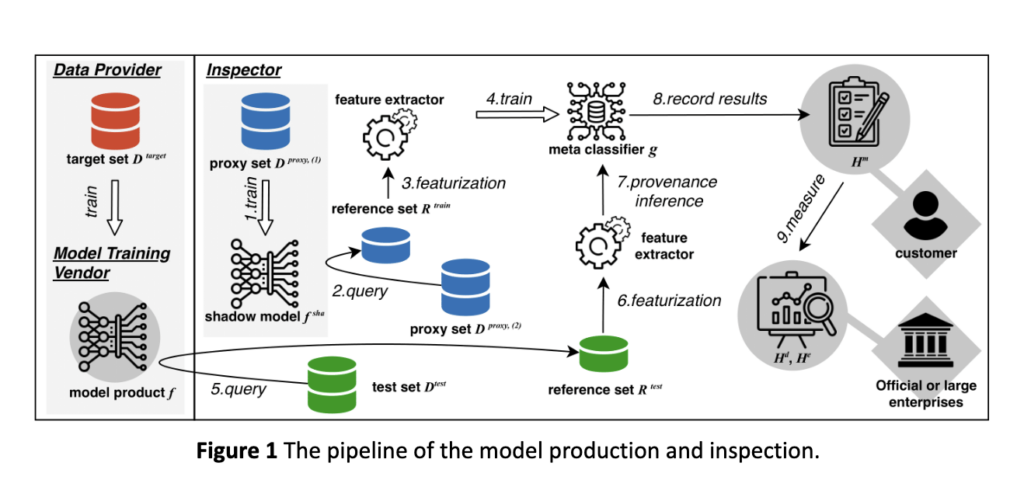
As shown in Figure 1, the inspector trains shadow models locally, which is a typical step in membership inference. We then combine multiple learning instances to extract origin-level patterns on model product output and infer the data origin in the training set. If the data origin exists, use the abovementioned two proofs to estimate the fairness and diversity measurement values in the training set.
Between the lines
With the ML market expanding to meet diverse customer requirements, it is crucial to innovate inspection processes for specific services to enhance the marketplace. This work formally defines one of these “specific services,” where the customers have a limited budget but still want to customize the training dataset of the ML product. We investigate data fairness and diversity, two important ethical and financial concerns that should be considered in upcoming ML services. Last but not least, we are also one of a few to migrate shadow training – a popular methodology in the AI privacy community, to the context of ML production (the others investigated auditing [3]).
As a first attempt, this work gives a technical solution to the problem and obtains a sound performance. However, our work has a technical limitation: the strategy is based on an assumption that the inspector can sample data and data origins from the open population or the data of the same as the training dataset. This assumption sometimes poses a high demand for inspectors and might not be easy to achieve in real-world production. It would be valuable if further research could address this limitation.
References
[1] Xu, Mingxue, and Xiang-Yang Li. “Data Provenance Inference in Machine Learning.” arXiv preprint arXiv:2211.13416 (2022).
[2] Shokri, Reza, et al. “Membership inference attacks against machine learning models.” 2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017.
[3] Congzheng Song and Vitaly Shmatikov. “Auditing Data Provenance in Text-Generation Models.” In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’19).