

🔬 Research Summary by Boris Ruf, an AI researcher at AXA, focusing on algorithmic fairness and digital sustainability.
[Original paper by Boris Ruf and Marcin Detyniecki]
Overview: Measuring the carbon footprint is crucial for making informed choices regarding carbon reduction for individuals or businesses. Recent case studies have highlighted carbon footprints for various products and services, but the underlying assumptions can be opaque due to intricate relationships. Addressing these challenges, we suggest an open and linked data model for carbon footprint scenarios, enhancing data quality and transparency by design. We exemplify our concept through a web-based data interpreter prototype.
Introduction
The recent surge in natural disasters has heightened global awareness of the ongoing climate crisis, prompting society to take action. While reducing greenhouse gases is recognized as vital for mitigating climate change, determining individual reduction potential remains complex due to hidden emissions and a lack of clear comparisons. Some widely publicized claims about the environmental impact of common activities, such as email and Netflix usage, have proven to be flawed due to inaccuracies in their analysis. These incidents highlight the importance of transparent methodologies for evaluating and discussing carbon footprint scenarios.
The need for comparative scenarios becomes evident when we consider the intangible nature of carbon emissions, particularly in the realm of digital services. Robust comparative scenarios are essential to address this issue and provide a clear understanding of our environmental impact. These scenarios can help us make informed choices and take meaningful steps toward reducing our carbon footprint, even in the digital age.
To support this cause, we propose a new, simple data model tailored to carbon footprint scenarios. Its modular, open, and collaborative design is intended to enhance data quality and transparency in the field of carbon footprint quantification. We illustrate the implementation of our concept by reproducing three widely recognized carbon footprint estimates for ChatGPT and making them accessible via an interactive web-based data interpreter.
Key insights
It’s a matter of context
Over the last years, an array of carbon footprint calculators has been introduced, exhibiting significant variations in complexity and user engagement methods. These tools encompass a broad spectrum of functionalities, spanning from simple spreadsheet data entry to complex mobile applications featuring multi-step procedures. They cater to diverse activities and industries, from personal activity tracking to specialized sectors like construction and supply chain management and even digital services such as cloud storage and AI. Notable contemporary carbon calculators for individuals include the Global Footprint Network’s Footprint Calculator, the United Nations’ UN Carbon Footprint Calculator, and the WWF Footprint Calculator, each designed for specific applications and regions.
However, multiple research studies have emphasized the lack of methodological consistency and transparency among many tools of this kind. Moreover, scenario-specific factors can exhibit substantial variations depending on the context. For example, when comparing the carbon footprint of taking a flight to driving a car, the type of car and its fuel consumption significantly affect the emissions produced. Similarly, when it comes to electric vehicles, the source of electricity used for charging plays a critical role. In different regions or countries, the carbon intensity of the local power grid can vary substantially. For instance, in 2021, the carbon intensity of the French power sector was estimated at 58 grams of CO₂ per kilowatt-hour, while in Germany, it was significantly higher at 349 grams. As a result, these individual factors can strongly influence outcomes and are, therefore, often critical to understanding the environmental impacts of various activities.
The data model
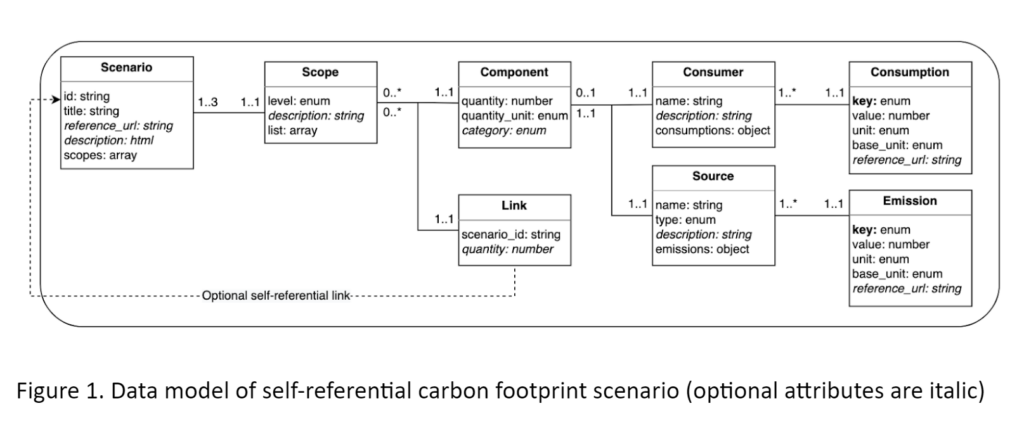
In response to this challenge, we propose a universal data model for carbon footprint scenarios that aims to enhance the accessibility and practicality of carbon footprint data. It is designed to be open, linked, and modular, simplifying the sharing and reutilization of data. The data model is represented in JSON format. A schema can be found in Figure 1. The boxes represent the entities, each featuring a set of attributes and corresponding data types. They include Scenario, Scope, Component, Link, Source, Emission, Consumer, and Consumption. The connectors specify the relationships between the entities. Numbers on the connectors express the minimum and maximum cardinalities of the relationship. We refer interested readers to the paper for more details on the data model.
The data interpreter
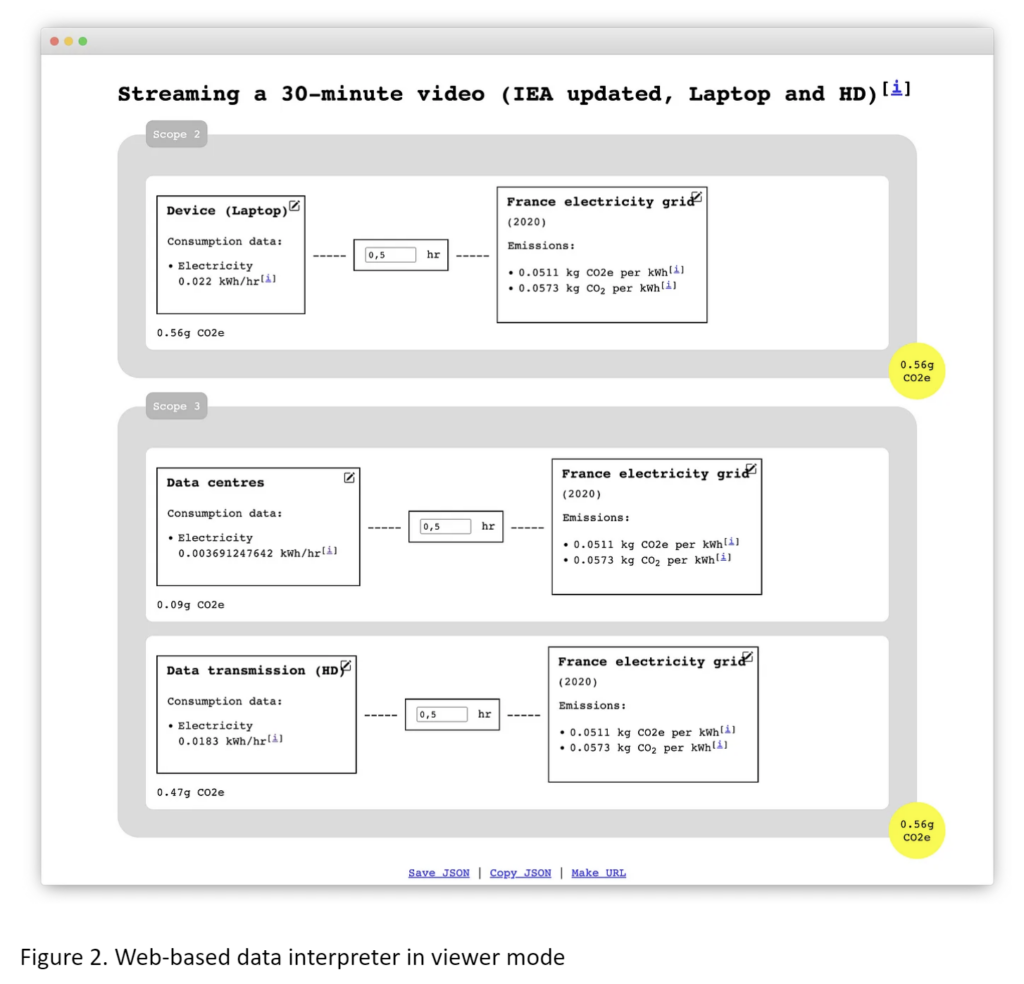
To make this data more accessible and interactive, we have created a web-based viewer capable of interpreting and visualizing the data format (Figure 2). This application consolidates emission data according to element and scope, conducts unit conversions, and establishes a common basis by considering the available data for different types of emissions (e.g., “CO2e” or “CO2”). Users can manipulate the data with real-time adjustments within the user interface, allowing them to modify quantities for individual elements and connect various data sources to replace consumer components and energy sources on the fly.
Furthermore, users can download customized scenarios as JSON files and easily share them via URL, simplifying collaborative scenario development. The application also provides a benchmark view that enables users to compare two or more scenarios using their identifiers.
The web application was built using JavaScript and is hosted as a GitHub page, ensuring straightforward deployment and updates. Additionally, the self-referential structure of our data model facilitates the hosting of nested scenarios in a distributed manner. This data interpreter can recursively retrieve and process such scenarios, enabling access and analysis of complex carbon footprint models in a distributed environment.
Example: The case of ChatGPT
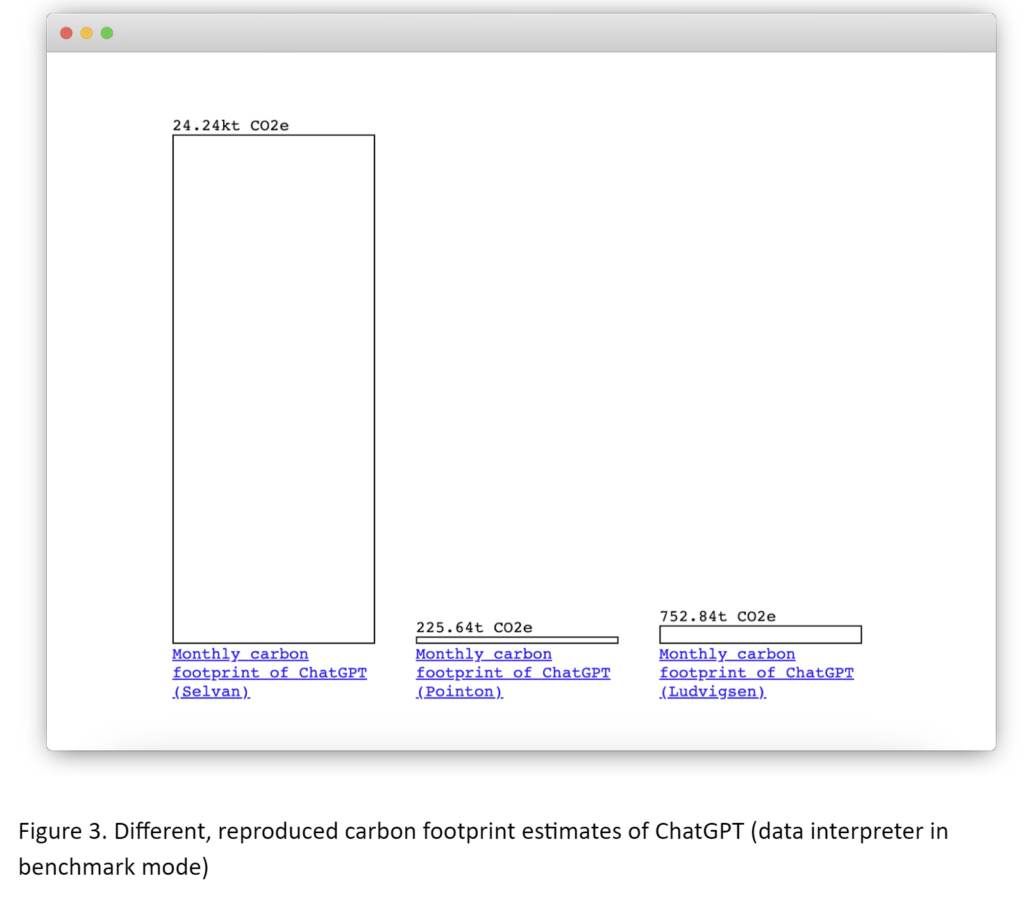
ChatGPT has taken the world by storm, while its environmental impact remains a serious concern. Numerous researchers have tried to gauge the carbon emissions associated with the service. Without official carbon emission data from OpenAI, ChatGPT’s carbon footprint estimations primarily rely on better-documented systems with similar characteristics. We delved into a comprehensive examination and comparison of three widely considered estimations of ChatGPT. We replicated their computations using our data model, illustrating how our proposal can facilitate the comparison of methodologies and enhance comprehension of the significant disparities in results. A screenshot of the interactive comparison can be found in Figure 3.
Between the lines
The current inconsistency and lack of transparency in carbon footprint scenarios pose challenges for informed decision-making. In response, we introduce an open and interconnected data model for modeling carbon footprint scenarios. This model improves transparency by allowing references to the sources of underlying assumptions, offers flexibility with a nested structure, and facilitates the straightforward reuse and collaborative use of data.
We also created a web-based data interpreter prototype that prevents data conversion errors with automated unit conversion and emission type detection. We replicated three ChatGPT carbon footprint estimates to demonstrate the effectiveness of our approach.
Our work aims to underscore the importance of transparent and robust carbon footprint modeling for making well-informed decisions regarding carbon reduction possibilities. We aspire to play a part in advancing a universal data model for quantifying carbon footprints.