

Summary contributed by Martin Pawelczyk, a PhD student at the University of Tübingen working on interpretability of machine learning models with a particular focus on algorithmic recourse.
[Original paper by Martin Pawelczyk, Teressa Datta, Johannes van-den-Heuvel, Gjergji Kasneci, Himabindu Lakkaraju]
Overview: As machine learning (ML) models are increasingly being deployed in high-stakes applications, there has been growing interest in providing recourse to individuals adversely impacted by model predictions (e.g., below we depict the canonical recourse example for an applicant whose loan has been denied).

However, recent studies suggest that individuals often implement recourses noisily and inconsistently [1]. Motivated by this observation, we introduce and study the problem of recourse invalidation in the face of noisy human responses. We propose a novel framework, EXPECTing noisy responses (EXPECT), by explicitly minimizing the probability of recourse invalidation in the face of noisy responses and demonstrate that more robust algorithmic recourse can be achieved at the expense of more costly recourse.
Introduction and Problem Setup
Common recourse approaches generate recourse under the assumption that the affected individuals will implement the prescribed recourses strictly. However, this may not always be the case in practice. It is unclear if and how often noisy implementations of recourses would result in positive outcomes for end users. Our preliminary analysis using the CARLA library [3] (figure below) indicates that state-of-the-art approaches (e.g., AR-LIME, Wachter, or GS) output recourses that are highly likely to be invalidated (as high as 60% of the time across multiple datasets) if small changes are made to the prescribed recourses. This poses a severe challenge to making algorithmic recourse practicable in the real world.
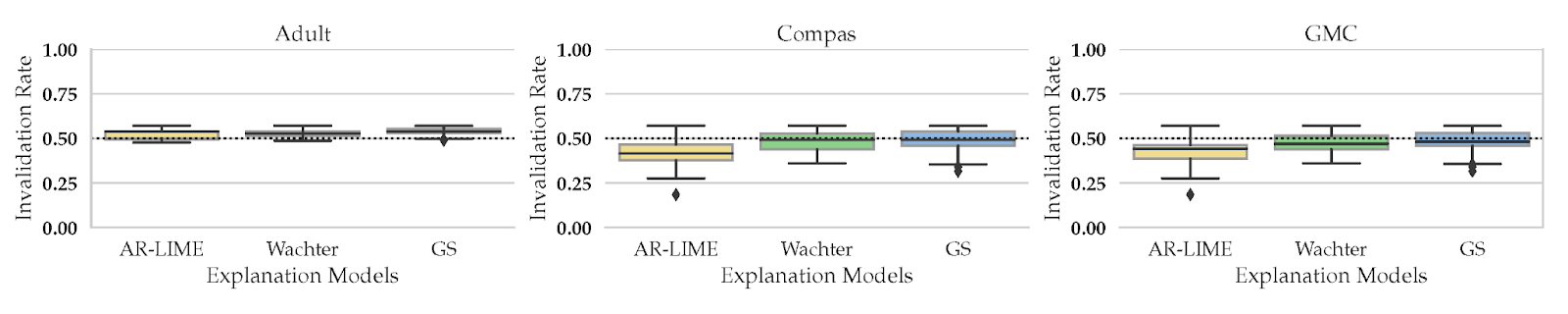
Consequently, we formulate the problem of recourse invalidation in the face of noisy human responses to prescribed recourses. We propose a new framework called EXPECTing noisy responses (EXPECT), which generates recourses by explicitly minimizing the probability of invalidation of recourses when small changes are made. Our framework can ensure that the resulting recourses are invalidated at most r% of the time where r is provided as input by the end user.
Key Insights
Traditional Recourse Approaches
Counterfactual (CF) explanation methods provide recourses by identifying which attributes to change to reverse an unfavorable model prediction. While several of these methods incorporate distance metrics or user preferences [6] to find the desired counterfactuals, some works also impose causal [5] or data manifold constraints [4] to find realistic counterfactuals.
We now describe the generic formulation leveraged by several state-of-the-art recourse methods: most methods aim to find recourses by balancing two objectives. On the one hand, the model prediction corresponding to the counterfactual should be close to the favorable outcome label. On the other hand, a regularization term encourages low-cost recourses; for example, Wachter et al. [2] propose to use the 1 or 2 norm to ensure that the distance between the original instance and the counterfactual is small.
Defining the Recourse Invalidation Rate
We first introduce two key terms, namely, prescribed recourses and implemented recourses. A prescribed recourse is a recourse that was provided to an end user by some recourse method (e.g., increase salary by $500). An implemented recourse corresponds to the recourse that the end user finally implemented (e.g., salary increment of $505) upon being provided with the prescribed recourse. With this basic terminology in place, we can now informally define the notion of Recourse Invalidation Rate (IR), which we do using the figure on the left. The blue line indicates the classifier’s decision boundary, and x is the original input and x(~) is the prescribed recourse.
The shaded region (h=0) belongs to the negative class, and the unshaded region (h=1) to the positive class. Panel a) demonstrates where the recourse invalidation rate for the prescribed recourse is high because small perturbations to the prescribed recourse x are more likely to end up in the shaded region (negative class). Panel b) demonstrates the opposite case. To model that the implemented recourse will unlikely match the prescribed recourses, we add normally distributed noise with mean parameter 0 and fixed variance parameter to the prescribed recourse. We then define a recourse invalidation measure delta belonging to [0,1,], which captures the following intuition:

- When delta = 0, then, the prescribed recourse and the recourse implemented by the user agree all the time (low IR);
- when delta = 0.5, the prescribed recourse and the implemented recourse agree half of the times;
- when delta = 1 then the prescribed recourse and the recourse implemented by the user never agree (high IR).
Minimizing the Recourse Invalidation Rate
The main idea of our method consists of finding a recourse suggestion whose prediction at any point y within some set around the prescribed recourse belongs to the positive class with probability r. Hence, our idea consists of minimizing the recourse invalidation rate subject to the constraint of low-cost recourse.

In the Figure, we demonstrate how our method EXPECT finds recourses relative to the algorithm proposed by Wachter et al. [2] (black plus) for a given negatively classified input (black dot). We see that EXPECT finds recourses (black stars) in line with the chosen invalidation target (e.g., in the left panel, the target is set r=0.3) and the variance sigma^2 which controls the size of the neighborhood, in which the recourses have to be robust. The circles around EXPECT’s recourses have a radius, 2*sigma i.e., they show the region where 95% of recourse inaccuracies fall when sigma^2=0.05. We refer to our paper for an example of how EXPECT finds robust recourses for tree-based models.
Controlling the Invalidation Rate and a Cost-Robustness Trade-off
Here, we briefly evaluate key properties of our proposed recourse algorithm. First, in the figure below, we demonstrate that the invalidation rates of the recourses by our framework can be controlled by setting the invalidation target r to desired values.

The figure verifies that the empirical invalidation rate is at most equal to the invalidation target r, as desired. Here, we show these findings on the adult data set for different sizes of the neighborhoods controlled by sigma^2 when recourses are generated with respect to a neural network classifier. Second, in the figure below, we demonstrate the relation between the invalidation target r and the costs of algorithmic recourse when the underlying classifier is a neural network.

As the invalidation target decreases, the cost of recourse increases.
In summary, our method offers tight control over the invalidation rate, achieved at higher recourse costs for the end-user. We argue that the choice for trading off recourse invalidation and recourse costs should be left to the end-users, who presumably know how precisely they can implement the prescribed recourses.
Between the Lines
In our work, we introduced and studied the critical problem of recourse invalidation in the face of noisy human responses. More specifically;
- we theoretically and empirically analyzed the behavior of state-of-the-art recourse methods and demonstrated that the recourses generated by these methods are very likely to be invalidated if small changes are made to them;
- we proposed a novel framework, EXPECTing noisy responses (EXPECT), which addresses the aforementioned problem by explicitly minimizing the probability of recourse invalidation in the face of noisy responses.
Our work also paves the way for several interesting future research directions in the field of algorithmic recourse. For instance, it would be interesting to build on this work to develop approaches that can generate recourses that are simultaneously robust to noisy human responses, noise in the inputs, as well as shifts in the underlying models. It would also be essential to understand the trade-offs involved in achieving these different kinds of robustness.
References
[1] Daniel Bjorkegren, Joshua E. Blumenstock, and Samsun Knight. Manipulation-proof machine learning. arXiv:2004.03865, 2020
[2] Sandra Wachter, Brent Mittelstadt, Chris Russel. Counterfactual Explanations without Opening the Blackbox: Automated Decision and the GDPR. Harvard Journal of Law & Technology, 2018
[3] Martin Pawelczyk, Sascha Bielawski, Johannes van-den-Heuvel, Tobias Richter, Gjergji Kasneci. CARLA: A Python Library to Benchmark Algorithmic Recourse and Counterfactual Explanation Algorithms. 35th Conference on Neural Information Processing Systems (NeurIPS) Benchmark and Datasets Track (2021)
[4] Martin Pawelczyk, Klaus Broelemann, Gjergji Kasneci. Learning Model-Agnostic Counterfactual Explanations for Tabular Data. Proceedings of the Web Conference (WWW) 2020
[5] Amir-Hossein Karimi, Bernhard Schölkopf, Isabel Valera. Algorithmic Recourse: From Counterfactual Explanations to Interventions. Proceedings of FAccT 2021[6] Kai Rawal, Himabindu Lakkaraju. Beyond Individualized Recourse: Interpretable and Interactive Summaries of Actionable Recourses. 34th Conference on Neural Information Processing Systems (NeurIPS) (2020)