


🔬 Research Summary by Mattia Cerrato and Marius Köppel
Marius Köppel is a PhD. student at the Johannes Gutenberg-Universität Mainz working on FPGA based data acquisition systems, lepton flavor violation and fairness in Machine Learning.
Mattia Cerrato is a Post-Doc at the Johannes Gutenberg-Universität Mainz working at the intersection of interpretability and fairness in Machine Learning.
[Original paper by Mattia Cerrato, Alesia Vallenas Coronel, Marius Köppel, Alexander Segner, Roberto Esposito, Stefan Kramer]
Overview: Neural networks are inherently opaque. While it is possible to train them to learn “fair representations”, it is still hard to make sense of their decisions on an individual basis. This is in contrast with law requirements in the EU. We propose a new technique to open the “black box” of fair neural networks.
Introduction
AI methodologies based on deep neural networks are nowadays hugely popular, especially in Computer Vision and Natural Language Processing. Compared to other AI/machine learning techniques, deep neural networks promise a higher level of performance and thus to enable a plethora of applications.
In recent years, the research community and the general public has been focusing more and more on the limitations of AI and the failure cases in which this set of technologies and deep neural networks in particular may be impacting people’s well-being negatively.
Perhaps two of the most famous failure points in applications employing deep neural networks have been reported by Forbes and The Guardian: “Google Photos Tags Two African-Americans As Gorillas Through Facial Recognition Software” [1] and “A beauty contest was judged by AI and the robots didn’t like dark skin” [2]. There is therefore true cause for worrying that negative biases in society may be transferring to machine learning models, thus leading to models which are discriminating in turn.
While different approaches show that “unfair” behavior may be avoided in deep neural network models via group fairness techniques, we still do not know much about their internal reasoning. Therefore, we are still unable to answer individual appeals. The legal status of these models is thus unclear. As an example, the General Data Protection Regulation (GDPR) in the EU states that individuals subjected to automatic decision making have a “right to an explanation” [3].
In this space, our research constrains deep neural networks so that they are decomposable and therefore human-readable. Our framework is centered around the concept of a correction vector, i.e. a vector of features which is interpretable in feature space and represents the “fairness correction” each data point is subject to so that the results will be statistically fair.
Our recent paper focuses on answering the following three questions:
- Are the proposed models both fair and accurate?
- Are the interpretable models as fair as their non-interpretable counterparts?
- Are the correction vectors interpretable?
Key Insights
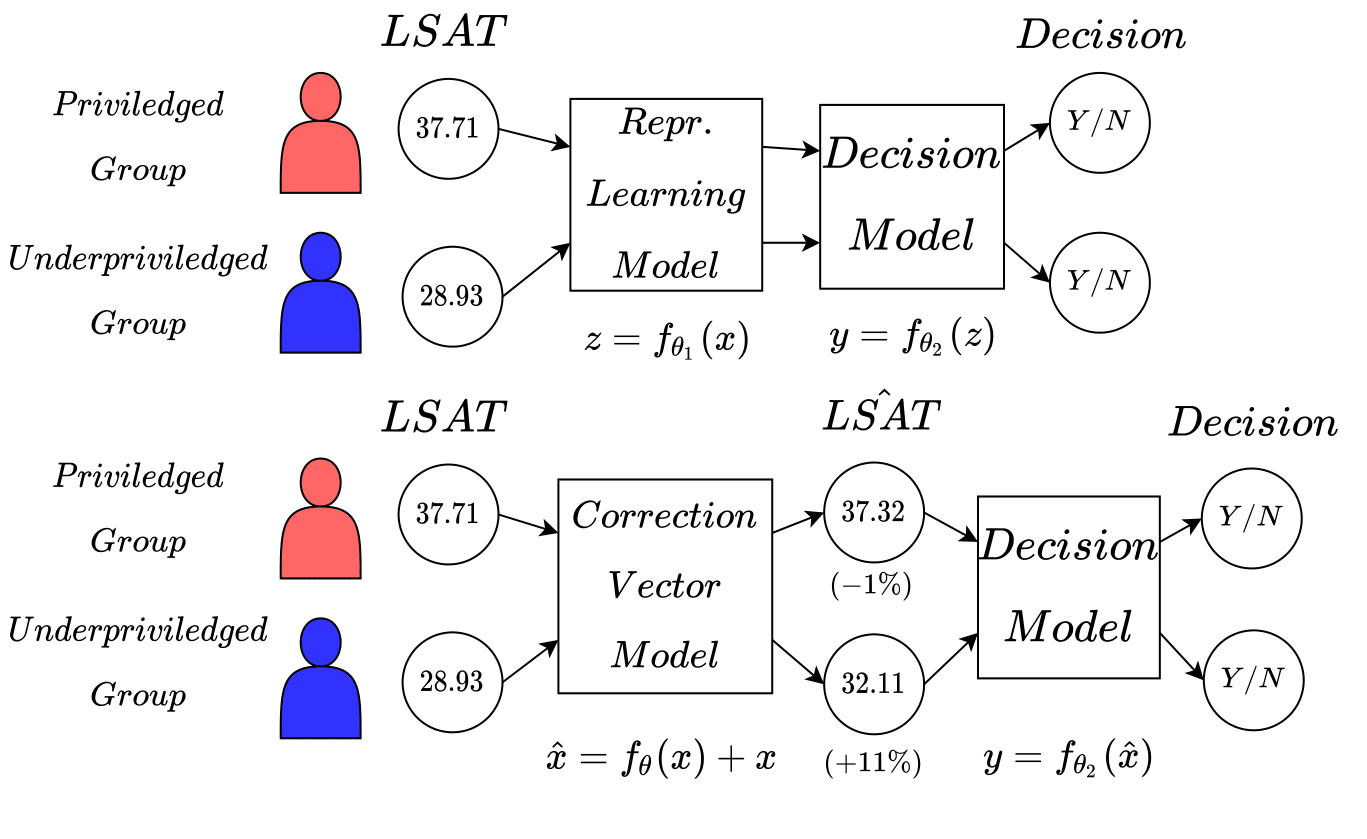
Group Fairness in Machine Learning
One possible approach to avoid discriminating models is to remove information about the sensitive attribute (e.g. ethnicity) from the model’s internal representations. These techniques are commonly referred to as “fair representation learning”, where a projection f : X → Z from feature space X into a latent space Z is learned. It can be shown that the information about the sensitive attribute s is minimal in the latent space.
This reasoning is at the core of commonly employed “fair” neural networks (top). It learns a mapping Z into an opaque feature space and then a decision Y. Our correction vector framework (bottom) learns a debiased but interpretable representation X. This provides individual users and analysts with further insight into the debiasing process. The correction displayed in the figure is the average correction learned by one of our models on the LSAT feature of the Law Students dataset, in which the task is to provide law school admissions in a balanced fashion between student ethnicities.
Our approach is to learn fair corrections for each of the dimensions in X. Fair corrections are then added to the original features so that the semantics of the algorithm are as clear as possible. For each feature, one can obtain a clear understanding of how that feature has been changed to counteract the bias in the data. We compute these corrections in two different methodologies.
Explicit Computation of Correction Vectors with Feedforward Networks

Explicit computation requires constraining a neural network architecture so that it does not leave feature space. Different fairness methodologies may be constrained in such a way. A gradient reversal-based neural network constrained for interpretability to be part of the proposed framework (see figure above). The learned correction vector w matches in size with X, and can then be summed with the original representation X and analyzed for interpretability.
Implicit Computation of Correction Vectors with Normalizing Flows
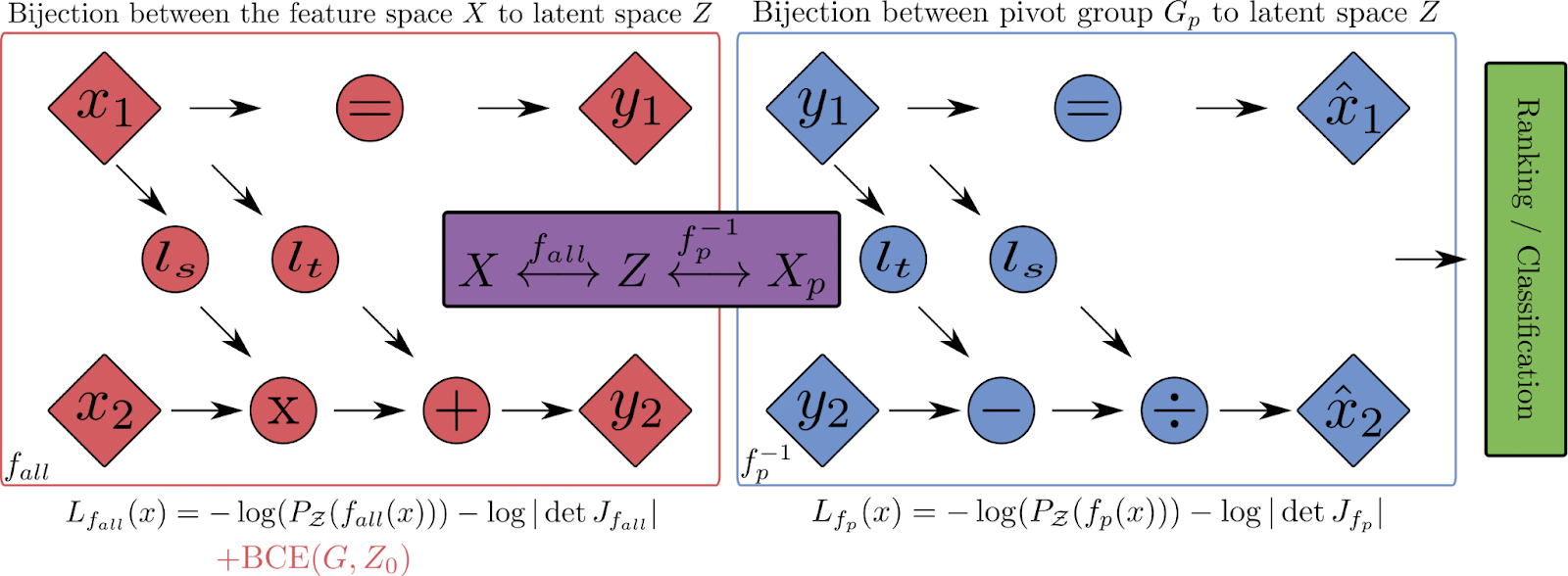
Implicit computation relies on a pair of invertible normalizing flow models to map individuals belonging into different groups into a single one. Here, a correction vector may still be computed as the new representations are still interpretable in feature space.
Experimentation / Conclusions
In this paper we presented a framework for interpretable fair learning based around the computation of correction vectors. Experiments showed that existing methodologies may be constrained for explicit computation of correction vectors with negligible losses in performance. In the light of recent developments in regulation at the EU level, we reason that our correction vector framework is able to open up the black box of fair DNNs. Under the GDPR, it remains to be seen which content requirements are to be met when having to disclose “the logic involved” and, secondly, their realization in practice. The “black box” problem and the way it limits legal compliance in practice seems to not have been considered when the GDPR was brought to life.
Thus, the transparency requirements of the GDPR must be interpreted retrospectively with regard to the functioning of DNNs.
Between the lines
AI methodologies are facing more stringent law requirements by the day. While the GDPR was not written with black box models in mind it should be clear that providing interpretable fair models is the way to go for further research. This leads to more attention at the intersection of law interpretation and machine learning technology. Furthering our understanding of how end users may trust AI systems will be more and more important.
References
[3] Malgieri, Gianclaudio, The Concept of Fairness in the GDPR: A Linguistic and Contextual Interpretation (January 10, 2020). Proceedings of FAT* ’20, January 27–30, 2020. ACM, New York, NY, USA, 14 pages. DOI: 10.1145/3351095.3372868, Available at SSRN: https://ssrn.com/abstract=3517264