

🔬 Research Summary by Jintian Zhang and Shumin Deng
Jintian Zhang is a Master student in Zhejiang University.
Shumin Deng is a postdoctoral research fellow in National University of Singapore.
[Original paper by Jintian Zhang, Xin Xu, and Shumin Deng]
Overview: This paper delves into the collaborative dynamics within multi-agent societies composed of Large Language Models (LLMs), focusing on how these models can mimic human-like collaborative intelligence. By creating unique ‘societies’ of LLM agents with varying traits and thinking patterns, the study evaluates their performance across benchmark datasets, uncovering human-like social behaviors and effective collaborative strategies. The findings integrate Social Psychology insights, underscoring the potential of LLMs in complex social environments and paving the way for further research in this area.
Introduction
This research explores the integration of social intelligence in Large Language Models (LLMs) guided by the Society of Mind (SoM) framework, investigating the emulation of human-like collaboration in multi-agent societies. Utilizing LLM, like ChatGPT, we simulate societies of LLM-based agents with individual traits like easy-going and overconfident, engaging in thinking patterns of debate and reflection to explore diverse collaborative strategies.
Our findings reveal the minimal influence of individual traits on performance and the significant impact of collaborative strategies. Engaging in debates enhances performance, but increasing agent numbers or collaboration rounds does not always yield better outcomes. This challenges the belief that scale is paramount, suggesting multi-agent collaboration as a key to more advanced AI systems. The study also uncovers human-like behaviors in LLM-based agents, offering insights for developing more socially-aware AI and efficient multi-agent systems.
Key Insights
Simulation Setup
Figure 2 outlines the detailed setup of our society simulation experiments.
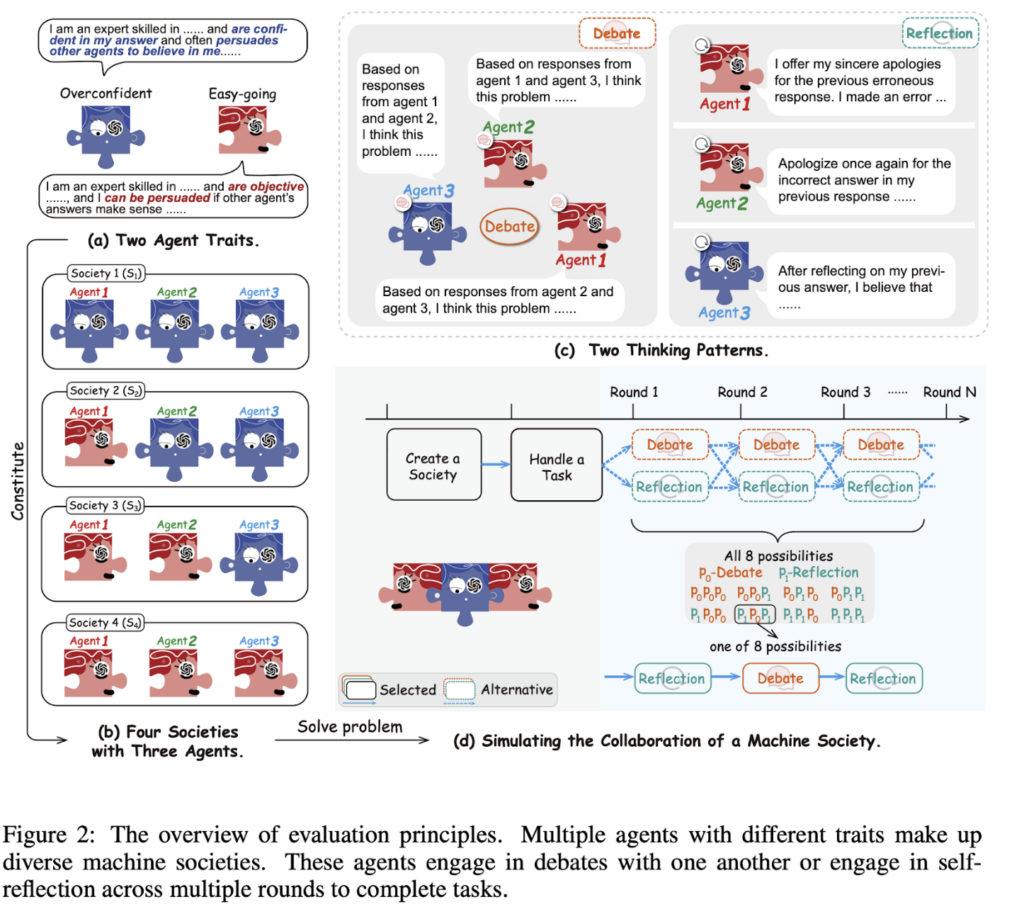
Specifically, our experimental setup involves three LLM agents in a machine society, displaying individual traits of overconfidence and easy-goingness, as shown in Figure 2(a). We examine their collaboration through debate and reflection, as shown in Figure 2(c), across three datasets: MMLU, MATH, and Chess Move Validity.
We simulate four different societies with the three agents, as shown in Figure 2(b). We set up three collaboration rounds in each society, as shown in Figure 2(d), where p0 denotes debate (, the number 0 is like an open mouth about to speak for debate). In contrast, p1 denotes reflection (🤔, the number 1 is like a tightly closed mouth for self-reflection). It’s important to note that all agents employ the same thinking patterns in one round of collaboration.
Experiment Analysis on Societies and Collaborative Strategies
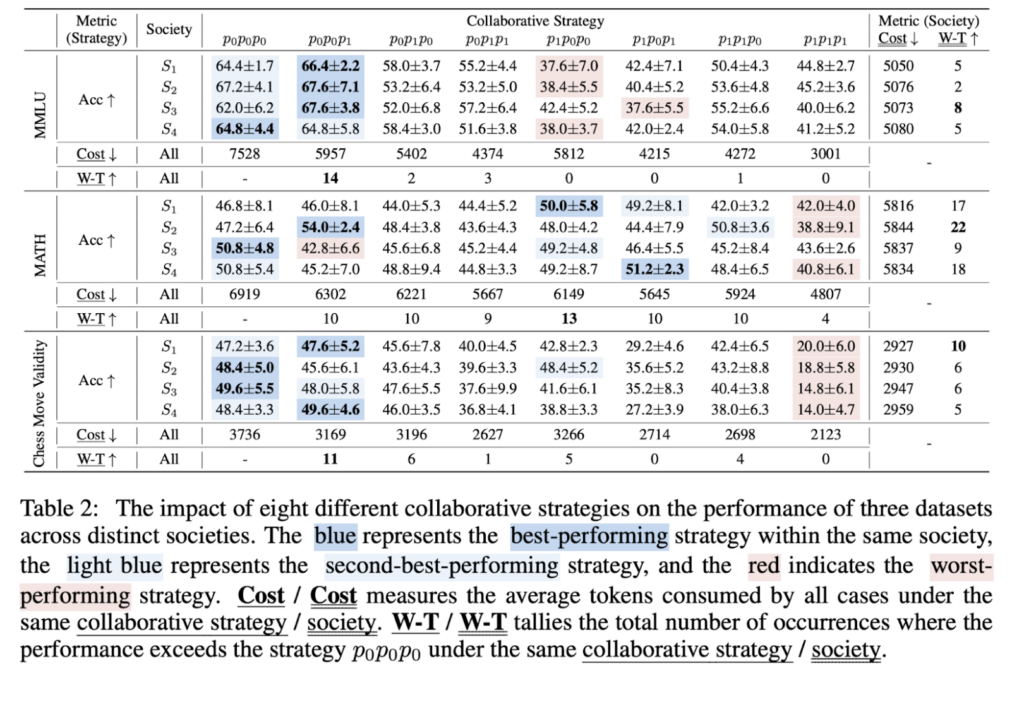
The main experiment results, presented in Table 2, assess diverse collaborative strategies across four societies regarding accuracy, cost, and W-T (win-tie) on three datasets. We observe that:
– Collaborative strategies excel societies in determining performance. We attribute the reason to the alignment of the LLMs. As shown in Figure 8, agents in the two societies (S1 comprising three overconfident agents and S4 comprising three easy-going agents) with the most notable differences in agent individual traits tend to exhibit easy-going rather than overconfident traits.
– The strategic sequencing of thinking patterns is crucial for collaboration mechanisms. For example, in the S1 society on the MMLU dataset, the strategy p0p0p1, which conducts two rounds of debate, achieves an accuracy of 66.4%, while the p1p0p0 strategy only achieves 37.6%. – Different collaborative strategies significantly influence resource consumption, with certain strategies balancing maintaining high performance and reducing resource overhead. The collaborative strategies p0p0p1 and p0p0p0 consistently demonstrate close performance, while the former has less cost of tokens.

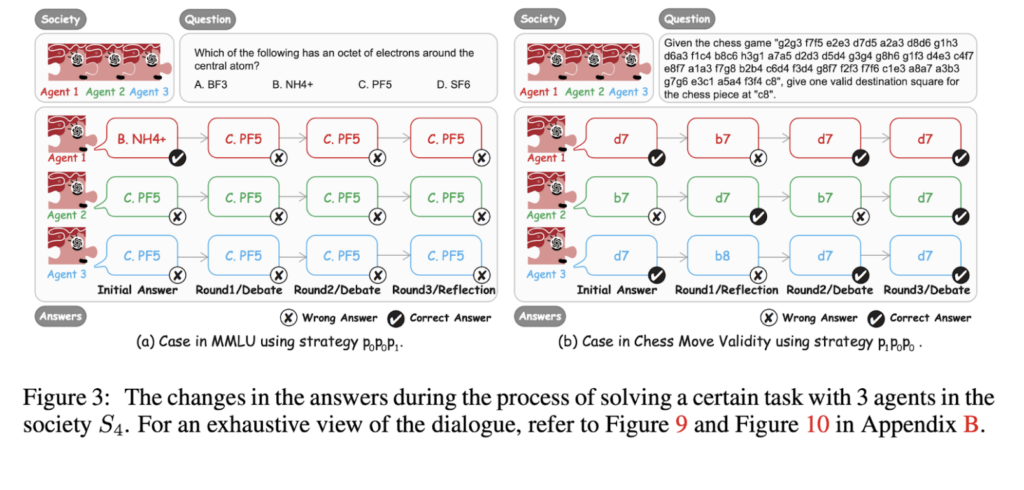
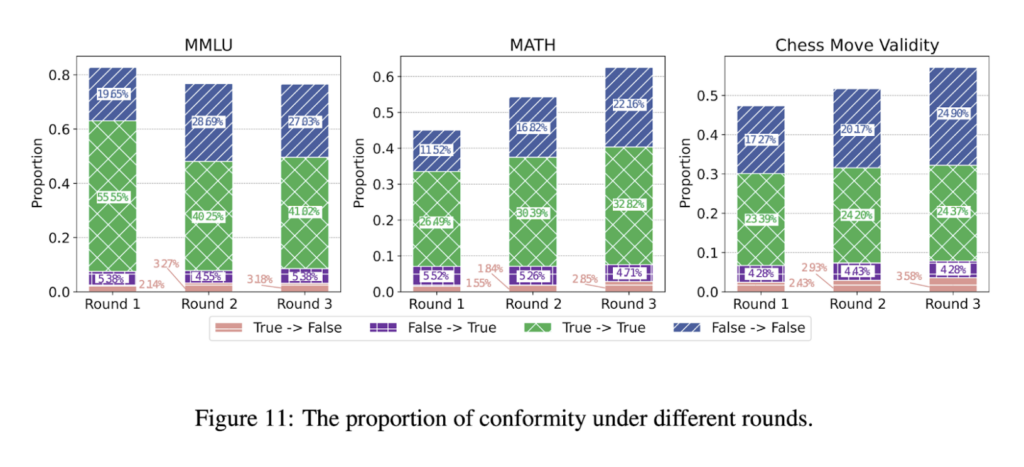
Furthermore, we perform an initial analysis comparing machine societies to human societies. Figure 3(a) shows a distinct conformity phenomenon in machine societies, akin to human society. We find that the proportion of conformity is also high in machine societies (as shown in Figure 11). Figure 3(b) highlights the significance of collaboration. Three agents achieved consistent and accurate answers after three rounds of collaboration, which can also be observed in human societies.
A Social Psychology View
To grasp the essence of collaboration, we observe the evolution of answer correctness within the machine society over three rounds of collaboration. Let T denote the correct answer, and F denote the wrong answer. For instance, TFTF indicates that the initial response is correct, turns incorrect after the first collaboration, correct again after the second collaboration, and incorrect after the third collaboration. We have summarized the representative situations into three groups:
– Correcting Mistakes (FFFT, FFTT, FTTT).
– Changing Correct Answers (TFFF, TTFF, TTTF).
– Wavering Answers (FTFT, FTTF, TFTF, TFFT) can also be seen as model hallucinations.
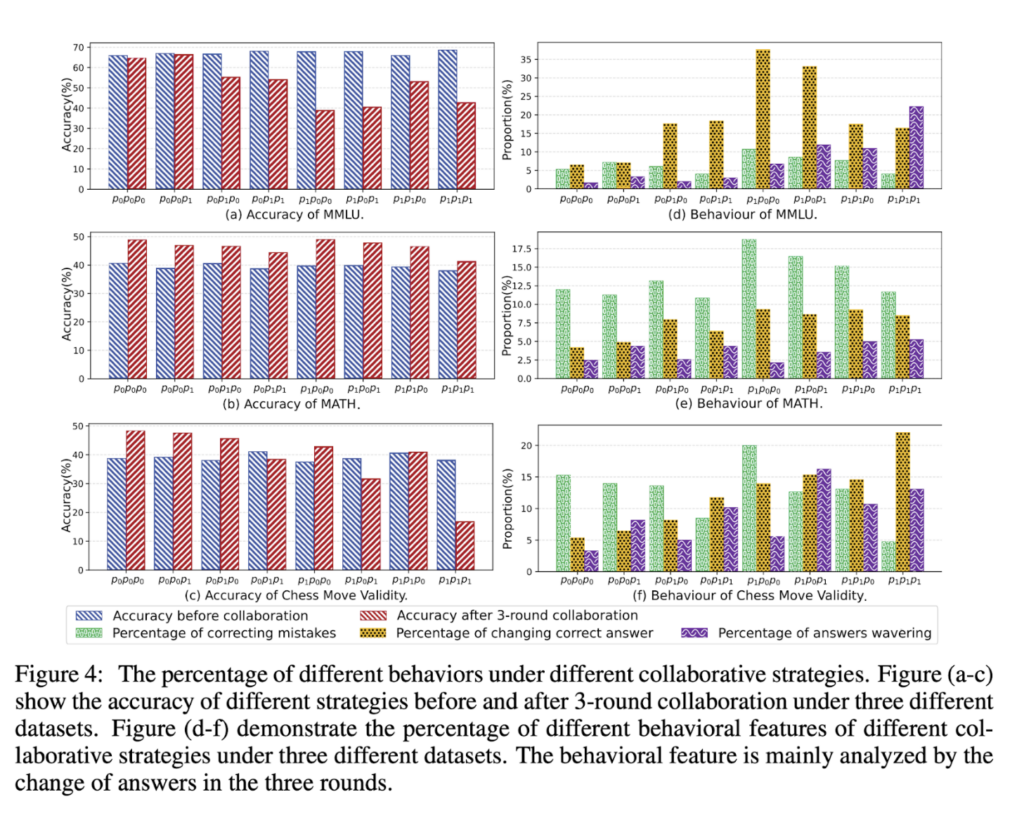
The accuracy of machine society’s answer before and after collaboration is shown in Figure 4(a-c). The evolution of the answer correctness on the three datasets is shown in Figure 4(d-f). We observe:
– Continuous reflection can result in the instability of outcomes and model hallucinations, as observed in Figure 4(d-f), where collaborative strategies such as p0p1p1, p1p1p0, and p1p1p1 exhibit the highest prevalence of “wavering answers.” Further, engaging in debates can mitigate the hallucination phenomenon.
– Multi-agent collaboration is effective for difficult tasks (e.g., MATH and Chess), as observed in Figure 4(b-c), while it is useless for easy tasks (e.g., MMLU), as observed in Figure 4(a).
Effects of Agent Quantity, Collaboration Round, and Strategy Settings
We also explore how the number of agents, different collaboration rounds, and other strategy settings affect performance.
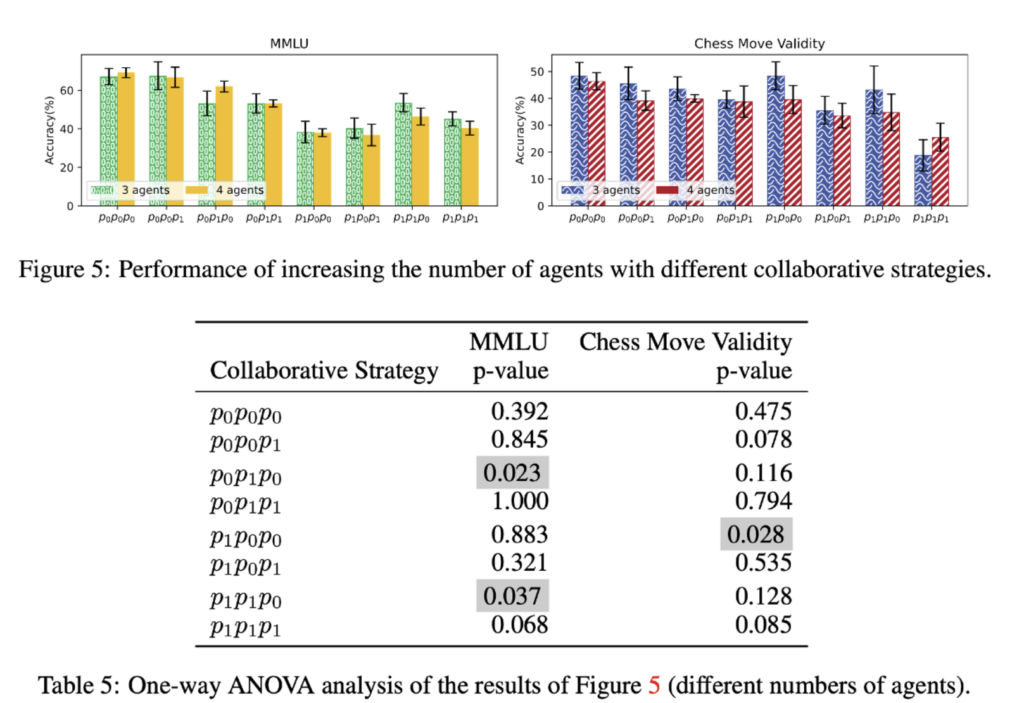
As seen from the results in Figure 5 and the significance test in Table 5, we infer that setting the agent number to 3 yields optimal performance.
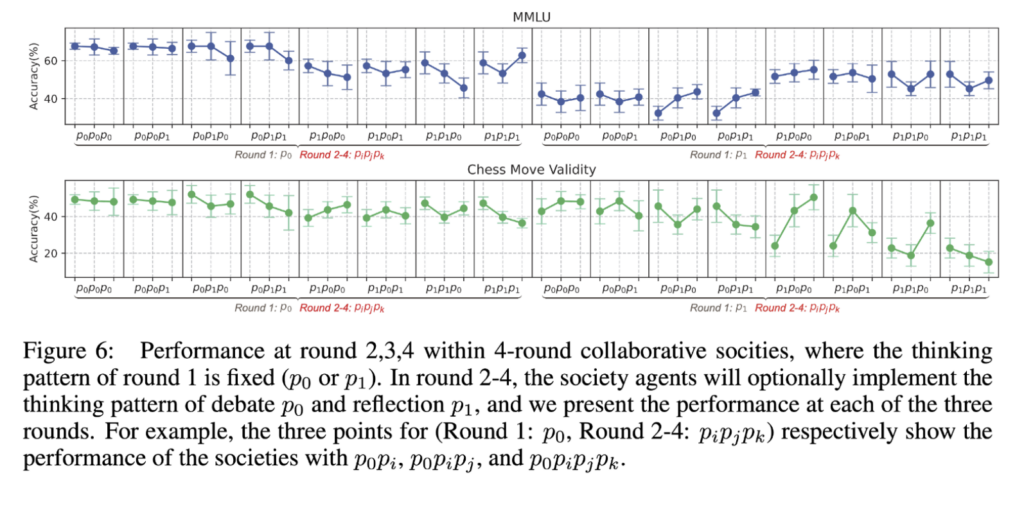
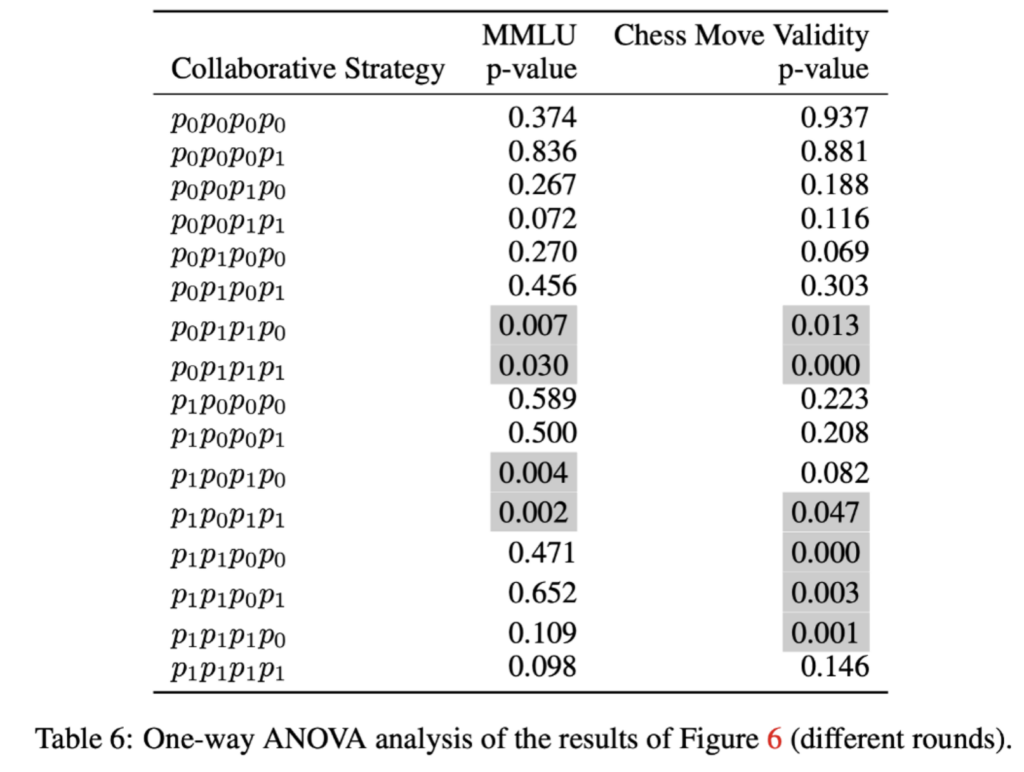

As seen from the results in Figure 6, Figure 12, and the significance test in Table 6, we can infer that collaboration rounds closely correlate with consistency. Debates enhance it, while reflection diminishes it. With high societal consistency, additional debate rounds yield no performance boost. Conversely, in low-consistency scenarios, more debates enhance consistency, promoting performance.
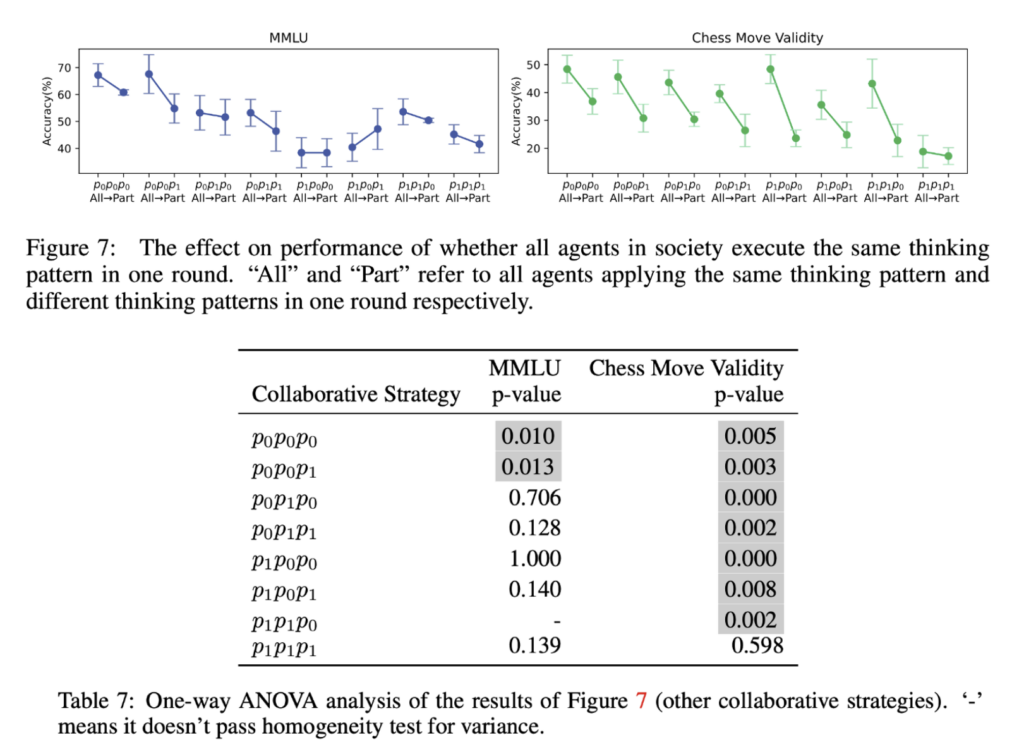
As seen from the results in Figure 7 and the significance test in Table 7, we can infer that it is crucial to maintain a uniform collaborative strategy with the same thinking pattern among all agents in one round.
Between the lines
This research underscores the potential of collaborative mechanisms with LLMs, revealing the advanced capabilities of LLM-based agents in varied collaboration settings. It highlights the emergence of human-like social behaviors in these agents, aligned with social psychology theories. As LLMs evolve, understanding their influence on collaborative behaviors becomes crucial. This study paves the way for more socially-aware NLP systems and provides a foundation for future explorations in multi-agent societies and their collaboration mechanisms.