


🔬 Research Summary by Matthias Samwald, an associate professor at the Medical University of Vienna and works on making powerful AI systems driving biomedical progress more trustworthy.
[Original paper by Konstantin Hebenstreit, Robert Praas, and Matthias Samwald]
NOTE: Published at Socially Responsible Language Modelling Research (SoLaR) workshop, NeurIPS 2023
Overview: This paper addresses the challenges in assessing and guiding the behavior of large language models (LLMs). It proposes a set of core principles based on an extensive review of literature from a wide variety of disciplines, including explainability, AI system safety, human critical thinking, and ethics.
Introduction
Large language models (LLMs) like GPT-4 show great promise. But what are the principles that should govern how they reason and behave?
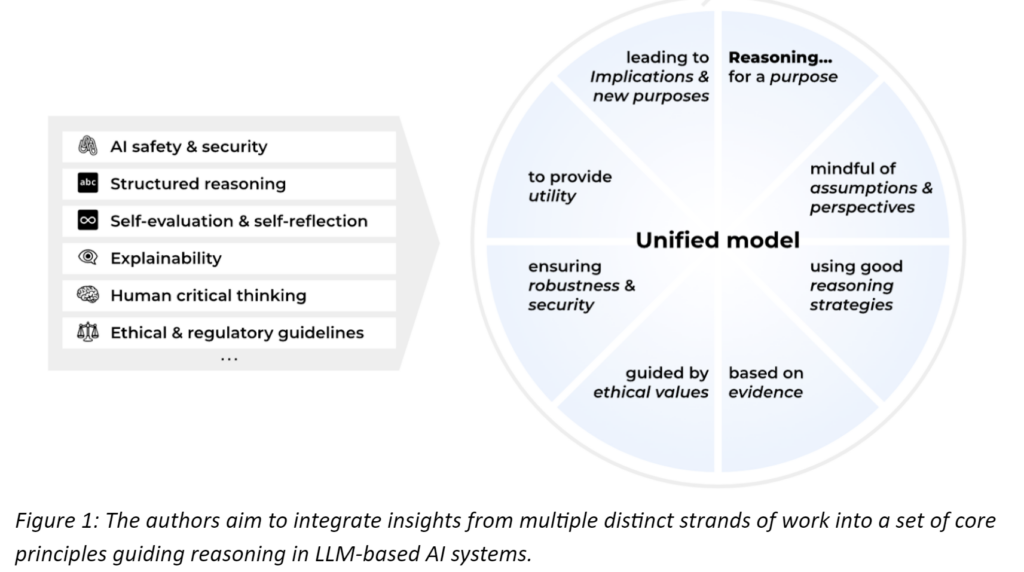
This paper tries to provide answers to these questions by assembling ideas from a wide variety of sources, such as work on machine learning explainability, AI system safety, human critical thinking, and ethical guidelines (Figure 1). The study’s main objective is to compile a set of core principles for steering and evaluating LLMs’ reasoning, using an extensive literature review and a small-scale expert survey. These principles can prove useful to monitor and improve model behavior during training and inference and can guide human evaluation of model reasoning.
Key Insights
Compilation and curation of principles
The authors set out the study by conducting an extensive literature review across several domains, leading to the extraction of 220 principles. These were categorized into seven areas: assumptions and perspectives, information and evidence, robustness and security, utility, reasoning, ethics, and implications. A consolidated set of 37 core principles was distilled, considering the relevance to current LLMs and adaptability to various reasoning tasks and modalities.

Expert Survey and Validation
For external validation, domain experts were surveyed to rate the importance of each principle. This helped refine and validate the core principles, ensuring they align with expert opinions and are relevant to practical applications.
Results and Implications
The principles are meant to guide the reasoning of LLMs. They are envisioned to serve in monitoring and steering models, improving behavior during training, and aiding in human evaluation.
Between the lines
The principles are biased towards current language-based applications of LLMs. Expansions will likely be necessary soon to address emerging concerns, as AI systems evolve from LLMs into more autonomous agents.
The work is preliminary and the set of principles is far from exhaustive. The authors call for further community engagement to refine and expand these principles. They suggest methods like Delphi studies or online platforms for iterative principle development and emphasize the need for input from a broader range of stakeholders.
There is ample opportunity for empirical research testing the practical utility of these (and other) principles. As a simple example, prompts derived from these principles can be tested on state-of-the-art models to evaluate their impact on performance, explainability, and ethical alignment.