


🔬 Research Summary by Qiang Sheng, a fourth-year Ph.D. student in Computer Science and Technology at the Institute of Computing Technology, Chinese Academy of Sciences, whose research interests include fake news detection, fact-checking and social media mining.
[Original paper by Qiang Sheng, Juan Cao, Xueyao Zhang, Rundong Li, Danding Wang, and Yongchun Zhu]
Overview: Recent years have witnessed a surge of fake news detection methods that focus on either post contents or social contexts. In this paper, we provide a new perspective—observing fake news in the “news environment”. With the news environment as a benchmark, we evaluate two factors much valued by fake news creators, the popularity and the novelty of a post, to boost the detection performance.
Introduction
The wide spread of fake news online poses real-world threats in many fields. Existing works focus on finding useful information from the content (“What is it?”) or social contexts (“What does it trigger?”), ignoring the factors that guide the fake news creation (“Why does it emerge?”). We argue that a news environment, which represents recent mainstream media opinion and public attention, is an important inspiration for the fabrication of contemporary fake news. Since any gains of fake news achieve only if it is widely exposed and virally spreads, fake news would be often designed to ride the wave of popular events and catch public attention with novel content, where the recently published news (which shapes the news environment) must be considered. The following figure exemplifies the connection between fake news and the news environment.
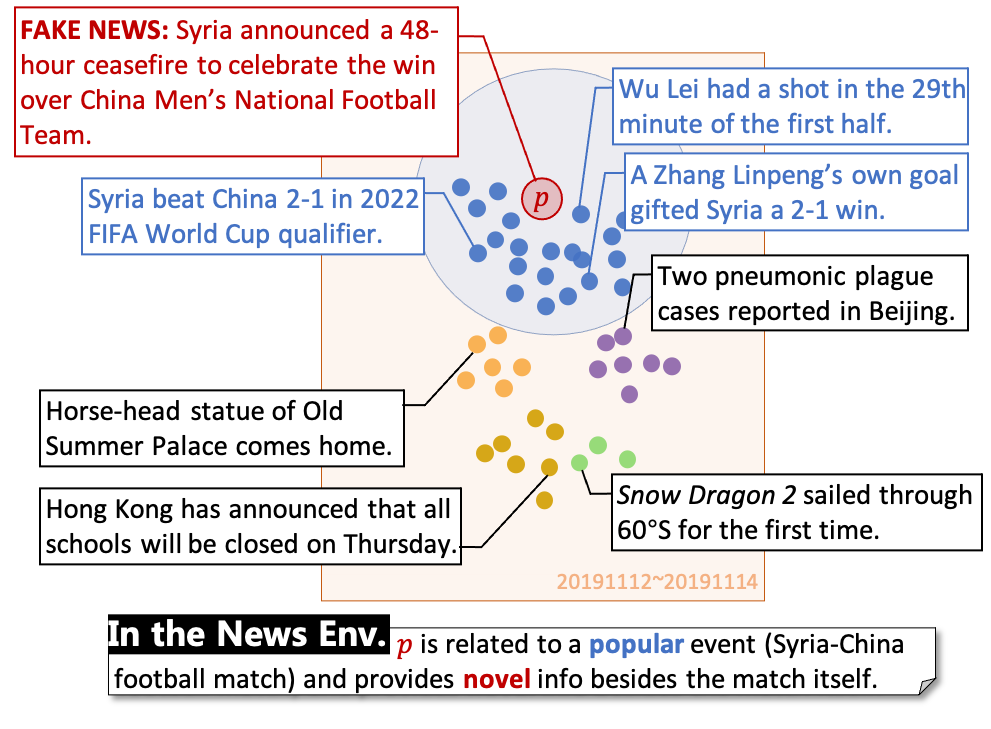
In this paper, we design the News Environment Perception framework, where we take the news environment as the benchmark to evaluate the popularity and the novelty of the given news. We experimentally show that the perceived information from news environments boosts the detection performance, especially for fake news related to societal events and crises.
Key Insights
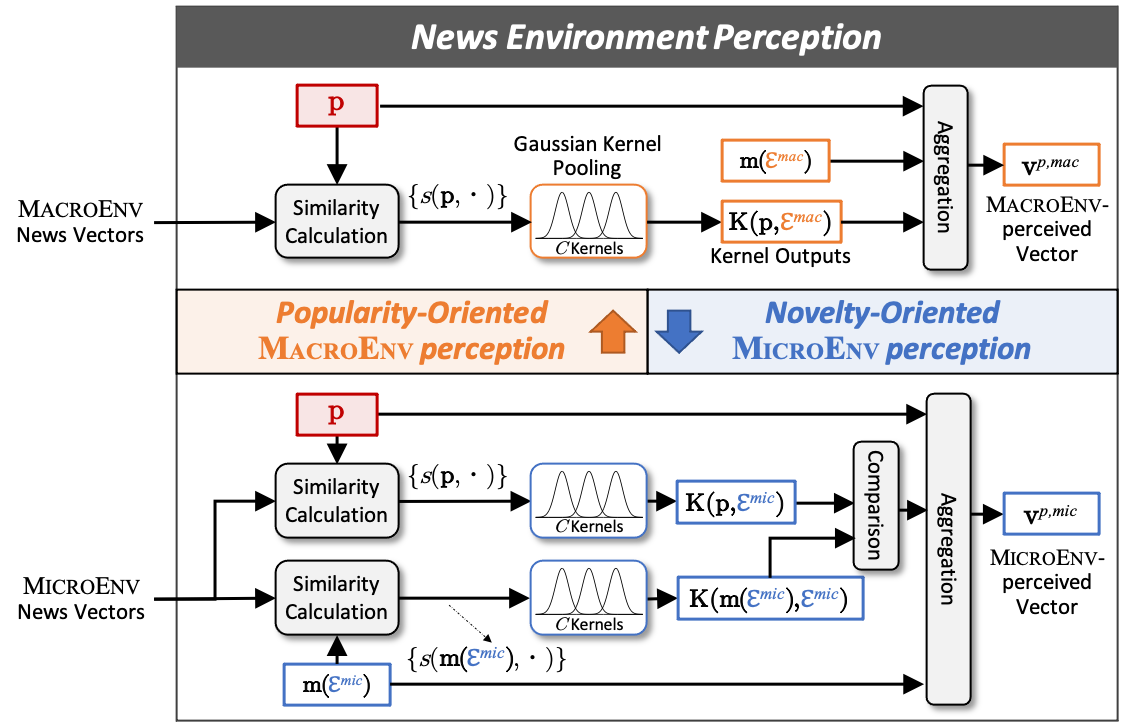
How do We Construct a Legitimate News Environment?
A legitimate news environment should content news reports which can reflect the present distribution of mainstream focuses and audiences’ attention. To this end, we collect news items published by mainstream media outlets as basic environmental elements, in that their news reports generally face a large, common audience. To facilitate the evaluation of popularity and novelty, we construct two types of news environments, namely, macroEnv and microEnv. Given a post p, a macroEnv includes all news items from the selected outlets within T days (here, T=3) before p is published, and a microEnv is the subset of macroEnv where the items are relevant to p. Intuitively, the time-constrained environment macroEnv provides a macro perspective of what the mass audience read and focus on recently, while the further relevance-constrained one microEnv describes the distribution of items about similar events.

Connecting the News with its Environment
Having prepared the two news environments, we need to “perceive” how the given news connects with its news environments and summarize the perceived information. Recall that we require the final output to be, more or less, an indicator of how popular and novel the post p is. In our framework, such “one-vs-many” (post-environment) relationship modeling is separated into many “one-vs-one” modeling (post-news item). We use the pre-trained language model (e.g., BERT [https://aclanthology.org/N19-1423.pdf]) to represent p and the news items in the environment and calculate the cosine similarity of the representation vectors in each post-news item pair. Then we obtain a similarity list (whose length depends on the number of news items) that indicates the “one-vs-one” connection. But how do we summarize them into one vector to directly show the “one-to-many” relationship? Inspired by Xiong et al. [2017] [https://dl.acm.org/doi/10.1145/3077136.3080809] and Liu et al. [2020] [https://aclanthology.org/2020.acl-main.655.pdf], we use the Gaussian Kernel pooling to obtain a distribution that serves as a soft histogram. We set several Gaussian kernels in small intervals across the range of cosine similarity whose centers are in the middle of the corresponding intervals. If a similarity value is close to the center of a kernel, then this kernel output would be close to 1; otherwise to 0. By summing the kernel outputs, we realize soft counting (with not a rigid interval setting) and summarize how similar the post p is to the news environment.
For the popularity measurement, we apply the above steps in the macroEnv. For the novelty measurement, we use similar steps in the microEnv for not only the post p but also the center of the microEnv (which could be regarded as the representative of what has been discussed in this event). We then compare the results to highlight how novel the post p is in the microEnv. Finally, we obtain two vectors representing the post-environment relationships, i.e., the macroEnv-perceived vector and the microEnv-perceived vector.
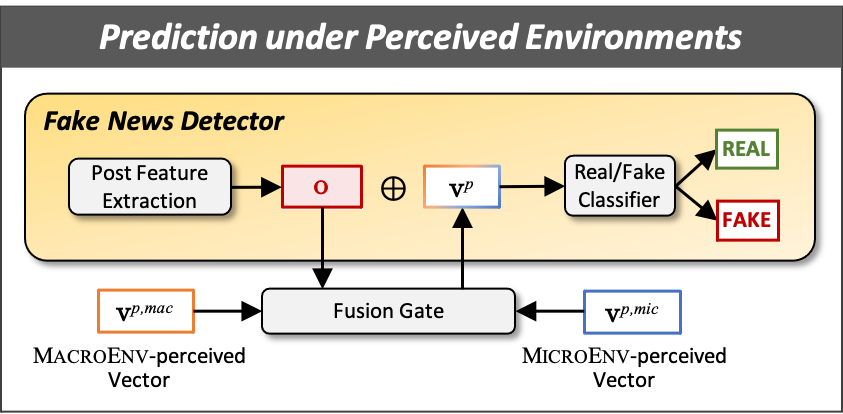
Boosting Fake News Detection by Fusion
Our framework is not meant to replace existing models, but to boost their performances by including the information from news environments. This is a more practical and robust solution for real-world systems. Given a vector o from the high layer of a fake news detector (which could be any neural network), we use a gate to adaptively fuse the macroEnv-perceived vector and the microEnv-perceived vector with the vector o. The fused vector is used for the final prediction of whether p is real or fake. We will show that our framework is compatible with many fake news detectors below.
Results and Cases
On two newly constructed datasets (one in Chinese and one in English), we implement six representative methods for fake news detection with our framework. See the paper [https://arxiv.org/pdf/2203.10885] for experimental results. We see that all six base models obtain an improvement in terms of accuracy and macro F1 and the F1 score on the fake class often benefits more than the real class. This is a practical property as we aim at detecting fake news.
To see how the fake news posts connect to the two different environments, we selected the top 1% of fake news samples which our framework relies more on macroEnv or microEnv. From the pie charts, we see that the macroEnv is more useful for posts about crises (e.g., earthquakes and air crashes), while the microEnv works effectively in Society & Life (e.g., robbery and education). This is in line with our intuition: crises are often sensational and popular, in which macroEnv would help more; and posts about common events in daily news need to be more novel to attract audiences, which can be highlighted compared with the microEnv.

We show three cases where the macroEnv and microEnv have different importances. Please see the explanations in the red dashed boxes.

Between the lines
Research on fake news detection has gone so far on the way to more efficient utilization of indicative signals in the social context, which relies much on post hoc information for detecting fake news more accurately. To save time for subsequent mitigation, it is time that we seek new perspectives for detecting fake news right after it is published. By “zooming out” to consider the news environment, this paper takes the first attempt in this direction and the results are promising. Despite this, many issues remain to be studied and tackled in future work. I would like to highlight the following three of them: (1) Construct more diverse “environments” that include the societal background or history; (2) Give a principled way to construct proper and useful news environments; and (3) Extend this type of methodology to multi-modal or social graph-based fake news detection.