


✍️ Original article by Yacine Jernite, Zeerak Talat, Carlos Muñoz Ferrandis, Danish Contractor, and Margaret Mitchell from HuggingFace.
Yacine Jernite is a researcher at Hugging Face working on exploring the social and legal context of Machine Learning systems, particularly ML and NLP datasets.
Zeerak Talat is a post-doc at the Digital Democracies Institute where they are working on machine learning for content moderation and the foundational and philosophical limitations of machine learning.
Carlos Muñoz Ferrandis is a Tech & Regulatory Affairs Counsel at Hugging Face and a Ph.D. candidate focused on the intersection between open source and standards.
Danish Contractor is an AI researcher with a background in Conversational AI and Question Answering Systems.
Margaret Mitchell is a researcher working on Ethical AI, currently focused on the ins and outs of ethics-informed AI development in tech.
This is part of the Social Context in LLM Research: the BigScience Approach series written by participants of several working groups of the BigScience workshop, a year-long research project focused on developing a multilingual Large Language Model in an open and collaborative fashion. In particular, this series focuses on the work done within the workshop on social, legal, and ethical aspects of LLMs through the lens of the project organization, data curation and governance, and model release strategy. For further information about the workshop and its outcomes, we encourage you to also follow:
- BigScience Blog
- BigScience Organization Twitter
- BigScience Model Training Twitter
- BigScience ACL Workshop
Introduction
Who needs to be able to examine new technology? And how may we enable accountability of new technical systems along with responsible use?
The BigScience workshop was structured around the development and release of a large multilingual language model. As described in our previous blog post, its driving values include inclusivity, openness, and reproducibility – i.e. we want language communities to be able to examine and explore the model’s behaviors after the end of the workshop without distinction of location or affiliation. It also prioritizes the value of responsibility and building mechanisms to minimize misuses of the models, whether they come from inherently harmful applications or from a misunderstanding of the model capabilities. We built our release strategy around these two pillars.
- People: the work produced in this domain is focused on model developers, direct and indirect (or active and passive) users of the trained models, and regulators developing new legislation based on documentation of the model performance and uses.
- Ethical focus: The different values that we are aiming to uphold with our release strategy have traditionally been associated with strongly contrasted approaches at either end of the open/controlled release spectrum. While we do not think these values are in opposition to each other, jointly operationalizing them requires further ethical work and grounding choices and mechanisms in specific values.
- Legal focus: Similarly to the data aspect, the legal work surrounding the model release has a dual focus. First, we need to be aware of emerging regulations on the use of AI or ML systems that may be relevant to our model. Second, we identify Responsible AI Licensing (RAIL) as a promising approach to govern uses of the model in a way that upholds all of our driving values, and design such a license as a legal tool to assert community control over potential model misuses.
- Governance: Finally, collaborative governance of the model depends on having a sufficient understanding of its behavior, capabilities, and failure modes supported by transparent evaluation and extensive documentation. We outline our efforts on both of these aspects in the remainder of this post.
Model License
The BigScience model was developed first and foremost as a research artifact, with a stated goal to make research into the properties of LLMs more accessible to a wide range of research actors, and especially to direct and indirect stakeholders who did not participate in its development and may bring different perspectives or suggest new analyses of the models. This motivated us to make the model weights and code broadly available once training is over. At the same time, we recognize that not all uses of the trained model are appropriate or beneficial, and aim to execute this release in a way that reflects these concerns.
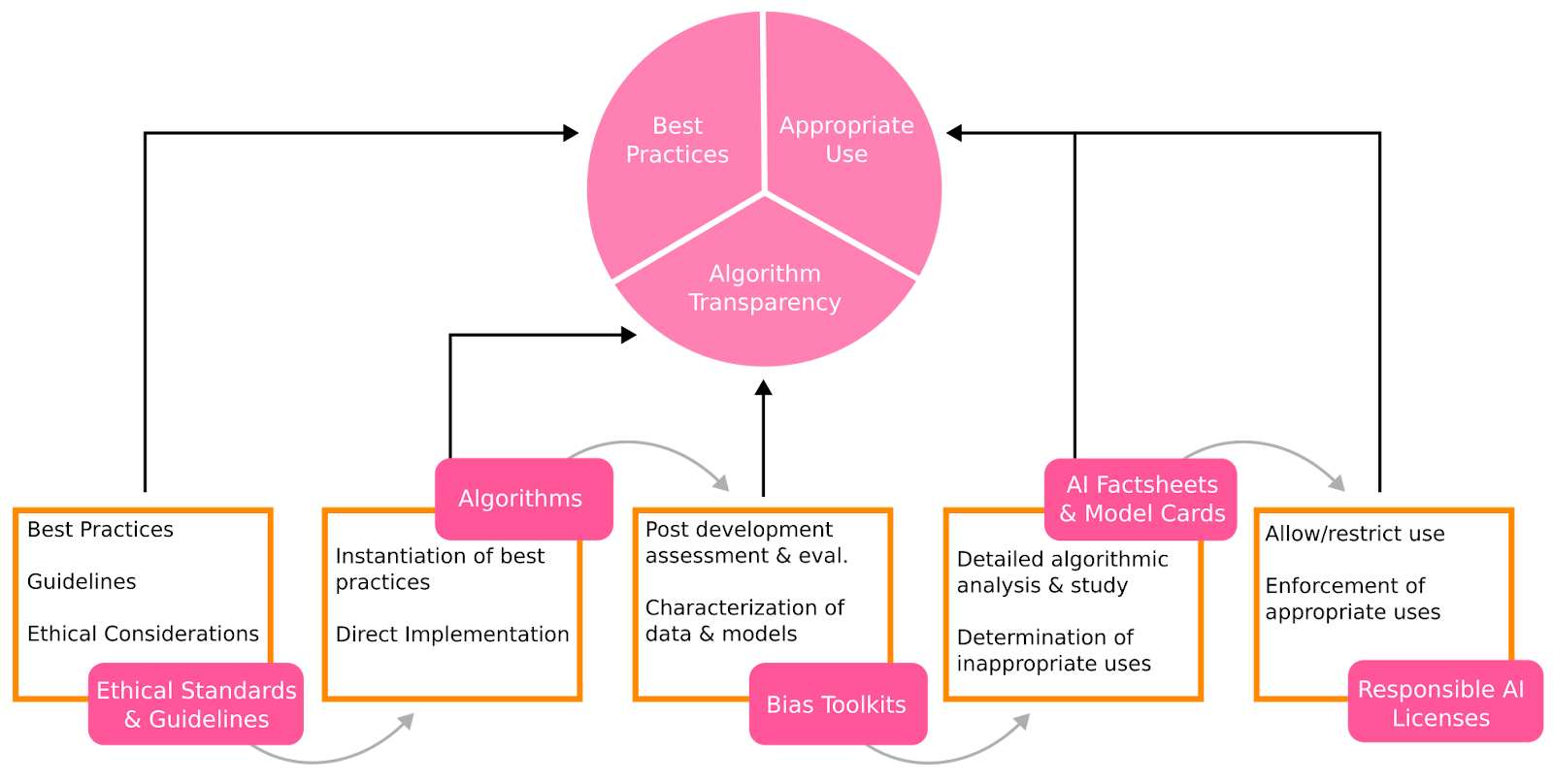
Our initial discussions focused on releasing the model under some form of non-commercial license to limit the potential negative impact of model applications that do not correspond to its intended use; however, while we recognize that the incentive structures defined by commercial applications of LLMs play a significant role in the trajectory of their development, we found that scoping out exactly what constitutes such an application was both elusive and often less relevant to the risk of harms than other aspects of the use case. This reasoning led us to design and adopt our own Responsible AI License for the model release (RAIL), which includes use case restrictions targeting applications that are antithetical to the project’s values or bear a particularly high risk of leading to harm.
Complementary to ongoing regulatory and policy initiatives, the BigScience approach to RAIL is a step toward addressing the growing demand for more concrete actions on AI misuse. BigScience aims at supporting AI researchers and developers striving for responsible use of their models and willing to share their work in the interest of advancing science. The use-based restrictions included in the model’s RAIL license are informed by prohibited uses identified in the Model Card as well as by BigScience multidisciplinary participants’ opinions, scientific evidence, and ongoing regulatory initiatives, such as the EU AI Act (e.g., articles 5, 6 and Annex III). In particular, governance of research artifacts can play a significant role in ex ante evaluation of these initiatives to support the design of future regulations of more widely deployed systems – and we hope that the proposed license will help inform future regulatory efforts. You can read the BLOOM RAIL license here, and find further detail on its design in the attached blog post.
Evaluation of Performance and Biases
Decisions bearing on the release and governance of a language model should be grounded in an extensive understanding of its capabilities and behavior. As with the rest of the workshop, we take an open, collaborative approach to devising a test suite to explore various properties of the model, soliciting proposals for evaluation tasks from the whole BigScience workshop and then running a hackathon to bring them together in a common format inspired by efforts like the EleutherAI LM evaluation harness. We will use this setup to evaluate the model during and after the final phase of training, you can see the evaluation suite in development here. To the best of our knowledge, this is the first such evaluation suite to be multilingual. The aspects of the model it aims to evaluate were split between the following three categories:
- Intrinsic evaluation: intrinsic evaluations aim to characterize the internal workings of the language model, by exploring e.g. how the model represents or leverages syntactic or semantic information.
- Extrinsic evaluation: extrinsic evaluations are focused on performance on potential downstream uses of the model within language technology, including e.g. summarization systems, automatic question answering embedded in user-facing websites, autocomplete-based coding assistants etc.
- Bias and social impact evaluation: these evaluations are focused on surfacing and measuring the severity of harmful biases we suspect the model will exhibit a priori. We understand that these provide a “positive-only” measure that helps surface particularly egregious cases or compare models trained in comparable settings, but do not guarantee the absence of even the categories of biases they focus on.
The latter category merits further consideration. Given the complex ways in which multilingual LLMs may be biased, we found that prior work on bias evaluation was only applicable to our project in limited ways due to focusing on English, specific model architectures, or lacking specification in terms of operationalizing bias. We therefore identified and discussed the different perspectives that are necessary in developing evaluation methods and metrics for multilingual LLMs. We outline the particular ways in which prior work was appropriate and inappropriate for evaluating multilingual LLMs, drawing on a wide array of disciplines including critical race theory, discard studies, social anthropology, science and technology studies, gender and LBTGQIA+ studies, and computer science among others. On this basis, we understand LLMs as socio-technical models that must be understood and evaluated as such.
This framing illuminates the necessity for LLMs to be socially and culturally situated within contexts that they are competent in. Consequently, we argue that for the appropriate evaluation of multilingual LLMs, researchers and practitioners a) must develop resources that are culturally competent, b) be specific around the forms and expressions of social biases that they are evaluating for, c) bear in mind the cultural situation of the LLM within each cultural context. Finally, we call for recognition that LLMs are not developed in a vacuum of social context. That is, current development practices of LLMs are situated within the context of existing systems of marginalization that externalize costs onto communities that are systematically excluded from the development or the benefits of models. You can find more details on our approach and recommentations here.
Model Card Design
We created documentation for the model via a Model Card framework, which requires outlining the basic model architecture and training parameters, the foreseeable uses and users, and evaluation protocols relevant to how the model will be used in practice. The creation of the card involves working through problematic misuse and out-of-scope applications, as well as identifying metrics that are important for measuring disproportionate errors for different subpopulations. The process of creating the card further informed the kinds of evaluations most useful for the model, and which use cases should be prohibited.
Where the RAIL License aims to start providing a legal framework for governing model uses and steering them away from known harmful applications, the Model Card takes a broader view of gathering information that may be relevant to understanding how the model behaves, in particular for audiences that weren’t directly involved in the model design. It is designed to be a living document, updated whenever e.g. the model is evaluated on new tasks, or when additional information becomes otherwise available.
The Model Card can be found here.
Conclusion
Designing a model release strategy that jointly prioritizes openness and responsibility is not only desirable, it is necessary to ensure that we can keep addressing all categories of harms that may come about from using LLMs with foresight and the expertise of all affected populations – giving civil society a more significant avenue to shaping the technology’s evaluation and governance.
Our proposal to that end relies on a combination of descriptive and normative tools. We investigate and present the capabilities and likely limitations of the model through extensive evaluation, and write a model card that will keep evolving to summarize the results of this process as they become available. We also design a new open science license with use case restrictions for the model to dissuade applications that are known to be harmful or bear a high risk of causing harm.
The work presented here corresponds to efforts coordinated by the BigScience Ethical and Legal Scholarship, Model Card, and Evaluation Working Groups, including the Social Impact and Biases Evaluation Working Group.
Social Impact of LLMs at BigScience: Closing Notes
This article is the last of our series outlining the many aspects of the BigScience research project that were instrumental in accounting for the social context and societal impacts of the development and adoption of Large Language Models, from the project guiding values and organization to the training corpus curation and governance to its model release strategy.
Throughout this work, we prioritized two approaches that we saw as essential to the long-term impact and validity of the project: multidisciplinary research combining legal, ethical, and social perspectives with the extensive technical expertise of the workshop participants, and prioritizing releasing intermediary research artifacts and documentation that would enable others to pick up where we left off after the end of the BigScience model training.
As this 1000-strong collaboration winds down in its current form, we strongly encourage new collaborations to form and continue this work, especially on aspects that require multidisciplinary collaboration and new categories of expertise and can help shape our understanding of this new technology to benefit more direct and indirect stakeholders. We hope that our open approach will enable research projects in the years to come, and look forward to learning from future projects leveraging the outputs of this Workshop!