

🔬 Research Summary by Eike Petersen, a Postdoc in the Department of Applied Mathematics and Computer Science in Visual Computing.
[Original paper by Eike Petersen, Yannik Potdevin, Esfandiar Mohammadi, Stephan Zidowitz, Sabrina Breyer, Dirk Nowotka, Sandra Henn, Ludwig Pechmann, Martin Leucker, Philipp Rostalski, Christian Herzog]
Overview: To ensure that fundamental principles such as beneficence, respect for human autonomy, prevention of harm, justice, privacy, and transparency are respected, medical machine learning systems must be developed responsibly. This survey provides an overview of the technical and procedural challenges that arise when creating medical machine learning systems responsibly and following existing regulations, as well as possible solutions to address these challenges.
Introduction
The potential of modern machine learning techniques to improve clinical diagnosis and treatment and unlock previously infeasible healthcare applications has been thoroughly demonstrated. At the same time, the risks posed by the application of medical machine learning (MML) have become apparent. Notable examples of critical problems include
- a system diagnosing hip fractures mainly based on patient characteristics and hospital process variables, almost regardless of the patient’s X-ray recording,
- improper performance evaluation methodology leading to widely exaggerated performance claims for clinical prediction models, and
- racial bias in an algorithm that computes a health risk score and is used to assign healthcare system resources in the US.
Partially driven by these and other similar incidences, the regulation of MML systems is evolving rapidly, with many actors participating in the discussion by publishing discussion papers about ethical requirements, developing technical standards, and proposing or implementing hard law changes. As opposed to other machine learning application domains, however, medical device regulations already today place a heavy burden of regulatory requirements on MML systems. Combined with general data protection regulations and antidiscrimination law, a comprehensive set of requirements on the safety, robustness, security, privacy, transparency, and fairness of MML systems emerges.

Figure 1. Medical machine learning lies at the intersection of medicine and machine learning and is subject to regulations and ethical considerations regarding both fields. From Petersen (2022), CC-BY 4.0.
The main part of this survey aims to answer the following two questions:
- Which technical and non-technical obstacles prevent us from realizing MML systems with these desirable properties?
- Which potential solutions have been proposed for overcoming these obstacles, and what are their respective advantages and disadvantages?
Key Insights
Safety, Robustness, and Reliability
Medical technology directly or indirectly affects patient health and must comply with strict safety requirements. Failures must be prevented, detected if they occur, and mitigated to ensure patient safety. In ML-based medical systems, model robustness and reliability represent essential requirements for failure prevention. Unfortunately, these properties are challenging to quantify because test set accuracy often does not predict real-world performance due to distribution shift, model underspecification, test set label errors, or purely internal validation (i.e., i.i.d. testing).
Key ingredients to achieve robust and reliable model performance include
- the use of large, representative datasets (which may be aided by employing federated learning methods, synthetic data augmentation, or automated labeling schemes),
- the incorporation of prior knowledge about the class of reasonable models,
- extensive out-of-distribution testing, and
- avoidance of data leakage.
Transparency plays a unique role, increasing robustness and reliability throughout all stages of the MML system, and will be discussed in detail further below.
Developers should also consider measures to increase the safety of the entire system, such as operator training, fail-safe user interface design, and automated verification of safe operating conditions. Such usability engineering methods are required by medical device regulations as a risk mitigation strategy, and MML developers can draw on decades of experience in this field.
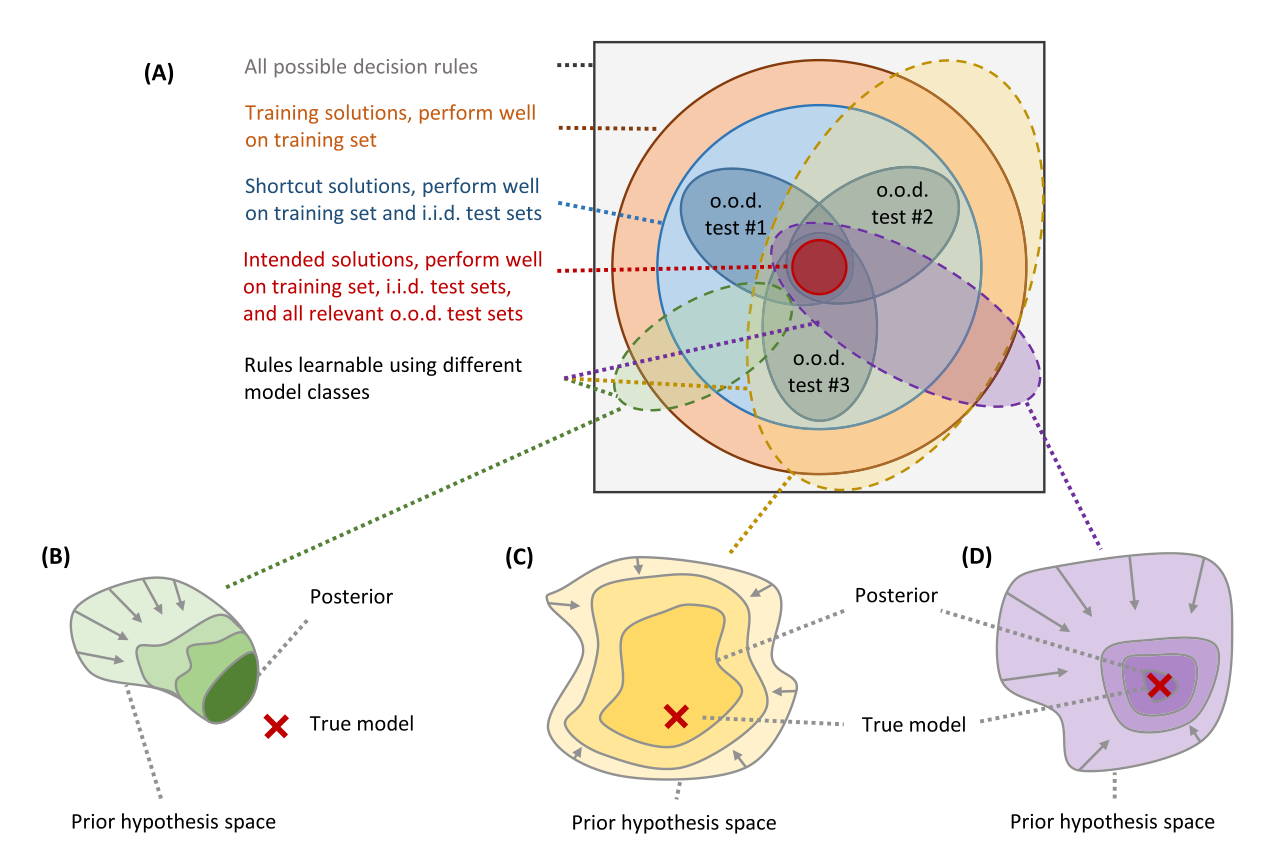
Figure 2. (A) Models that perform well on the training dataset need not perform well on the test dataset, and those performing well on the test dataset still need not perform well in the real world for reasons including dataset shift, spurious correlations, and model underspecification. Independent identically distributed (i.i.d.), out of distribution (o.o.d.). (B) A model class with a too restrictive hypothesis space prevents convergence towards the true model. (C) A model class with inadequate inductive biases renders convergence towards the true model inefficient, requiring lots of data. (D) A model class must cover a sufficiently large hypothesis space that includes the true model, it must be equipped with adequate inductive biases, and there must be sufficient data to enable convergence towards the true model. From Petersen (2022), CC-BY 4.0.
Privacy and Security
Medical machine-learning applications demand an exceptionally high degree of data privacy and application security. Beyond classical privacy and security measures, this necessitates guaranteeing the privacy and security of the employed ML methods. While providing (possibly restricted) public access to the MML system is unavoidable if it is to be used in practice — users must at least be able to provide inputs to the system and receive model predictions in return — it should at no point during the system’s lifecycle be possible for an outsider to extract sensitive patient data. Moreover, malicious actors must be prevented from negatively influencing the outcome of the training process or a particular prediction.
To solve the problem of medical data silos while maintaining patient data privacy, distributed learning frameworks such as federated and split learning appear promising. Since, in this case, the data collection and training processes are not entirely trusted, countermeasures against backdoor injections may be necessary, such as deploying outlier detection methods.
During deployment, security and privacy concerns appear to be relatively limited for MML models only accessible by authorized personnel. However, in scenarios with more widely distributed access, models should be protected from direct access due to privacy concerns (data extraction attacks). For MML models that are remotely accessible to a broader audience or for Edge AI applications, a limited query rate, robustness-enhancing training methods, and privacy-preserving learning methods should be considered. It is advisable to evaluate the security and privacy properties of such a model using popular penetration testing frameworks.

Figure 3. Many different communication schemes have been proposed for data collection, model training, and model deployment. All of them have merits and drawbacks and are preferable under different circumstances. Centralized training and deployment is the current standard scheme in ML. The depicted decentralized training scheme corresponds to (horizontal) federated learning; the depicted decentralized deployment scheme is often called ‘Edge AI’. (For decentralized training, a central coordinator is not strictly necessary: completely decentralized approaches have been proposed as well.) From Petersen (2022), CC-BY 4.0.
Transparency and Explainability
Transparency encompasses the open communication of some or all factors that influence the decision-making process of an MML model. However, more than transparency is needed to guarantee comprehension on the part of the information recipient: Making the full structure and weights of a deep neural network openly available is unlikely to significantly increase end-user comprehension. Thus, for many purposes, explainability must be a second goal: Can we explain the provided information in understandable terms?
There is a broad consensus that transparency and explainability are crucially important for achieving safe, robust, reliable, and fair MML systems.
Among others, these comprise
- transparency regarding the data used for training a model and its characteristics and limitations,
- transparency for the model and its development process,
- the real-world performance of the model across different groups of patients,
- the uncertainty of model predictions,
- explanations of the model as a whole, and
- explanations of the most important factors influencing an individual model prediction.
Data-based explanations of model behavior, such as model predictions for group prototypes and adversarial or influential examples, can help assess model robustness and reliability and inform continuous model improvement. In a similar vein, the generation of counterfactual examples represents an attractive explanatory mechanism that is applicable in many domains. Post hoc explanation methods, such as saliency maps and LIME, can be used to explain the decisions of otherwise opaque models. However, due to their approximate and local nature, they can be inaccurate or misleading and should only be used with great care in the medical domain. It has been demonstrated in multiple studies across various domains that intrinsically interpretable model classes can achieve the same performance as black-box models while providing exact explanations of model predictions; such models should thus be preferred where feasible. Finally, explanations must always be tailored to a particular stakeholder group and use case: explanation design is a highly interdisciplinary endeavor that should involve the relevant stakeholders from the beginning.
Algorithmic Fairness and Nondiscrimination
Prominent examples of biased machine learning systems include grave disparities in the error rates of chest radiograph diagnosis systems between different groups of patients and an algorithm used to assign US healthcare resources to patients discriminating against black patients. Ethics, nondiscrimination law, and technical accuracy and reliability requirements all require medical machine learning (MML) systems to treat patients fairly. But what exactly constitutes a “fair” MML system, and why are unfair biases so prevalent?
Different medical applications demand different definitions of fairness: while a healthcare resource allocation algorithm probably should not take sensitive attributes into account, a disease or treatment prediction algorithm should. Moreover, compared to other application domains, diagnostic performance for one group of patients should be preserved to achieve equal performance across groups. Instead, the aim must be to achieve optimal performance for each individual group. A related challenge concerns the difficulty of identifying the groups that are relevant for fairness considerations in the first place. These groups depend on the application at hand and societal norms. For example, native and non-native speakers may form fairness-relevant groups in applications related to text generation and understanding but not in many others. Hidden stratification, i.e., disparate performance on indistinguishable subgroups based on the given data, represents another obstacle.
Much technical research has been devoted to optimizing different mathematical fairness characterizations before, during, or after model training. While these can represent important building blocks of a fair MML system, the fairness of a whole system will generally require a much richer and broader perspective than can be captured in simple statistical metrics. Most practical problems are characterized by particular biases and complexities that require special consideration and are often not foreseeable in the early stages of a project. Challenges such as (group-specific) measurement biases may even be fundamentally only possible to address with further targeted data collection efforts.
Overall, there is no simple technical fix to the ‘fairness problem’. A (reasonably) fair machine learning model will likely result from persistent stakeholder involvement, targeted data collection, resampling methods or synthetic data generation, maybe a fairness-aware learning method, and monitoring for potential biases throughout the ML lifecycle. Achieving algorithmic fairness will often be an iterative process, with new fairness-related challenges surfacing during project execution and being addressed in an ongoing fashion.
Finally, fairness is closely related to transparency, explainability, robustness, and reliability. Fairness metrics essentially represent transparency and explainability tools specifically tailored toward investigating fairness-relevant model properties. If a model performs equally well across all relevant patient groups, it may be considered reliable and fair (at least according to this particular fairness conception).
Between the lines
This survey provides an in-depth overview of the many facets of responsible and regulatory conform medical machine learning (MML) and attempts to translate high-level ethical requirements into practical technical challenges and potential solutions. Currently, MML systems are subject to a wide array of regulations demanding robustness, safety, security, privacy, transparency, and nondiscrimination. Creating systems that achieve all these desirable properties in practice remains a highly challenging undertaking, however. None of the previously mentioned properties will be achieved through simple technical “fixes”; instead, multifaceted and application-specific solutions are required. Successful approaches will combine stakeholder participation, targeted data collection and curation, technical innovations in model design and training, and comprehensive performance testing and reporting. Zooming out from a narrow, model-centric view and considering the interaction of the whole technical system with its human recipients – be it doctors, patients, or society – will be crucial to succeed in the endeavor for responsible and regulatory conform medical machine learning systems.