

🔬 Research Summary by Ahmad Faiz, Masters in Data Science student at Indiana University Bloomington.
[Original paper by Ahmad Faiz, Sotaro Kaneda, Ruhan Wang, Rita Osi, Parteek Sharma, Fan Chen, and Lei Jiang]
Overview: This paper delves into estimating the carbon footprint of Large Language Models (LLMs), spanning their complete lifecycle, including training, inference, experimentation, and storage phases, encompassing both operational and embodied carbon emissions. It specifically focuses on the challenge of accurately projecting the carbon impact of emerging LLMs during GPU-intensive training. To address this, the paper introduces LLMCarbon, a framework for modeling carbon footprints in dense and Mixture-of-Experts (MoE) LLMs. LLMCarbon markedly improves the precision of carbon footprint estimations for various LLMs, overcoming significant limitations in existing tools like mlco2. This enables efficient design space exploration by considering the trade-off between carbon footprint and test loss across LLM configurations.
Introduction
Patterson et al.’s paper “Carbon Emissions and Large Neural Network Training” reports 552.1 metric tons of gross equivalent carbon emissions for the famous GPT-3 model trained on NVIDIA V100 GPUs. To put it in context, this is equivalent to a round trip of 3.05 jet plane carbon emissions between San Francisco and New York. With the proliferation of these large models in everyday life, its substantial carbon footprint is a critical concern. This paper introduces LLMCarbon, a comprehensive modeling tool to predict and evaluate the carbon impact of LLMs at different stages of their lifecycle.
LLMCarbon considers various inputs, including architectural details of the LLM, data center specifications, and hardware configurations. It employs a series of models to process this information, including a parameter model to estimate the LLM’s parameters, the neural scaling law to predict test loss, a FLOP model to estimate processing volume, and a hardware efficiency model to calculate actual computing throughput. Furthermore, LLMCarbon incorporates operational and embodied carbon models to provide a holistic view of an LLM’s carbon footprint.
Through rigorous validation, we confirm LLMCarbon’s accuracy in estimating both the operational and embodied carbon footprints of LLMs. In operational phases, our tool demonstrated disparities of 8.2% or less when compared to actual data, surpassing existing tools in precision. Moreover, LLMCarbon’s estimations of embodied carbon footprints closely align with publicly available data, showcasing an error margin of less than 3.6%. These findings highlight LLMCarbon’s invaluable role in guiding the development and usage of LLMs towards a more sustainable and environmentally conscious AI future.
Key Insights
To comprehend the carbon footprint of LLMs, it’s essential to consider emissions at different phases, including training, inference, experimentation, and storage. This includes both operational carbon emissions generated during usage and embodied carbon emissions associated with producing hardware components. LLMCarbon relies on a series of models to process a range of inputs, including architectural information about the LLM, data center specifications, and hardware configurations. These models are listed below:
1. Parameter Model: Estimate the parameter count based on architectural parameters such as hidden size, the number of layers, vocabulary size, and the number of experts for dense and MoE models.
2. Neural Scaling Law: Neural scaling law predicts an LLM’s test loss based on its parameter count and the training dataset size. This allows for consistent comparison of test losses across various LLMs.
3. FLOP Model: The FLOP model calculates the number of floating-point operations (FLOPs) required during LLM processing, using the parameter count and the number of tokens processed, which is used to understand computational requirements.
4. Hardware Efficiency Model: LLMcarbon provides valuable insights into identifying the optimal parallel settings across data, tensor, pipeline, and expert dimensions that should be followed to achieve peak throughput and resource utilization.
5. Operational Carbon Model: LLMCarbon quantifies the carbon emissions generated during LLM processing. It considers the FLOP count, hardware efficiency, and the number of computing devices used. Additionally, it factors in variables like the data center’s power usage effectiveness (PUE) and carbon intensity, ensuring a comprehensive assessment of carbon impact.
6. Embodied Carbon Model: The embodied carbon model quantifies the carbon footprint associated with hardware components. It calculates the carbon emissions for each unit, considering factors like chip area and Carbon emitted Per unit Area (CPA).
The total equivalent carbon emission is the sum of operational and embodied carbon emissions.
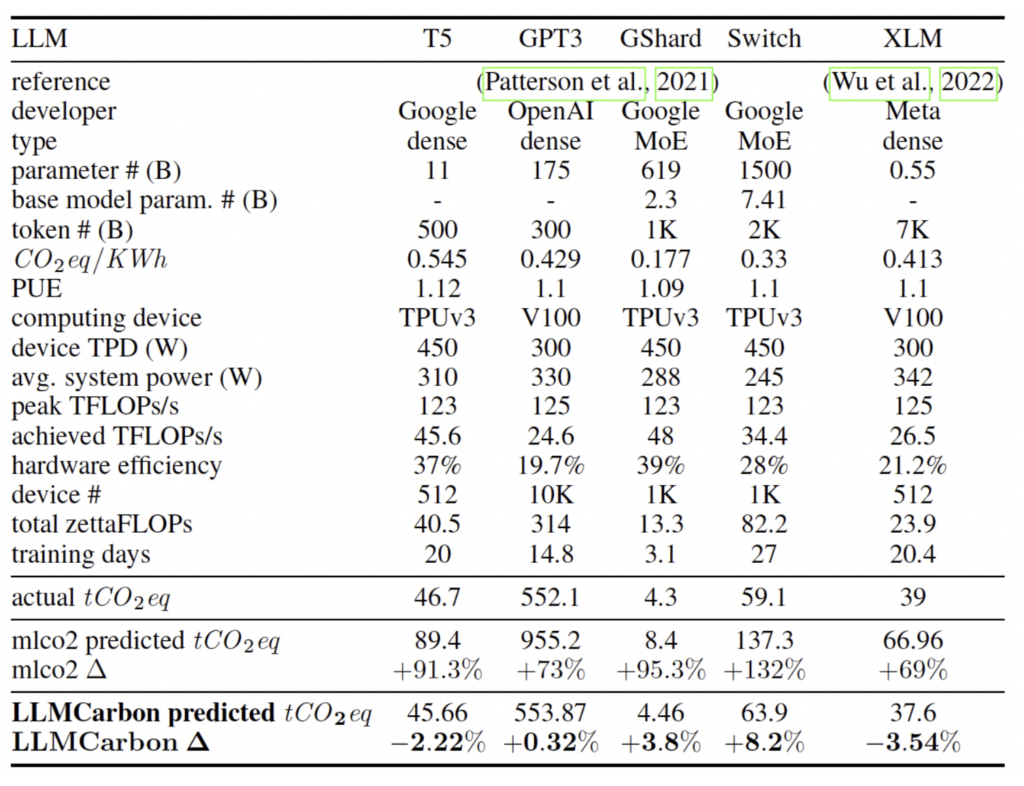
The validation results reveal a remarkable alignment between LLMCarbon’s projections and real-world data for diverse LLMs, surpassing the performance of existing tools like mlco2. LLMCarbon’s adaptability to various data center specifications and its capability to pinpoint optimal parallelism settings enhance overall operational efficiency. This adaptability, combined with its ability to accurately gauge the environmental impact of LLMs, positions LLMCarbon as a pragmatic tool in assessing and mitigating the carbon footprint associated with LLMs, offering an indispensable resource for the future of sustainable AI development.
Between The Lines:
In the broader context of the ML community’s growing concern about the carbon footprint of computationally intensive models, it is crucial to underline the significance of tools like LLMCarbon. We suggest three key areas for improvement: explicitly reporting energy consumption and CO2eq, rewarding efficiency improvements alongside traditional metrics in ML conferences, and providing insights into the time and number of processors used during training.
By employing LLMCarbon or similar tools, researchers and developers can report the carbon footprint more accurately and consider it a competitive factor in model training. This shift in perspective could promote a virtuous cycle where efficiency and reduced emissions become paramount. Integrating power metrics into benchmarks like MLPerf is a positive step in the right direction, fostering a more sustainable approach to AI development. Further research is needed in these areas to solidify these goals and push for ongoing improvements in the industry’s carbon footprint.