

🔬 Research Summary by Matthew Barthet, a Ph.D. student researching artificial intelligence and games at the Institute of Digital Games, University of Malta.
[Original paper by Matthew Barthet, Chintan Trivedi, Kosmas Pinitas, Emmanouil Xylakis, Konstantinos Makantasis, Antonios Liapis, and Georgios N. Yannakakis]
Overview: Collecting human emotion data reliably is notoriously challenging, especially at a large scale. Our latest work proposes a new quality assurance tool that uses straightforward audio and visual tests to assess annotators’ reliability before data collection. This tool filters out unreliable annotators with 80% accuracy, allowing for more efficient and clean data collection.
Introduction
Reliably measuring human emotions has always been a pivotal challenge in affective computing and human-computer interaction. At its core, this issue boils down to the fact that emotions are highly subjective and loosely defined responses to stimuli, making them very challenging to annotate reliably. To make matters even harder, collecting such data is often very expensive, time-consuming, and cognitively demanding for annotators, making collecting labels at a large scale highly impractical.
To address these challenges, we’ve designed a novel annotator Quality Assurance (QA) tool that swiftly and efficiently assesses the reliability of participants before data collection. We tested this tool on an interesting challenge where participants were recruited to annotate their engagement in real-time while watching videos of 30 different first-person shooter games. The results highlighted two main findings. The first was that unsurprisingly, trained annotators in a controlled environment were consistently more reliable than crowdworkers. The second and more crucial finding is that our QA tool achieved an impressive 80% accuracy for predicting annotator reliability in subsequent affect tasks. This validates its ability to filter unreliable participants and ensures the data collection process is more efficient and yields higher-quality data.
Key Insights
Knowing Your Annotator
Rapidly testing the reliability of subjective annotators.
Our Quality Assurance (QA) tool allows researchers to better understand the reliability and characteristics of their annotators. Due to the subjectivity of human emotions, there is ultimately no correct answer as to how one is expected to feel at any given moment. Therefore, understanding whether your annotators are just feeling differently from one another or are not annotating their emotions correctly (i.e., unreliably) is vital when processing your data.
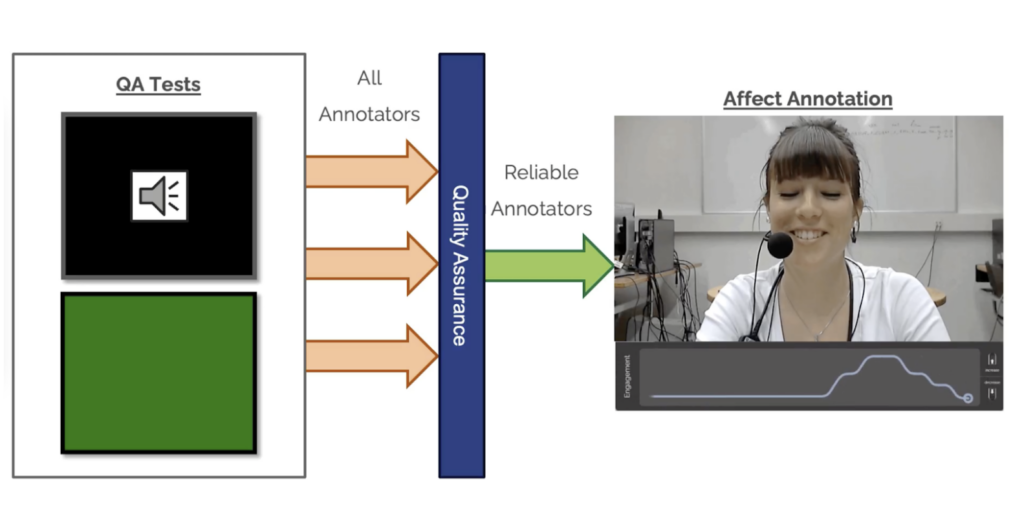
With this challenge in mind, we have developed two QA tests to quickly assess an annotator’s reliability through basic stimuli where the correct answer is known. They are designed to test how well a person can respond to audio and visual stimuli in a timely manner and ensure they are using the correct hardware setup for the experiment. The tool is built upon the PAGAN annotation platform and RankTrace, where participants watch a video and annotate how they feel in real-time by scrolling up/down on a mouse wheel.
Visual QA Test
Drawing on inspiration from previous work, our first QA test requires annotators to mark changes in the brightness of a green screen. The tool presents the user with a 1-minute video showing a green screen with a slowly fluctuating brightness. Participants use the mouse wheel to annotate the changes in brightness they observe. The goal is for the participant to accurately replicate the signal driving the changes in color on the screen. The more closely they replicate it, the higher their reliability score.
{kind=link}
Audio QA Test
Expanding on the above, the second QA test focuses on auditory stimuli. This time, the participants are shown a blank screen while a 1-minute sound clip is played where the frequency (or pitch) changes slowly over time. Once again, the participant must annotate the changes in frequency they perceive by scrolling on the mouse wheel. The closer they replicate the frequency signal used in the audio clip, the better their reliability score. This second test was included as our subsequent data collection focused on annotating audiovisual content; therefore, testing the participants on both modalities is vital. This also ensures that participants not in a controlled setting use the correct setup, such as using a mouse wheel (not a trackpad) and headphones to pick up on subtle audio cues.
Case Study: Annotating Engagement in Games
To validate the predictive nature of our tool, we conducted a case study on annotating viewer engagement in first-person shooter (FPS) games. We assembled a dataset containing video clips of 30 different FPS games, selecting games with different graphical styles (e.g., cartoon, realistic) and different levels of detail. Annotators were asked to annotate their engagement in 30 minutes of footage (1 minute per game) presented randomly after completing the QA tests.
Since we don’t have a ground truth signal for emotions to compare to, we approximate the annotators’ reliability by seeing how well they agree with one another as a group. We tested two different groups of annotators. The first is a group of 10 “Experts” who were trained students/researchers who were brought into our research lab and provided with the necessary hardware to complete the study. The second group comprises 10 “Crowdworkers” recruited using Amazon’s Mechanical Turk platform. The goal is to compare the reliability of the two groups and observe how well the tool can filter out unreliable annotators using their average reliability in the QA tests.
The results for the above goals highlighted two main findings. The first was that unsurprisingly, expert annotators in our research lab were consistently more reliable than crowdworkers. More crucially, our QA tool achieved an impressive 80% accuracy for predicting annotator reliability in our engagement study, validating its ability to filter unreliable participants and ensure we collect cleaner data more efficiently.
The QA tests used in this study, the dataset of FPS videos, and the annotated engagement labels (the collection is ongoing) are available on our GitHub repository at: https://github.com/institutedigitalgames/pagan_qa_tool_sources. We are working on an automated version of this tool for the public and will be added to PAGAN in the near future.
Between the lines
This work takes some important initial steps to make large-scale affect data collection more feasible and understandable for researchers. It enables researchers to save time and resources by only allowing the best quality annotators to complete their study, and it also ensures the data collected is of the best possible quality. This is a critical and long-standing goal in affective computing and will help foster the creation of better and larger corpora.
There are many directions for future development here. We are testing our QA tool on more participants and gathering more engagement data to validate our findings further and build upon our dataset. We are also looking into different annotation protocols for maximizing annotators’ reliability, different approaches for measuring reliability, and ways of filtering unreliable annotators (e.g., by using machine learning).