


🔬 Research Summary by Christopher Teo, a fourth year PhD student at the Singapore University of Technology and Design (SUTD).
[Original paper by Christopher T.H.Teo, Milad Abdollahzadeh, and Ngai-Man Cheung]
Christopher TH Teo, Milad Abdollahzadeh, Ngai-Man Cheung. Fair Generative Models via Transfer Learning. Proceedings of Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI-2023).
Overview: With generative AI and deep generative models becoming more widely adopted in recent times, the question of how we may tackle biases in these models is becoming more relevant. This paper discusses a simple yet effective approach to training a fair generative model in two different settings: training from scratch or adapting an already pre-trained biased model.
Introduction
Generative AI and generative models, e.g., Generative Adversarial Networks (GANs), are becoming more widely adopted. Due to the tremendous improvement in sample realism, researchers are utilizing these generated samples to supplement scarce datasets or even other applications such as criminal suspect face generations. Furthermore, with the introduction of simple-to-use text-image generators, e.g., DALL-E, Stable Diffusion, and MidJourney, image generators are becoming increasingly accessible to the general public for artistic interpretation or even concept brainstorming in architecture. With this increased utilization of generative models, fairness becomes increasingly important and critical.
It turns out that due to existing biases with respect to certain sensitive attributes, the use of these generative models can actually be harmful to downstream tasks and may even exacerbate certain social biases. For example, training a downstream disease diagnosis model with supplementation of data from a biased generative model with respect to the sensitive attribute gender observes performance degradation. Furthermore, given that the generated samples are unlabelled in most cases, debiasing the generated samples is not a trivial task.
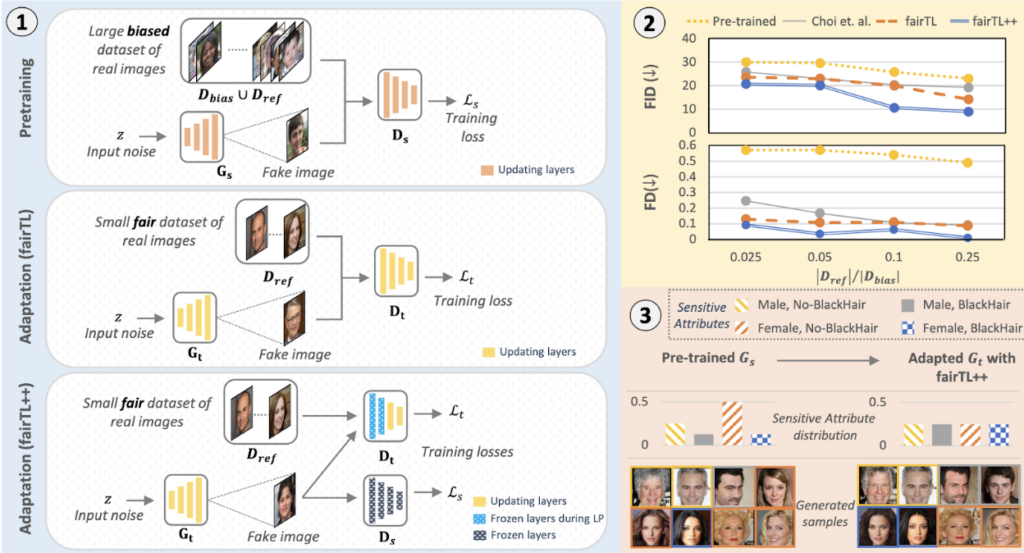
In our recent work, Fair Transfer Learning (FairTL), we propose a simple yet effective manner to either train from scratch or adapt an already pre-trained generative model with a small, fairly distributed dataset with respect to some sensitive attribute. By doing so, we can improve generative models’ efficacy by outputting high-quality, diverse, and fairly distributed samples. This, therefore, improves the efficacy of generative models, e.g., allowing them to be a reliable source of data supplementation.
Key Insights
Fairness in generative models
What is fairness?
In generative models, the most common definition of fairness is the uniform distribution of some sensitive attributes. For instance, a sensitive attribute can be Gender (for ease of discussion, we assume this classification to be binary, i.e., Male/Female). Then a generative model is deemed fair when there is a similar probability (50%/50%) of outputting both Male and Female samples.
Why are generative models unfair?
Unfairness in generative models can occur due to several factors, where most works point to data bias as the main factor. More specifically, given that generators such as GANs are trained to learn to follow the data distribution of the training dataset, if the dataset were to be unfair (skewed towards a certain class in the sensitive attribute, e.g., Males), the generative model would also learn a similar bias.
Difficulty in correcting debiasing generative models
One main difficulty in correcting unfairness in generative models is that both the large training data and generative data are unlabelled. As a result, correcting for this data bias is non-trivial. Furthermore, in some cases, the constraints are even tighter, e.g., when only the pre-trained generative model is available with no access to the large training dataset.
Fair Transfer Learning Approach
Approach
To address these difficulties, we propose using a small fair dataset to debias the generative models (pre-trained or trained from scratch). This small fair dataset can be attained through good practice in data collection. We remark that this practice is often limited to a small dataset, as it is extremely tedious to conduct on a large scale.
Then, using this small dataset, we apply transfer learning – a technique that involves preserving pre-learned knowledge while adapting to a new task. Specifically, we attempt to retain the high-quality but biased samples learned by the generative models from the large biased dataset while training on the small fair datasets to correct for the unfair sensitive attribute distribution. We then further improve the performance of fair transfer learning by introducing multi-feedback and Linear-Probing, then Fine-Tuning the training algorithm. Specifically, multi-feedback takes advantage of the knowledge from the pre-trained discriminator (responsible for the sample’s quality control) to ensure that the sample’s quality does not degrade during fair transfer learning. Then, Linear-Probing the Fine-Tuning helps to stabilize the model’s layer adaptation during training by first freezing the general layers while adapting only the sensitive attribute-specific layers, i.e., layers of the model that control the expression of the sensitive attribute. This is followed by training all the remaining layers to fully adapt to the fair dataset.
Results
Overall through stringent experimentation, our fair transfer learning approach is very effective in training fair generative models. Furthermore, our proposed method introduces an added computation efficient advantage due to its ability to debias already well-trained pre-trained generators, a task previous approaches could not tackle.
Future works can use this simple yet effective approach to improve the application efficacy when utilizing generative models.
Between the lines
This article presents our work on fair generative models, summarizing our research on fair transfer learning. However, there is still a lot of research to be conducted on fairness in generative models. For instance, selecting sensitive attributes may be tricky as many can defer based on differing perceptions, e.g., Attractiveness. Furthermore, most works focus on binary sensitive attributes, however, in some cases, sensitive attributes may be continuous, e.g., Gender can be ambiguous when a sample does not fit into a traditional notion of either female or male.