

🔬 Research Summary by Francois Hu & Philipp Ratz.
François Hu is a postdoctoral researcher in statistical learning at UdeM in Montreal.
Philipp Ratz is a PhD student at UQAM in Montreal.
[Original paper by François Hu, Philipp Ratz, and Arthur Charpentier]
Overview: Ask a group of people which biases in machine learning should be reduced, and you are likely to be showered with suggestions, making it difficult to decide where to start. To enable an objective discussion, we study a way to sequentially get rid of biases and propose a tool that can efficiently analyze the effects that the order of correction has on outcomes.
Introduction
Fairness is a multifaceted issue, making deciding which factors should be considered fairness-sensitive difficult. Take the recent US Supreme Court ruling that race can no longer be considered on a specific basis in college admissions. In the wake of the decision, another suit was launched, aiming to end the practice of legacy admissions because such information is discriminatory. Without going into the debate of the rights and wrongs of specific policies, multiple variables should be considered when assessing fairness. Recently, a range of techniques to correct algorithmic biases have been proposed. However, they mostly aim to achieve fairness concerning a single variable. In this article, we study the scenario where fairness is imposed across multiple variables and find that the order of inputs does not matter – correcting for one sensitive variable and then the other or vice-versa results in the same outcome. This insight allows us to examine the effects on subgroups and conduct an impact analysis if not all sensitive variables can be considered.
Key Insights
Context on Algorithmic Fairness
News portals are filled with stories of algorithmic predictions going awry due to the reinforcement of harmful stereotypes often found in the training data. Although the algorithms were not trained to be sexist or racist, they reinforce the biases as it allows them to discriminate (in the optimization sense) and increase their accuracy. If non-discriminatory outcomes are desired from machines, they need to be demanded explicitly or – to quote Melvin Kranzberg – technology is neither good nor bad, nor is it neutral. An important detail is that this behavior is observed even if the sensitive variable is excluded in the modeling process, as algorithms can learn to proxy for its effect using other variables. Algorithmic Fairness is the field of research concerned with identifying and mitigating these biases. Here, we assume that there are scores from a machine learning model that, given a sensitive attribute (for example, gender or race), produce different predictive distributions. The goal is then to create predictive distributions that are indistinguishable across different values of the sensitive attribute.
Fairness Gerrymandering
Put simply, gerrymandering is the process of adverse usage of a system designed with good intentions to advance one’s own goals. For Algorithmic Fairness, this roughly translates to the practice of only considering specific sensitive features in the data to either avoid scrutiny of the algorithm or exaggerate the issues (depending on one’s agenda). To prevent such a selective approach, we want to consider the influences of each sensitive variable and how correcting for one but not the other influences a global measure of unfairness (instead of the local, single-variable-based assessments that are currently the standard).
A slightly more technical view
If there are obvious benefits to having fair predictions, why are they not adapted in a widespread manner? The answer lies in the predictive accuracy of the algorithms – if we have to change the predictions to achieve fairness, they will necessarily not be optimal in the accuracy sense. Therefore, most approaches in Algorithmic Fairness focus on providing predictions that are fair but have the smallest changes with respect to the original scores.
However, most approaches focus on the elimination of a single sensitive feature. A possibility to extend this to multiple sensitive features would be to combine them into a single multi-class vector and employ the standard approach. The issue with this approach is that the estimation will suffer as the intersection of groups necessarily creates minimal subgroups, giving rise to rare class problems. Our main technical insight is that eliminating biases sequentially yields the same results, no matter the correction order. This should allow us to estimate the fair scores with greater precision (in terms of fairness) as we do not need to rely on small groups in the estimation process. This also implies a significant computational advantage – the fairness framework does not need to be retrained when new factors, like new needs or regulatory changes, need to be considered.
Given this result, we can also run a practical impact analysis on how outcomes change globally if not all sensitive variables can be considered. After all, correcting for all features in the data would result in the same prediction for everyone. Fair in a sense but not desirable from many other perspectives and certainly difficult to justify in legislation. The impact analysis then allows users to prioritize which factors should be considered first due to their overall effect.
A Real Life Example
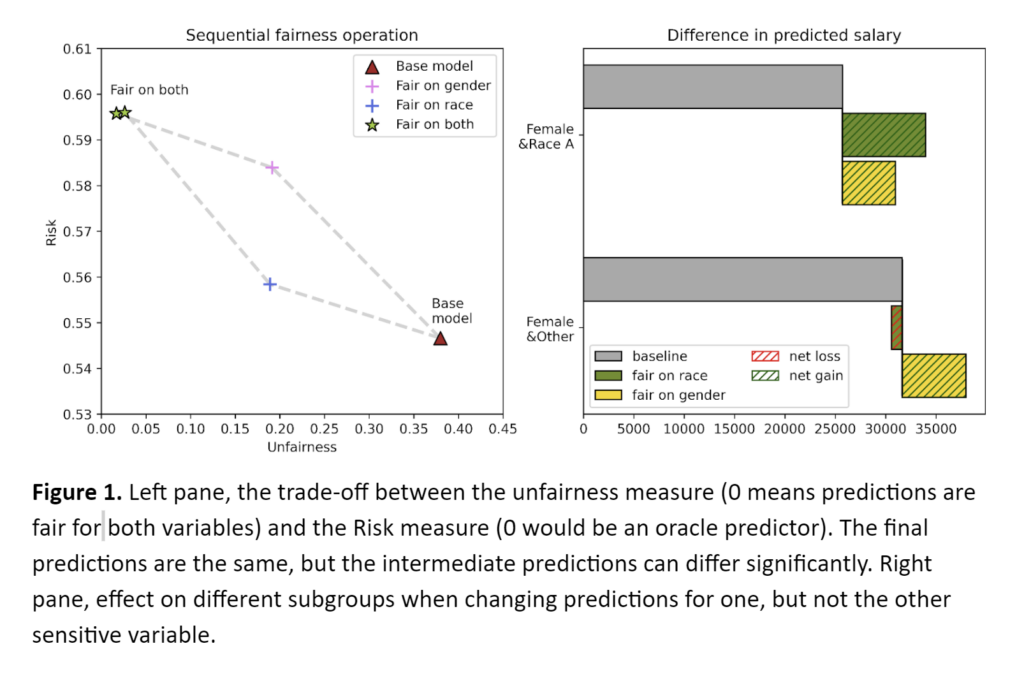
To illustrate how this affects real-life decisions, consider the example where we run wage predictions. It is well documented that, on average, there is harmful discrimination for people of ethnic minorities and women. But what about the effect on subgroups? Correcting for either variable should be beneficial for women of ethnic minorities, but what about women from the majority group? Our methodology shows that the result after correcting for both features will be the same. Still, we can analyze the impact of the order on intermediate results, enabling us to objectively discuss questions such as which feature should be considered first. Here, we study data gathered in the US-Census. As we can see below, correcting for racial disparities is beneficial for women of a sensitive race but might harm women overall. Quantifying these biases allows policymakers to decide which sensitive variables should be prioritized.
Between the lines
Of course, the question of fairness goes beyond simple technical approaches to correct scores. There will always be a trade-off between predictive accuracy and fairness metrics, and it is up to society to decide which forms of discrimination are acceptable. For example, many differing regulations across US states already exist, reflecting societal preferences. Our approach does not solve the question of what should be considered but allows us to quantify the outcomes effectively. In that sense, it is a tool to encourage an objective discussion. In this spirit, we are currently working on a Python package that implements the algorithms used in our paper to facilitate the use and encourage an active discussion among practitioners and policymakers alike. We hope that this reduction in entry costs helps foster collaboration across the field of ethical AI, which also needs to involve experts from less technical fields.