

🔬 Research Summary by Leyang Cui, a senior researcher at Tencent AI lab.
[Original paper by Yue Zhang , Yafu Li , Leyang Cui, Deng Cai , Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao , Yu Zhang , Yulong Chen, Longyue Wang , Anh Tuan Luu, Wei Bi, Freda Shi, and Shuming Shi]
Overview: With their remarkable ability to understand and generate human language, Large language models (LLMs) like GPT-4 have significantly impacted our daily lives. However, a major concern regarding the reliability of LLM applications lies in hallucinations. This paper presents a comprehensive survey of hallucinations, including definitions, causes, evaluation, and mitigation methods.
Introduction
Large language models (LLMs) have become a promising cornerstone for developing natural language processing and artificial intelligence. LLMs have shown strong capability in understanding and generating human languages.
Despite their remarkable success, LLMs may sometimes produce content that deviates from user input, contradicts previously generated context, or is misaligned with well-established world knowledge. This phenomenon is commonly referred to as hallucination, which significantly undermines the reliability of LLMs in real-world scenarios.
Addressing hallucination in LLMs faces unique challenges due to massive training data, versatility, and imperceptible errors. LLM pre-training uses trillions of tokens from the web, making it hard to eliminate unreliable information. General-purpose LLMs must excel in various settings, complicating evaluation and mitigation efforts. Additionally, LLMs can generate seemingly plausible false information, making hallucination detection difficult for models and humans alike.
This paper introduces LLMs’ background, defines hallucination, presents relevant benchmarks and metrics, discusses LLM hallucination sources, reviews recent work addressing the issue, and offers forward-looking perspectives.
Key Insights
What is an LLM hallucination?
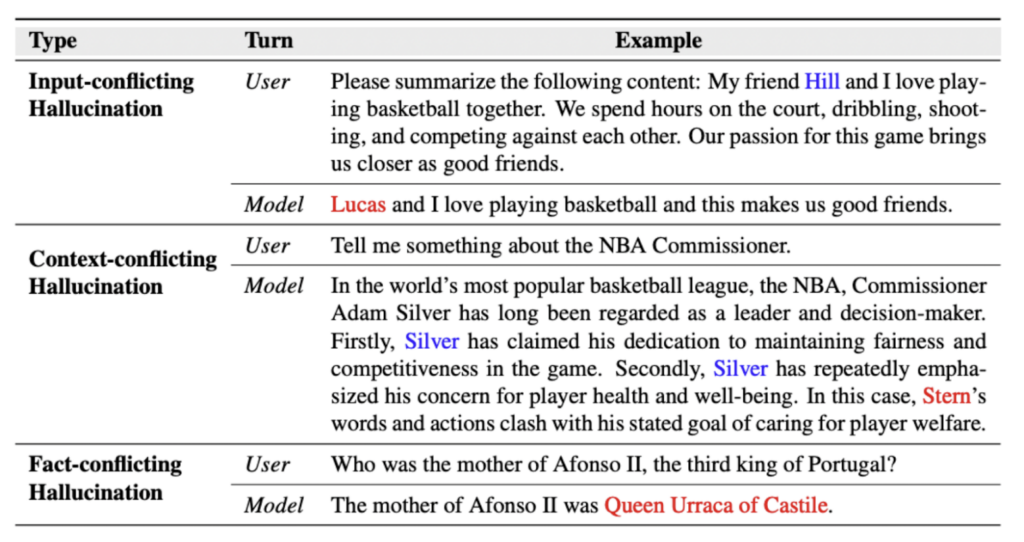
We categorize hallucination within the context of LLMs as follows:
Input-conflicting hallucination: LLMs generate content that deviates from the source input provided by users;
Context-conflicting hallucination: LLMs generate content that conflicts with previously generated information by itself; Fact-conflicting hallucination: LLMs generate content that is not faithful to established world knowledge.
Sources of LLM Hallucination
Various factors may induce hallucinations with LLMs.
- Lack of relevant knowledge or internalized false knowledge: the knowledge of LLMs is mostly acquired during the pretraining phase. When asked to answer questions or complete tasks, LLMs often exhibit hallucinations if they lack pertinent knowledge or have internalized false knowledge from the training corpora.
- LLMs sometimes overestimate their capacities: LLMs’ understanding of factual knowledge boundaries may be imprecise, and they frequently exhibit overconfidence. Such overconfidence misleads LLMs to fabricate answers with unwarranted certainty.
- Problematic alignment process could mislead LLMs into hallucination: During the supervised fine-tuning, LLMs do not acquire prerequisite knowledge from the pre-training phase. This is actually a misalignment process that encourages LLMs to hallucinate.
- Auto-regressive generation: LLMs sometimes over-commit to their early mistakes, even when they recognize they are incorrect.
Evaluation of LLM Hallucination
There are two benchmark categories for evaluating LLM hallucination: generation and discrimination. The former assesses the ability of LLMs to produce factual statements, while the latter concentrates on determining if LLMs can distinguish factual statements from a set of candidates.

Mitigation of LLM Hallucination
Pre-training: The mitigation of hallucinations during pre-training is primarily centered around the curation of pre-training corpora. Given the vast scale of existing pre-training corpora, current studies predominantly employ simple heuristic rules for data selection and filtering.
Supervised Fine-tuning (SFT): Thanks to the acceptable volume of SFT data, human experts can manually curate them. Recently, we have performed a preliminary human inspection and observed that some widely-used synthetic SFT data, such as Alpaca, contains a considerable amount of hallucinated answers due to the lack of human inspection.
Reinforcement Learning from Human Feedback (RLHF): RLHF guides LLMs in exploring their knowledge boundaries, enabling them to decline to answer questions beyond their capacity rather than fabricating untruthful responses. However, RL-tuned LLMs may exhibit over-conservatism (e.g., refrain from providing a clear answer) due to an imbalanced trade-off between helpfulness and honesty.
Inference: Designing decoding strategies to mitigate hallucinations in LLMs during inference is typically plug-and-play. Therefore, this method is easy to deploy, making it promising for practical applications.
Between the lines
Hallucination remains a critical challenge that impedes the practical application of LLMs. This survey offers a comprehensive review of the most recent advances that aim to evaluate, trace, and eliminate hallucinations within LLMs. We also delve into the existing challenges and discuss potential future directions. We aspire for this survey to serve as a valuable resource for researchers intrigued by the mystery of LLM hallucinations, thereby fostering the practical application of LLMs.