


🔬 Research Summary by Anthony Corso, Ph.D., Executive Director of the Stanford Center for AI Safety and studies the use of AI in high-stakes settings such as transportation and sustainability.
[Original paper by Anthony Corso, David Karamardian, Romeo Valentin, Mary Cooper, and Mykel J. Kochenderfer]
Overview: Machine learning has seen vast progress but still grapples with reliability issues, limiting its use in safety-critical applications. This paper introduces a holistic methodology that identifies five essential properties for evaluating the reliability of ML systems and applies it to over 500 models across three real-world datasets. Key insights reveal that the five reliability metrics are largely independent, but some techniques can simultaneously improve all of them.
Introduction
While recent progress in machine learning (ML) has been immense, enabling its application in safety-critical fields such as transportation and healthcare, many reliability issues still persist. For instance, an object detection system might misclassify a stop sign as a speed limit sign or a cancer detector may lose 20% accuracy due to slight variations in imaging procedures. Considering these challenges, how should we evaluate machine learning system reliability? This paper proposes a holistic assessment methodology, identifying five key properties vital for reliable ML systems: in-distribution performance, distribution-shift robustness, adversarial robustness, calibration, and out-of-distribution detection, and then combines them into a holistic reliability score. This approach evaluates over 500 models on three real-world datasets, identifying the most successful algorithmic techniques for improving reliability and analyzing how these metrics interrelate. A primary insight from the research is that improvements on these five reliability metrics are mostly independent of each other; improving one does not necessarily improve the others. However, some strategies, like fine-tuning pretrained models and ensembling, enhance all reliability metrics simultaneously, which may imply that they improve the model’s capability on a more fundamental level.
Key Insights
Which metrics should we care about?
It is common practice to measure the performance of an ML model on a held-out test set to determine how well it may generalize to the real world. However, this is just one element of deploying a safe and reliable system. The NIST AI risk management framework (RMF), for example, asserts that in addition to performing well in the expected environment, reliable systems should “withstand unexpected adverse events or unexpected changes in their environment […] and degrade safely and gracefully when this is necessary.” Which metrics can be used to quantify these properties of a machine learning model?
From the qualitative descriptions of reliability provided by documents such as the RMF, five key metrics emerged:
- In-distribution performance: Effectiveness on data similar to the training data
- Distribution-shift robustness: Effectiveness on data resembling the training data but with slight changes or corruptions
- Adversarial robustness: Resilience to intentionally manipulated inputs
- Calibration: Precision in assessing prediction confidence
- Out-of-distribution detection: Capability to recognize data that diverges considerably from training data
To illustrate these metrics, consider an autonomous driving model trained for urban environments. In-distribution performance might refer to its accuracy in familiar city landscapes while driving in suburban areas or foreign cities might be considered distribution-shifted data. Out-of-distribution examples might occur during extreme weather conditions or sensor faults that were not part of the training data, where the model should ideally identify its limitations and handle the situation appropriately. Calibration pertains to how closely the model’s prediction confidence aligns with actual outcomes. For instance, if the model is 99% confident that it can safely change lanes, we would expect a 99% success rate in real-world tests. Finally, adversarial robustness refers to the model’s ability to withstand deliberate interference, like manipulated traffic signs designed to mislead the system.
These five metrics give a more holistic picture of the reliability of a machine learning system. In the paper, a new metric called the holistic reliability (HR) score is introduced, which combines these metrics in a weighted average to produce a single score. This score isn’t meant to be comprehensive but measures how well a model performs across all metrics simultaneously.
How can we build more reliable systems?
An enormous amount of research has been conducted into improving each of the proposed reliability metrics, but rarely are models evaluated across multiple metrics. Can models achieve high performance across all of these metrics simultaneously? And if you improve one metric, do the others also tend to improve? These questions are explored by evaluating over 500 models across three real-world datasets, including species classification (iWildCam), land-use classification (FMoW), and cancer detection (Camelyon17). The models were trained using various techniques that are known to improve at least one of the five metrics, such as data augmentation, adversarial training, ensembling, fine-tuning from large pre-trained models, temperature scaling, and more.
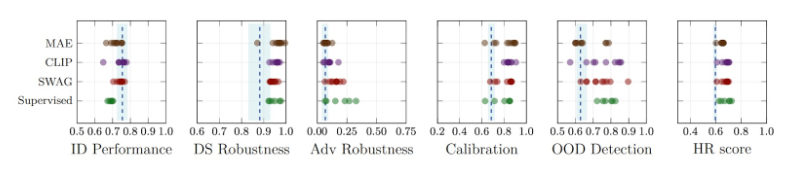
One of the most effective approaches for improving all reliability metrics was fine-tuning large pre-trained models. Below are the results for the iWildCam dataset. The blue band shows the range of the baseline models, with the dashed line giving the average. Each dot represents one model and compares four different types of pre-training approaches (see paper for additional details). The main takeaway is that the best-performing fine-tuned models have improvements across all five reliability metrics leading to a significantly higher holistic reliability score. Ensembling a diverse set of models was also shown to consistently improve overall reliability.
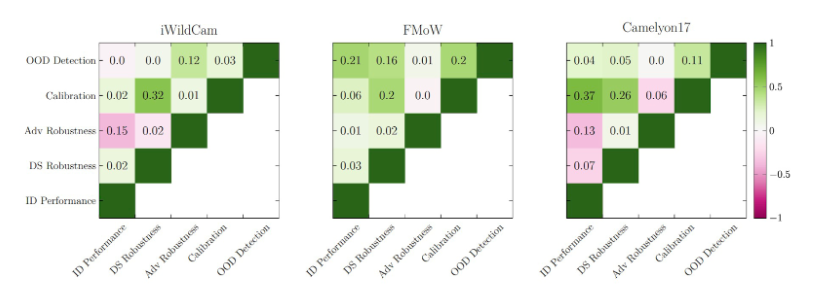
Another question addressed by this work is whether these reliability metrics are intrinsically related to each other or if they vary independently. To study this, the correlation coefficient between each pair of metrics was computed (adjusting for the effect of the aforementioned algorithmic interventions). The results are shown below: the color gives the Pearson correlation (which includes a direction), and the R2 value is displayed in each cell. The main takeaway is that there is very little correlation between metrics. Therefore, if a practitioner optimizes a model for accuracy and calibration alone, it will generally not perform well in other metrics like high calibration, adversarial robustness, etc. This conclusion emphasizes the need for comprehensive evaluation methodologies in machine learning development, understanding metric interdependencies, and the significance of model selection before deployment. It also suggests that techniques improving specific reliability metrics can be valuable and combined for high-reliability models.
Between the lines
The reliability of a machine learning system is not a single, easy-to-define attribute but rather a complex set of properties and context. This work moves towards a more holistic assessment of ML systems but leaves many questions unanswered. The first questions are technical: Why do some approaches lead to overall reliability improvements while others just improve individual metrics? Insight into this question may lead to further advances in building highly reliable systems. Additionally, suppose pre-trained models are to be the basis of highly reliable machine learning systems. In that case, ensuring their widespread availability and protecting them against harmful biases and security risks such as backdoor trojan attacks is vital.
From a policy and regulatory perspective, the complex nature of ML reliability necessitates a more nuanced understanding by policymakers. Comprehensive evaluations, reflecting the operational context, are crucial and should also encompass aspects like fairness, interpretability, and privacy. Recognizing that a system’s safety must be evaluated within its socio-technical context is important. Without this holistic perspective, generalizing the safety of ML systems is challenging. Yet, with conscientious assessment and regulation, we can foster a promising future for using ML systems.