


🔬 Research Summary by Aida Rahmattalabi, a PhD in computer science at the University of Southern California where she focused on developing data-driven and trustworthy algorithms to guide public health interventions.
[Original paper by Aida Rahmattalabi, Alice Xiang]
Overview: This paper investigates the practical and epistemological challenges of applying causality for fairness evaluation. It focuses on two key aspects: nature and timing of the interventions on sensitive attributes such as race, gender, etc. and discusses the impact of this specification on the soundness of the causal analyses. Further, it illustrates how proper application of causality can address the limitations of existing fairness metrics, including those that depend upon statistical correlations.
Introduction
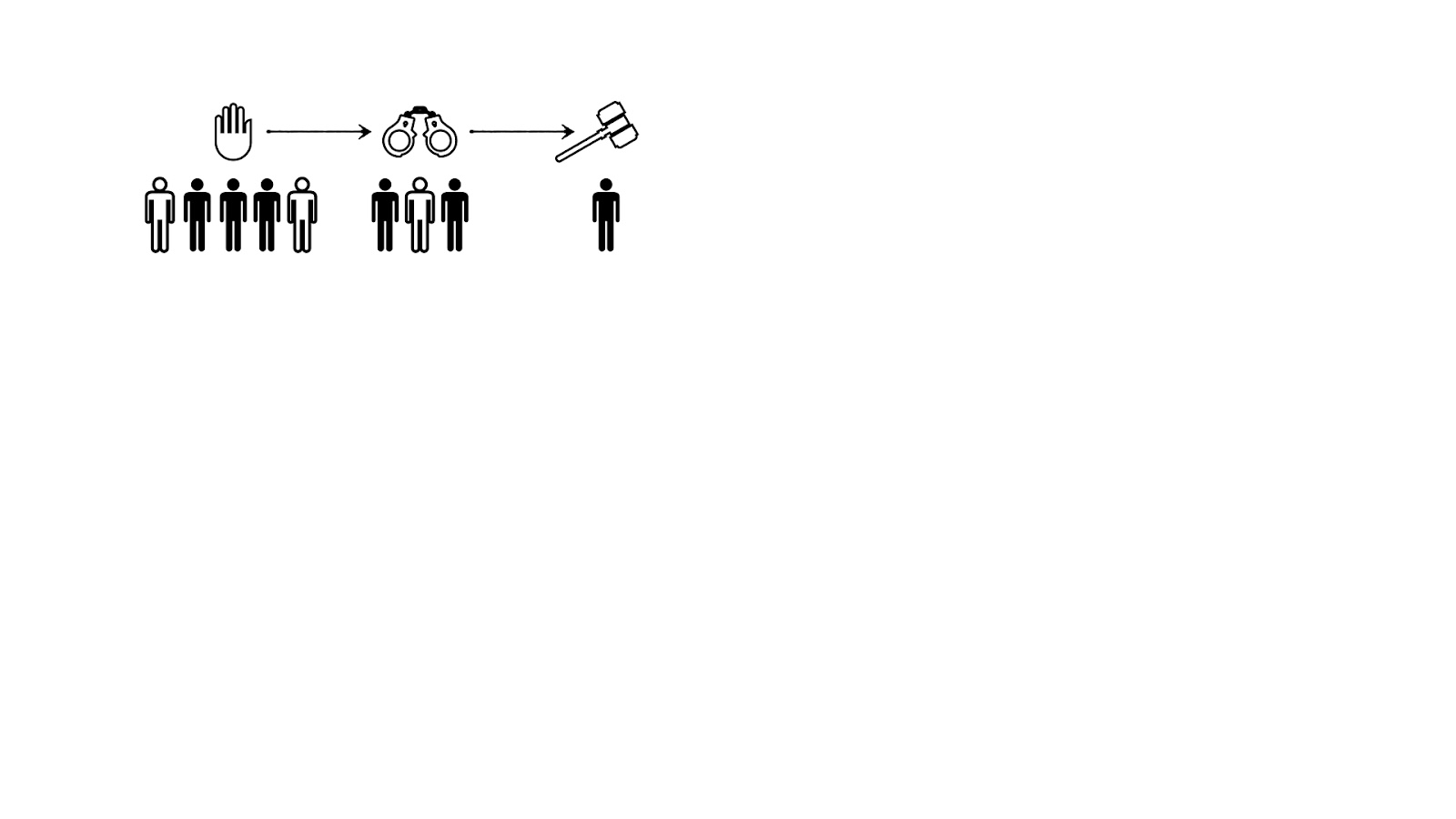
In recent years, there has been a growing interest in applying causality for evaluating the fairness of ML systems that operate in socially-sensitive settings such as policing, healthcare or hiring. These real-world systems often involve complex and multi-stage decisions, where the outcomes of each stage influences the future decisions, making it difficult to identify sources of unfairness and assign appropriate responsibilities. For example, consider the criminal justice system, where discriminations in being stopped, arrested or charged will affect one’s criminal history which subsequently increases one’s chances of future charges (Figure 1).
Causality seeks to find the sources of unfairness through estimating the effect of a hypothetical intervention on one’s sensitive attributes (e.g., race) on a specific outcome (e.g., being charged). Answering such counterfactual questions faces unique challenges due to the largely immutable nature of the sensitive attributes. We address the above conceptual challenge by centering the discussion around a precise speciation of interventions. Specifically, we emphasize the importance of defining the timing and nature of the intervention on one’s sensitive attribute for a sound causal analysis. We further argue how such conceptualization allows us to disentangle unfairness along a causal pathway and attribute it to the respective actors.
Figure 1. An example decision-making pipeline. Early discrimination may be perpetuated or amplified in later stages even if later stages treat individuals fairly.
Key Insights
Causal Fairness Framework
We consider a decision-making scenario where each individual is characterized by a set of features, including a sensitive attribute, that we use to guide the decision. Causal fairness views the unfairness evaluation problem as a counterfactual inference problem. Precisely, it aims to answer questions of type: What would have been the hiring decision, if the person had been perceived to be of a different gender? Such causal criteria are centered around the notion of an intervention on social groups defined by gender and race.
We take a decision-maker’s position considering how their perception of one’s sensitive attributes may lead to different decisions. Through this conceptualization, it is possible for discrimination to operate not just at one point in time and within one particular domain but at various points within and across multiple domains throughout the course of one’s life. For example, earlier work has recognized potential points of racial discrimination across different domains including labor market, education, etc. [1]. Consequently, we need to specify the point in time at which we wish to measure unfairness.
In causal terms, this is closely related to the notion of timing of the intervention, i.e., the time at which one’s sensitive attribute is perceived by an actor or decision-maker. To illustrate, consider a hiring scenario and suppose we are interested in evaluating whether the hiring decision is fair with respect to gender. We can investigate unfairness at different stages, e.g., from the first time an individual comes into contact with the company (e.g., resume review), progresses in the system (during interviews), or when the final decision is being made. We may even take a broader perspective and investigate the effect of gender on college education and subsequently the opportunities in the job market. Indeed, as we expand our view the causal inference problem we are faced with becomes increasingly more challenging but the conceptual framework remains valid.
Additionally, it is crucial to understand the mechanisms through which one’s sensitive attribute is perceived (e.g., skin color, zip code, name or language) as it determines the true effect that the causal analysis uncovers. For instance, in the study conducted in [2], the authors manipulated the names on the resumes to measure racial discrimination which only allowed them to capture the level of discrimination exhibited through the relationship between one’s name and perception of race. Under a different manipulation, e.g., zip code of the applicant, the outcome of the study would have been different. In observational studies, where the analyst has no control over how an individual’s sensitive attribute is perceived, a careful examination of these mechanisms is still necessary both to identify sources of estimation errors (e.g., different decision-makers may have different perceptions about one’s sensitive attributes that may not be necessarily recorded in the data) and come up with the right remedial actions (e.g., not showing applicants profile picture to online recruiters).
Trade-offs under the Lens of Causality
We now revisit the impossibility results under the causal framework. To do so, we introduce causal variants of popular fairness criteria. For example, consider statistical parity which captures the average difference in the outcome of different social groups. Alternatively, we can define causal parity as the average difference in the outcome of individuals if they belonged to a different social group. Here, we actively intervene on one’s sensitive attribute, rather than relying on passive observations. As a result, we are immune against the spurious correlations between the sensitive attribute and other features and capture the true effect of a sensitive attribute on the decision.
Similar to statistical parity, we propose causal variants of other popular statistical criteria of fairness, namely, conditional statistical parity [3], equalized odd [4], calibration [5] and positive predictive parity [6]. We show two key results:
- Conditional causal parity guarantees causal parity.
This observation does not hold for statistical counterparts of these criteria. A notable counterexample is the Berkeley college admission where despite observing no significant difference in the admission rate of female and male students after conditioning on department choice, there was a considerable disparity in the overall rate of admission between genders.
- Conditional causal parity implies causal calibration, causal equalized odds and causal positive predictive parity.
The above result is in sharp contrast with the well-known impossibility results in the statistical fairness literature. In fact, it shows that some notions simply impose more stringent fairness requirements (e.g., conditional causal parity). Hence, satisfying one criterion automatically guarantees fairness according to other criteria.
Between the lines
As empirical evidence on ethical implications of algorithmic decision-making is growing [7, 8, 9], a variety of approaches have been proposed to evaluate and minimize the harms of these algorithms. In the statistical fairness literature, it is well-established that it is not possible to satisfy every fairness criterion simultaneously, which results in significant trade-offs in selecting a metric. On the other hand, in the causal fairness literature, there is substantial ambiguity around how the proposed methods should be applied in practice. This work aims to address some of these limitations. We build on causality as the main framework but instead of postulating interventions on immutable attributes, such as race, we focus on manipulating their perception. In doing so, we discuss how a precise specification of the timing and the nature of the intervention will help remove the ambiguities from existing causal methods. Additionally, this conceptualization facilitates discussions around different actor’s responsibility in an entire decision-making process. Such temporal analysis of fairness in machine learning has received little attention in the fairness literature, both from benchmark datasets and algorithmic development perspectives. We hope that our empirical observations spark additional work on collecting new datasets that lend themselves to temporal fairness evaluation.
Bibilography
[1] Susan Athey, Raj Chetty, Guido W. Imbens, and Hyunseung Kang. 2019. The Surrogate Index: Combining Short-Term Proxies to Estimate Long-Term Treatment Effects More Rapidly and Precisely. SSRN (2019)
[2] Marianne Bertrand and Sendhil Mullainathan. 2004. Are Emily and Greg More Employable Than Lakisha and Jamal? A Field Experiment on Labor Market Discrimination. American Economic Review 94, 4 (2004)
[3] Faisal Kamiran, Indre Žliobaite, and Toon Calders. 2013. Quantifying explainable discrimination and removing illegal discrimination in automated decision making. Knowledge and Information Systems 35, 3 (2013)
[4] Moritz Hardt, Eric Price, and Nathan Srebro. Equality of opportunity in supervised learning. Advances in Neural Information Processing Systems (2016)
[5] Jon Kleinberg, Sendhil Mullainathan, and Manish Raghavan. 2017. Inherent trade-offs in the fair determination of risk scores (2017)
[6] Alexandra Chouldechova. 2017. Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments. Big Data 5, 2 (2017)
[7] John Monahan and Jennifer L. Skeem. 2016. Risk Assessment in Criminal Sentencing. Annual Review of Clinical Psychology 12 (2016)
[8] Ziad Obermeyer and Sendhil Mullainathan. 2019. Dissecting Racial Bias in an Algorithm that Guides Health Decisions for 70 Million People
[9] Lisa Rice and Deidre Swesnik. Discriminatory effects of credit scoring on communities of color (2012)