


🔬 Research Summary by Christopher Teo, PhD, Singapore University of Technology and Design (SUTD).
[Original paper by Christopher T.H.Teo, Milad Abdollahzadeh, and Ngai-Man Cheung]
Note: This paper, On Measuring Fairness in Generative Models, was presented at NeurIPS 2023.
Read: FairQueue: Rethinking Prompt Learning for Fair Text-to-Image Generation (NeurIPS 2024)
Overview: This work addresses a significant gap in the field of generative modeling by exploring how fairness in these models is measured. It identifies inaccuracies in existing fairness measurement frameworks and proposes a new fairness measurement framework called CLassifier Error-Aware Measurement (CLEAM), which reveals substantial biases in state-of-the-art generative models e.g., different biases in synonymous text prompts for Text-to-Image generation (Stable Diffusion), StlyeGAN (Convolution based GAN) and StyleSwin (Transformer based GAN).

Introduction

Generative models like GANs and diffusion-based frameworks have revolutionized applications in art, entertainment, and beyond. However, the risks of bias in these models—mirroring societal stereotypes or excluding specific subgroups—pose serious challenges. Imagine a scenario where a text-to-image generator consistently produces images of men when prompted with “engineer.” Such biases aren’t just technical shortcomings—they reflect deeper societal issues with profound real-world implications.
While recent strides have been made to debias generative models, an overlooked aspect is the accuracy of fairness measurement itself. Most current methods rely on sensitive attribute (SA) classifiers, assuming their high accuracy guarantees reliable fairness assessments. However, our research reveals that even highly accurate classifiers can introduce significant errors, casting doubt on prior fairness improvements in generative modeling.
To address this, we propose CLEAM, a statistical framework designed to mitigate measurement errors by explicitly modeling and accounting for classifier inaccuracies. CLEAM is rigorously evaluated on newly introduced datasets (GenData) which consist of samples generated by state-of-the-art models, revealing substantial biases and inconsistencies.
Understanding Fairness in Generative Models
Fairness in generative modeling typically revolves around equal representation across sensitive attributes (SAs), such as gender, race, or age. A generative model is deemed fair if its outputs reflect a balanced distribution of these attributes. For example, for a text prompt to a Text-to-Image Generator like “a scientist,” a fair model would generate images equally representing diverse genders, ethnicities, and other demographic groups.
However, achieving fairness in generative models is challenging, e.g., due to biases in the training data, potentially resulting in these models inheriting and perpetuating societal biases. For instance, a dataset skewed toward male representations of professions like engineering could lead to the model predominantly associating engineering with men.
Shortcomings of Current Fairness Measurement Frameworks
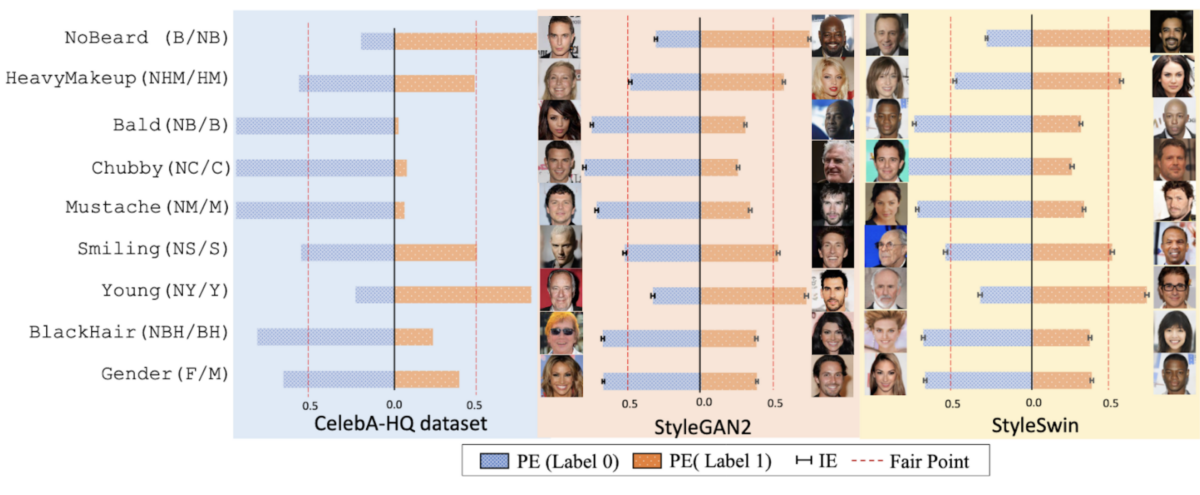
Existing fairness measurement frameworks rely heavily on SA classifiers to analyze generated outputs. These classifiers label samples (e.g., identifying gender in generated faces) and compute fairness metrics based on their distributions. However, this approach assumes that accurate classifiers automatically translate into reliable fairness measurements, which is not always true.
Our research demonstrates that even highly accurate classifiers (e.g., with 97% accuracy) can produce significant fairness measurement errors. These inaccuracies arise because classifiers may disproportionately mislabel certain subgroups or fail to capture nuanced biases in the data. This leads to misleading conclusions about a model’s fairness, undermining efforts to improve generative AI systems.
For example, prior studies have reported fairness improvements that fall within the margin of error introduced by classifier inaccuracies. Such findings cast doubt on the validity of these improvements and highlight the need for a more robust measurement framework.
The CLEAM Framework: A Statistical Approach to Measurement
CLEAM (CLassifier Error-Aware Measurement) addresses these limitations by incorporating a statistical model that explicitly accounts for classifier inaccuracies. Unlike traditional frameworks, CLEAM accounts for these classifiers’ inaccuracies to adjust the fairness metrics and reflect a more accurate measurement of generated outputs.
The framework computes two key metrics:
- Point Estimates: These provide a corrected mean measure of fairness, significantly reducing error margins.
- Interval Estimates: These establish confidence intervals, allowing for more robust and transparent fairness assessments.
For instance, in experiments with StyleGAN2, CLEAM reduced measurement errors from 4.98% to 0.62% for gender fairness—a nearly eightfold improvement over baseline methods.
Utilizing CLEAM to Further Evaluate State-of-the-Art Generative Models
CLEAM was further used to better understand how the leading generative models, like StyleGAN2, StyleSwin, and Stable Diffusion, handle biases. The findings revealed:
- GANs: Both convolutional (StyleGAN2) and transformer-based (StyleSwin) architectures exhibited significant biases across multiple SAs, including gender and hair color. Additionally, it was interesting that while StyleSwin produced higher-quality images, its fairness remains consistent with StyleGAN2.
- Stable Diffusion: Text-to-image models showed instability in fairness metrics. Subtle prompt variations (e.g., “a person” vs. “one person”) resulted in drastically different biases, underscoring the model’s sensitivity to input phrasing.
These results highlighted pervasive biases in popular generative models, emphasizing the need for better fairness interventions.
Between the lines
The implications of CLEAM extend beyond measurement accuracy, as it challenges existing fairness assumptions in generative AI by exposing hidden biases and significant inaccuracies in widely-used frameworks. CLEAM’s ability to drastically reduce measurement errors underscores its importance in ensuring generative models are evaluated reliably. This is critical as biased generative outputs can perpetuate stereotypes and inequalities, particularly in sensitive applications like healthcare or recruitment.
However, gaps remain. The focus on binary-sensitive attributes overlooks the complexity of real-world identities, including non-binary and intersectional characteristics. Additionally, while CLEAM addresses classifier inaccuracies, it still relies on SA classifiers, pointing to a need for alternative, classifier-independent methods. Finally, fairness measurement frameworks should account for dynamic shifts in fairness over time or across diverse contexts.
Future research should expand fairness definitions, explore unsupervised methods, and assess fairness in evolving real-world applications. By addressing these gaps, we can advance toward more inclusive and equitable generative AI systems. CLEAM lays a robust foundation but highlights the ongoing journey toward fairness in AI.
Read: FairQueue: Rethinking Prompt Learning for Fair Text-to-Image Generation (NeurIPS 2024)