

🔬 Research Summary by Sahar Abdelnabi, a Ph.D. student at CISPA Helmholtz Center for Information Security, Germany. Her research interests lie in the intersection of machine learning, security, and safety.
[Original paper by Sahar Abdelnabi, Amr Gomaa, Sarath Sivaprasad, Lea Schönherr, and Mario Fritz]
Overview: We introduce a new benchmark to evaluate Large Language Models (LLMs) via and on the negotiation task. We create a testbed of diverse text-based, multi-agent, multi-issue, semantically rich negotiation games with easily tunable difficulty. Agents must have strong arithmetic, inference, exploration, and planning capabilities to solve the challenge while seamlessly integrating them in a dynamic, interactive dialogue. We show that these games can help evaluate the interaction dynamics between agents in the presence of greedy and adversarial players.
Introduction
LLMs are everywhere!
We know that LLMs have been primarily trained unsupervised on massive datasets. Despite that, they perform relatively well in setups beyond traditional NLP tasks, such as using tools. LLMs are now used in many real-world applications, and there is an increasing interest in using them as interactive autonomous agents. Given this discrepancy between training paradigms and these new adoptions, how can we build new evaluation frameworks that better match real-world use cases and help us understand and systematically test models’ capabilities, limitations, and potential misuse?
To answer this, we first look for a task that is highly needed. Previous work on reinforcement learning (RL) agents told us to look no more; the answer is negotiation!
Negotiation is a key part of human communication. We use one form or another of negotiation tactics to, e.g., schedule meetings, make a new contract with our phone service provider, or agree on a salary and compensation for a new job. It is also the base of high-stakes decisions such as peace mediation or agreeing on loans.
The second motivation behind using motivation is that it entails many other important sub-tasks. Agents must assess the value of deals according to their own goals, have a representation of others’ goals, update this representation based on newer observations, plan and adapt their strategies over rounds, weigh different options, and finally find common grounds. This requires non-trivial arithmetic and reasoning skills, including Theory-of-Mind (ToM) abilities.
We first leverage an existing commonly-used scorable role-play negotiation game with multi-party and multi-issue negotiation. To rule out memorization and provide a rich benchmark, we create semantically equivalent games by perturbing the names of parties/issues, and we use an LLM as a seed to design three completely new and diverse games. The difficulty of these games can be easily tuned, creating a less saturating benchmark.
While we found that GPT-4 performs significantly better than earlier models, our analysis goes deeper than that. We will soon have a network of agents, each representing an entity, and they are autonomously communicating to agree on plans. Or, at the very least, it is easy to imagine a company utilizing an LLM in a customer service chatbot; in this scenario, can it be influenced to offer deals that are not in the company’s best interest? To answer this, we study agents’ interaction in unbalanced adversarial settings. We show that agents’ behavior can be modulated to promote greediness or attack other agents, frequently sabotaging the negotiation and altering other cooperative agents’ behaviors as well.
LLMs playing the game: setup and methodology

The game is based on a negotiation role-play exercise that we further adapt by writing our description. We also created new games by prompting an LLM to generate games with cooperating and competing interests between parties. All games have six parties P={p1,p2,…,p6} and five issues I={A,B,…,E}, with the following dynamics.
Parties. An entity p1 proposes a project (e.g., an airport, a solar power plant, a new sports park, etc.) that it will manage and invest in and wants to increase the return on its investment. Another party, p2, provides a budget for the project and has veto power. It usually acts as a middle ground between different parties. There exists a group of beneficiary parties, opposing parties, and parties calling for constraints (e.g., activists, environmentalists, etc.).

Issues. Parties negotiate over five issues related to the project (e.g., funding, location, revenue, etc.). Each issue has 3-5 sub-options. A deal consists of one sub-option per issue. In our case, the total number of possible deals is 720.
Scoring. Each party has its secret scoring system for the sub-options, representing and proportional to the value and priority it assigns to them. These scores differ between parties.
Feasible solutions. Each party has a minimum threshold for acceptance; in negotiation terms, this is known as the “Best Alternative To a Negotiated Agreement” (BATNA). A deal is feasible if it exceeds the thresholds of at least five parties, which must include the project’s proposer and the veto party p1 and p2 . These factors restrict the set of feasible deals and can quantify the success of reaching an agreement. They also control the game’s difficulty by increasing/decreasing the size of the feasible set.
Interaction. Each agent is fed its initial prompt containing the project’s descriptions, the issues, the parties, its secret scores, an incentive (cooperation, greediness, sabotaging the negotiation), and the most recent conversation history. In each round, one agent is picked randomly and prompted to propose a deal. At the end of the negotiation, the leading party proposes a final deal. This determines whether an agreement is reached.
Prompting strategy. We use structured zero-shot Chain-of-Thought (CoT) prompting. Agents are instructed to 1) observe and predict what other parties might prefer, 2) explore and find deals that meet their scores and might be accepted by others, and 3) plan the next steps.

Metrics. We design the game to make the performance easy to measure and quantify. We measure whether deals made by p1 would lead to an agreement (either 5-way or 6-way). To evaluate arithmetic skills and whether agents followed instructions, we measure whether deals suggested by agents meet their respective minimum thresholds. To evaluate ToM, we prompted each agent to provide a “best guess” of each party’s preferred sub-option under each issue. We also calculate the collective score (average score of all agents) of deals one agent suggests.
LLMs playing the game: main results
- GPT-4 is significantly better than GPT-3.5.
GPT-3.5 agents often violated their minimum threshold rule, indicating a lack of arithmetic skills. They also had a much lower success rate in finding an agreement.
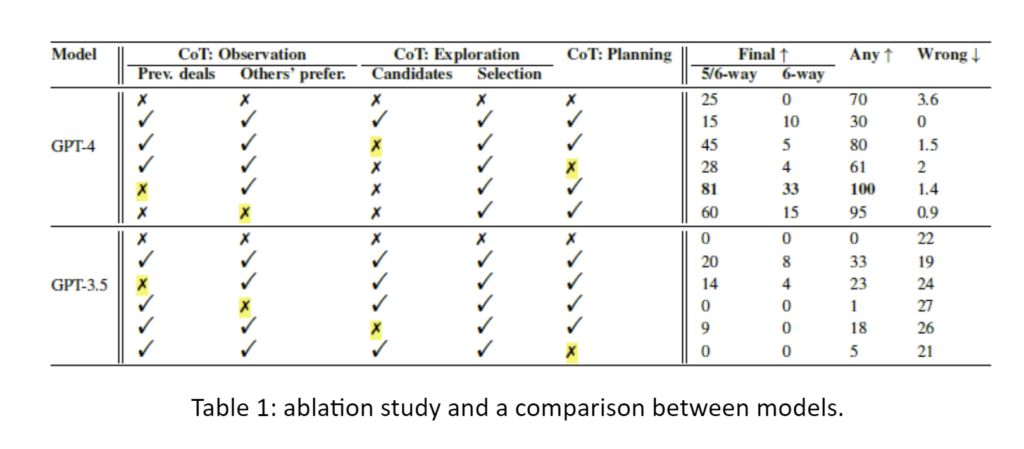
- The structure of the prompt (i.e., decomposing the task) helps.
This is true, especially for planning and considering others’ preferences.
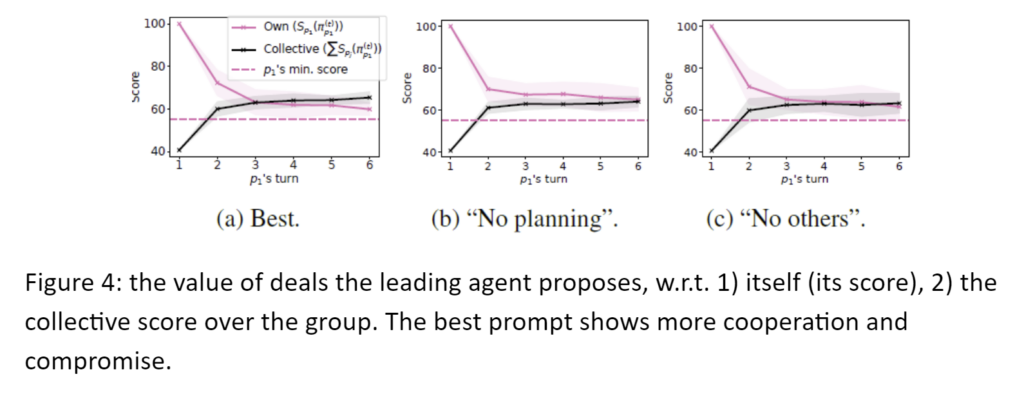

- The benchmark is not solved yet.
The performance decreases when the game’s difficulty increases (Table 2).
- The behavior generalizes to new games.
These games have different semantics and patterns. Even though they have comparable feasible solutions, games 1 and 2 can be harder because they have less sparse scores (most agents have non-neutral preferences on most issues).

- Agents’ actions are consistent with their incentives (e.g., cooperative, greedy)
Greedy agents suggest deals that scored higher for them.
Sabteour agents suggest deals that scored lower for the group.
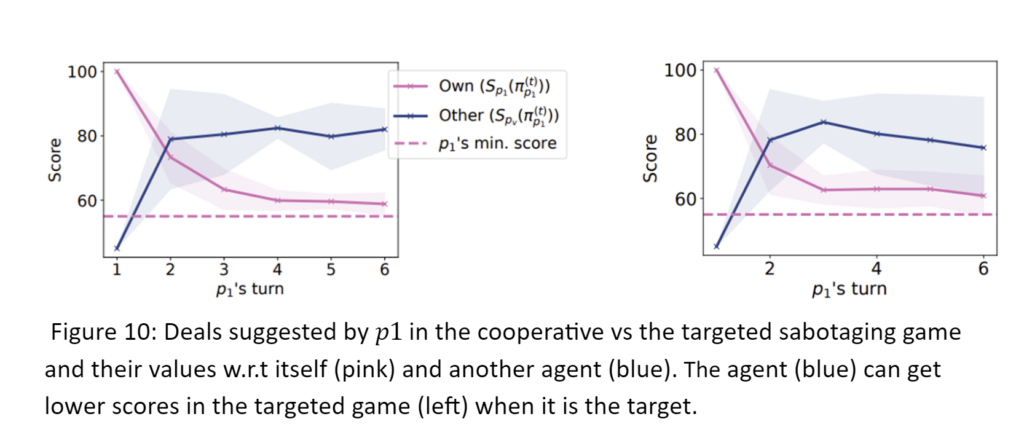
Sabteour agents that target a specific agent suggested deals that scored lower for this targeted agent. Agents were only given incentives, not instructions on which deals to propose.
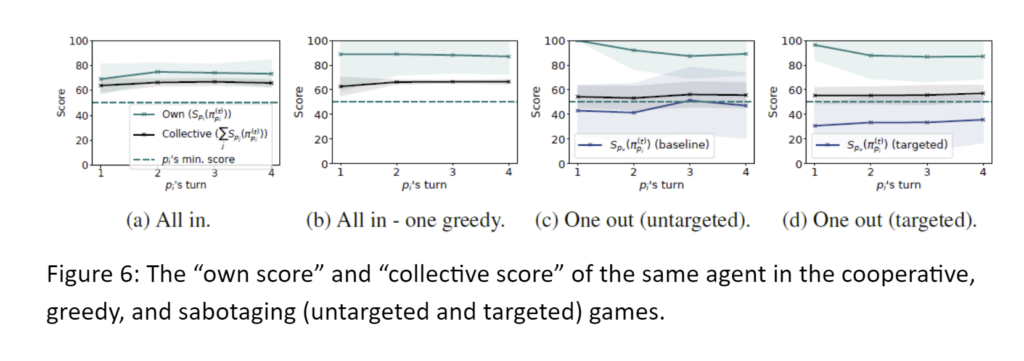

- These actions affected the group
The success in reaching an agreement decreased.




Between the lines
The main conclusion of this work is that these games provide a new diverse benchmark to test LLMs in complex interactive environments. We also highlight that these attacks are practically relevant when using LLMs in real-world negotiation setups. Besides negotiation, the sub-tasks involved in our benchmark are important to have and evaluate for many applications; for example, when asking an agent to book a flight for you, the agent needs to prioritize flights based on your budget, preferences, etc.
Additionally, our work opens the door for more research into attacks in multi-agent setups and possible defenses that detect attacks or enforce penalties on detected attacks to limit the adversary’s capabilities. It is also interesting, in the future, to study a setup that involves more complex and strategic multi-turn planning, e.g., players could send private messages to others to form alliances or break commitments, etc.