


🔬 Research Summary by Matthew Barker, a recent graduate from the University of Cambridge, whose research focuses on explainable AI and human-machine teams.
[Original paper by Matthew Barker, Emma Kallina, Dhananjay Ashok, Katherine M. Collins, Ashley Casovan, Adrian Weller, Ameet Talwalkar, Valerie Chen, and Umang Bhatt]
Overview: Even though machine learning (ML) pipelines affect an increasing array of stakeholders, there is a growing need for documenting how input from stakeholders is recorded and incorporated. We propose FeedbackLogs, an addendum to existing documentation of ML pipelines, to track the feedback collection process from multiple stakeholders. Our online tool for creating FeedbackLogs and examples can be found here.
Introduction
Who decides how a model is designed? Prior work has emphasized that stakeholders, individuals who interact with or are affected by machine learning (ML) models, should be involved in the model development process. However, their unique perspectives may not be adequately accounted for by practitioners responsible for developing and deploying models (e.g., ML engineers, data scientists, UX researchers). We identify a gap in the existing literature around documenting how stakeholder input was collected and incorporated in the ML pipeline, which we define as a model’s end-to-end lifecycle, from data collection to model development to system deployment and ongoing usage.
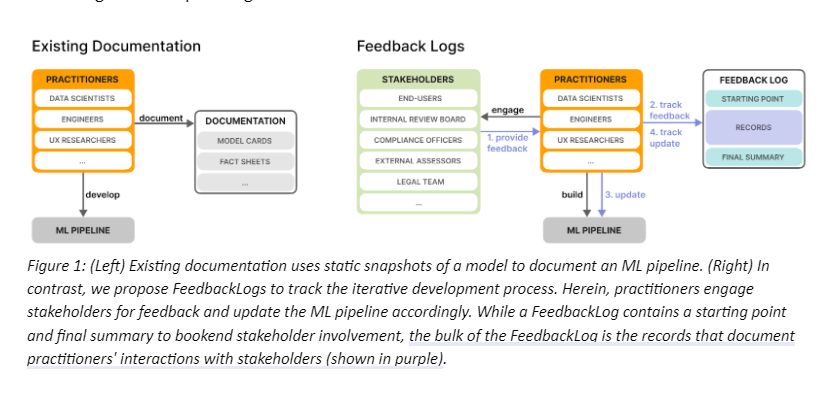
A lack of documentation can create difficulties when practitioners attempt to justify why certain design decisions were made through the pipeline: this may be important for compiling defensible evidence of compliance to governance practices, anticipating stakeholder needs, or participating in the model auditing process. While existing documentation literature (e.g., Model Cards and FactSheets) focuses on providing static snapshots of an ML model, as shown in Figure 1 (Left), we propose FeedbackLogs, a systematic way of recording the iterative process of collecting and incorporating stakeholder feedback.
Key Insights
Design of a FeedbackLog
The FeedbackLog is constructed during the development and deployment of the ML pipeline and updated as necessary throughout the model lifecycle. While the FeedbackLog contains a starting point and final summary to document the start and end of stakeholder involvement, the core of a FeedbackLog is the records documenting practitioners’ interactions with stakeholders. Each record contains the content of the feedback provided by a particular stakeholder and how it was incorporated into the ML pipeline. The process for adding records to a FeedbackLog is shown in purple in Figure 1 (Right). Over time, a FeedbackLog reflects how the ML pipeline has evolved due to these interactions between practitioners and stakeholders.
We propose a template-like design for FeedbackLogs with three distinct components (shown in Figure 1): a starting point, one or more records, and a final summary.
Starting Point
The starting point describes the state of the ML pipeline before the practitioner reaches out to any relevant stakeholders. It might contain information on the practitioner’s objectives, assumptions, and current plans. A starting point may consist of descriptions of the data, such as Data Sheets, metrics used to evaluate the models, or policies regarding system deployment. A proper starting point allows auditors and practitioners to understand when, in the development process, the gathered feedback was incorporated and defensibly demonstrates how specific feedback led to changes in the metrics.
Records
The feedback from stakeholders is contained in the records section, which can house multiple records. Each record in a FeedbackLog is a self-contained interaction between the practitioner and a relevant stakeholder. It consists of how the stakeholder was requested for feedback (elicitation), the stakeholder’s response (feedback), and how the practitioner used the stakeholder input to update the ML pipeline (incorporation). To make these four sections more concrete, we provide questions which should be answered when writing a record:
- Elicitation – Who is providing feedback and why?
- Feedback – What feedback is provided?
- Incorporation – Which, where, when, and why are updates considered?
- Summary – What is the overall effect(s) of the updates(s) applied?
Final Summary
The final summary consists of the same questions as the starting points, i.e., which dataset(s) and models are used after the updates and the metrics used to track model performance. Proper documentation of the finishing point of the FeedbackLog allows reviewers to clearly establish how the feedback documented leads to concrete and quantifiable changes within the ML pipeline.
FeedbackLogs in Practice
We engaged directly with ML practitioners to explore how FeedbackLogs would be used in practice. Through interviews, we surveyed the perceived practicality of FeedbackLogs. Furthermore, we collected three real-world examples of FeedbackLogs from practitioners across different industries. Each example FeedbackLog was recorded at a different stage in the ML model development process, demonstrating the flexibility of FeedbackLogs to account for feedback from various stakeholders. The examples show how FeedbackLogs serve as a defensibility mechanism in algorithmic auditing and a tool for recording updates based on stakeholder feedback.
Expected Benefits of Implementing FeedbackLogs
The practitioners we interviewed confirmed many of the benefits of FeedbackLogs we had anticipated, e.g., the predefined structure that allows for fast information gathering and the benefits regarding audits, accountability, and transparency. The practitioners also suggested that FeedbackLogs improve communication and knowledge-sharing within organizations. Additionally, an interviewee noted how FeedbackLogs can be a repository of past mistakes, solutions, and best practices. If an issue emerged, it could be used to trace the source of the issue and identify past reactions to similar issues and the (long-term) effect of these reactions.
Between the lines
The need for FeedbackLogs arises from increasingly complex ML development processes, which typically collect and incorporate stakeholder feedback from various stakeholders. FeedbackLogs provide a way to systematically record this feedback from developers, UX designers, end-users, testers, and regulators. The emerging popularity of large language models that collect feedback from many end-users highlights the need for FeedbackLogs, amongst other forms of documentation in the industry.
However, practitioners anticipated several challenges during the practical implementation of FeedbackLogs, such as the potential privacy issues if sensitive feedback is recorded. In addition, logistical challenges are involved with implementing FeedbackLogs at scale without significantly burdening practitioners. We hope future versions of FeedbackLogs address these concerns and usher in developing extensible tools for practitioners to empower the voices of diverse stakeholders.