


🔬 Research Summary by Wenbin Zhang, a Postdoctoral Researcher at Carnegie Mellon University tackling important social, environmental, and public health challenges that exist today using AI, a.k.a. AI for Social Good.
[Original paper by Wenbin Zhang, Toby Walsh, Shuigeng Zhou and Jeremy C Weiss]
Overview: Fairness in machine learning (ML) commonly assumes the underlying data is independent and identically distributed (IID). On the other hand, graphs are a ubiquitous data structure to capture connections among individual units and are non-IID by nature. This survey reviews recent advances on ubiquitous non-IID graph representations and points out promising future directions.
Introduction
Graph learning is behind many recent success stories in machine learning due to the ubiquity of graph structure in today’s increasingly connected world such as social networks, power grid, traffic networks and proteins. Since graph data is commonly modeled to reflect its structural and neighborhood information, societal bias can be naturally inherited and even exacerbated. For example, the use of social network information in the growing practice of credit scoring has shown to yield discriminatory decisions towards specific groups or populations.
On the other hand, much progress has been made to understand and correct algorithmic bias focusing on IID data representation. Since individuals are interconnected in graph data, such fundamental IID assumption behind the traditional ML fairness does not hold. To address this issue, a number of approaches have been proposed to quantify and mitigate discrimination amidst non-IID graph data, although graph fairness has largely remained nascent. This work presents the first thorough study of fairness amidst non-IID graph data for researchers and practitioners to have a better understanding of the current landscape of graph fairness while complementing existing fairness surveys solely focusing on traditional IID data.
Key Insights
IIDness VS Non-IIDness on fairness
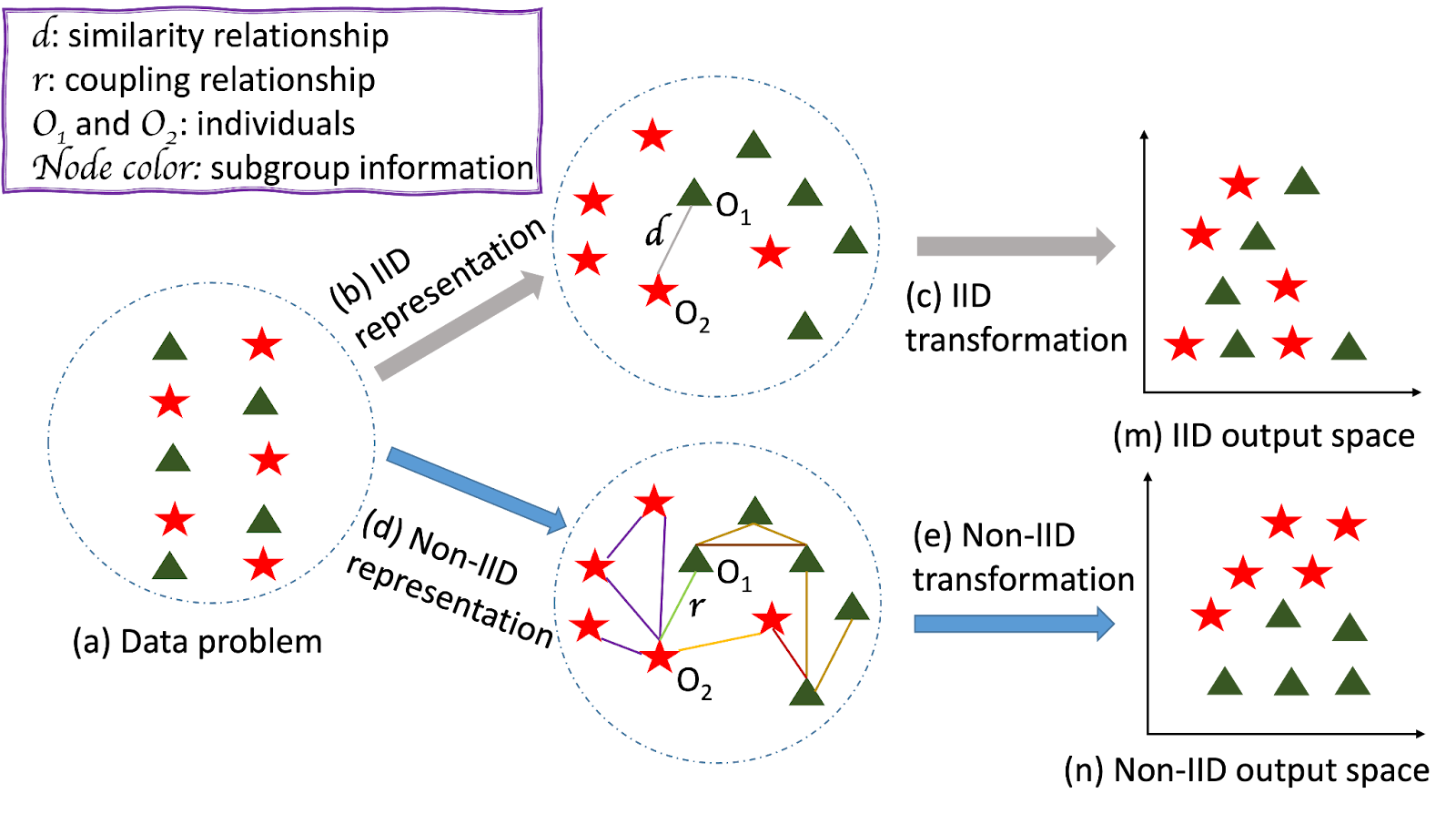
Figure 1. An illustrative example of IIDness and fair IID learning vs. Non-IIDness and fair Non-IID graph learning: (a) Data problem; (b) and (d) Data representation comparison; (c) and (e) Mapping transformation comparison; (m) and (n): Output space of methods with different assumptions.
Individuals of the same population are visualized in Figure 1(a) with each node representing an individual, subgroup membership information, e.g., gender, characterized by the color of the nodes, as well as connectivity and coupling information reflected by edge connection and color, respectively. These individuals are not independently distributed as the knowledge of one individual gives information about the other and vice versa due to their interconnectivity. Neither are identically distributed as their connectivities differ from each other and are not drawn from the same distribution. Specific to this toy example, the connectivity of nodes O1 and O2 differ and the presence of O1 affects the information of O2 and vice versa. Therefore, fairness on non-IID graph data needs to reflect and capture such a coupling relationship when addressing discrimination (see Figure 1(d) and (e)), while traditional fairness literature ignores or simplifies it, e.g., similarity relationship (see Figure 1(b) and (c)). As can be seen in Figure 1(m) and (n), the output space, e.g., classification results, of non-IID mapping transformation could be biased towards certain subgroups although the input space of the data is uniformly distributed due to its structural and neighborhood information aggregation, while IID mapping transformation fails to capture such inherent bias.
Overview
A Table is provided as an overview of literature advancing such fairness research on non-IID graph data. We summarize each paper along five dimensions: type, methods, datasets, remarks and applications. Among them,
- Type and methods: are used to indicate the focused types of unfairness in each study, both bias measurement and corresponding mitigation (c.f., Section 3 and 4).
- Datasets: list the graph dataset sources for benchmarking (c.f., Section 5).
- Remarks: identify unique characteristics of each study, such as the capability to handle multiple sensitive attributes and flexibility in incorporating different combinations of fairness constraints.
- Applications: describe the supported predictive tasks of each study, such as link prediction, edge classification, node classification and clustering.
- We also highlight key advantages and drawbacks of each line of studies in Section 3 and 4 as well as discuss limitations and future directions in Section 6, thereby providing a unified review of fairness amidst non-IID graph data.
Discussion on quantifying graph unfairness
Among the graph fairness notions, the majority focus on group fairness. Compared with individual fairness, group fairness does not require additional metrics such as dissimilarity and ranking function for fairness quantification. In addition, they enjoy the merit of fewer information requirements. For example, only the sensitive attribute information is needed for computing, and it can be generalized to handle multiple sensitive attributes simultaneously. Doing so for individual fairness is not straightforward. On the other hand, individual fairness offers a much finer granularity of fairness at the node level. Consequently, it is also more difficult to fail. For example, the classifier can grant qualified individuals from one group for benefits while randomly granting individuals from another group to still meet the group fairness constraints, which can be scrutinized at the individual level and is therefore more reliable.
Discussion on mitigating graph unfairness
As with fairness notions, most of the graph fairness methods pay attention to the group level fairness. Among them, ensuring neutrality between the learned graph embedding and sensitive attributes enjoys popularity. Various learning processes such as adversarial, disentangle and orthogonal can be employed to achieve this goal and are typically multiple sensitive attributes applicable and are possibly compositional. A major drawback of such processes is debiasing node embeddings without considering relational data given by pairs of nodes. Consequently, this line of work seems more tailored for fair node classification but its specificity for other tasks (e.g., link prediction taking node tuples as input) is not always guaranteed. Individual level and causal reasoning fairness are able to alleviate this drawback. However, the high computational cost associated with finer granularity level evaluation and modeling the causal relations on graphs particularly large scale ones significantly increases the computational challenge. In addition, bias mitigation on the degree related performance difference as well as understanding and ensuring fairness on graphs that are homogeneous in nature have been conducted.
Limitations and future directions
- There has been little research on mitigating bias represented by continuous sensitive attributes.
- There has been limited effort to understand fair dynamic graphs which poses unique challenges when non-IID data is further complicated by evolving networks.
- There also has been little attention paid to domain specific fair graph learning.
- The study of privacy on graphs is also directly related to fairness on graphs due to the natural overlaps between privacy and fairness.
- Relevantly, the topic of explainability is also directly related in aid of debugging ML models and uncover biased decision-making.
Between the lines
Despite the increasing attention on fairness in machine learning, existing studies have mainly focused on IID data scenarios. This work surveys fairness amidst non-IID graph data, which is a general language for describing and modeling many real-world socially sensitive applications but remains largely underexplored. To this end, we first discuss non-IIDness in graph data and graph non-IIDness on fairness in comparison to traditional ML fairness with IID assumption. The recent literature on fair graph mining is then summarized and integrated based on five taxonomic dimensions along with critical analysis of the relevant methods, providing the perspective of the work in the field. In addition, a rich collection of benchmark datasets and evaluation metrics are identified to facilitate future fair graph mining development. Finally, we discuss limitations and future directions as pointers for further advances.