


🔬 Research Summary by Souvic Chakraborty, Founder & CEO @Neurals.ai, Ph.D. scholar (TCS research fellow) in the Computer Science and Engineering department at IIT Kharagpur, India, jointly supervised by Prof. Animesh Mukherjee & Prof. Pawan Goyal, working in the area of few-shot learning, self-supervision & NLP Applications.
[Original paper by Souvic Chakraborty, Parag Dutta, Sumegh Roychowdhury, and Animesh Mukherjee]
Overview:
“Put your sword back in its place,” Jesus said to him, “for all who draw the sword will die by the sword.” because “hate begets hate” – Gospel of Matthew, verse 26:52.
We draw inspiration from these words and the empirical evidence of the clustering tendency of hate speech provided in the works of Matthew et al. (2020) to design two loss functions incorporating user-anchored self-supervision and contextual regularization in hate speech. These are incorporated in the pretraining and finetuning phases to improve automatic hate speech detection in social media significantly.
Introduction
Hate speech classification is a binary (hate/non-hate) or ternary (hate/offensive/neutral) classification task, and the loss generally employed for training is cross-entropy (or mean squared error in case one is solving the regression version of the task). In addition, we employ one more loss for contextual regularization for smoother training. We also add a pretraining phase for user-anchored self-supervision, as explained below.
User Anchored Self Supervision
Basic assumption:
Hateful users are distinct from non-hateful users in their language use.
Deduction:
Embeddings of sentences from hateful users should cluster together but be distant from the embeddings of sentences from non-hateful users and vice versa.
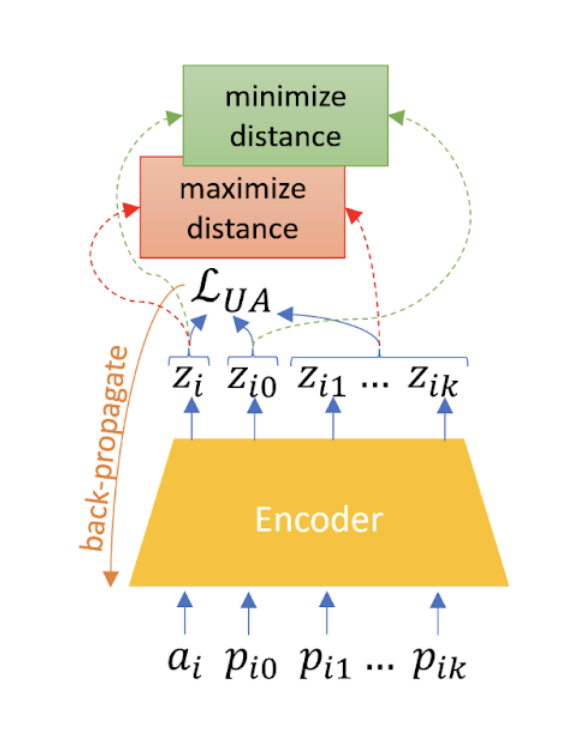
Operationalization:
Embeddings of sentences (derived from BERT – also retrained in this phase as part of the end-to-end architecture) from the same user should cluster together but be distant from the embeddings of sentences from other users.
We do not need any labeled data for this phase. It is possible to collect extensive social media data and train models on it. In our case, we train the UA phase of our model on GAB and Reddit’s corpus.
Making the pretraining phase robust
Aligning the pre-training objective with the fine-tuning objective is crucial. To do this better, we introduce a variant of supervised contrastive loss (Khosla et al. (2021)) to regularize the UA phase bringing embeddings of hateful comments closer while facilitating distance from the embeddings of the non-hateful comments. A convex combination of both losses has been used as the final loss function to learn the embedding space better.
Contextual regularization
Our central assumption in this phase is that if we find a random occurrence of hate speech, the sentences in the vicinity of that hate speech (either sentence uttered by the same user or sentences in the same thread) are also likely to be hate speech.
We soft annotate hate speech based on the vicinity to other sentences annotated as hate speech. Thus, we use these soft-annotated examples to regularize the gold-level data using an additional loss function.
Results:
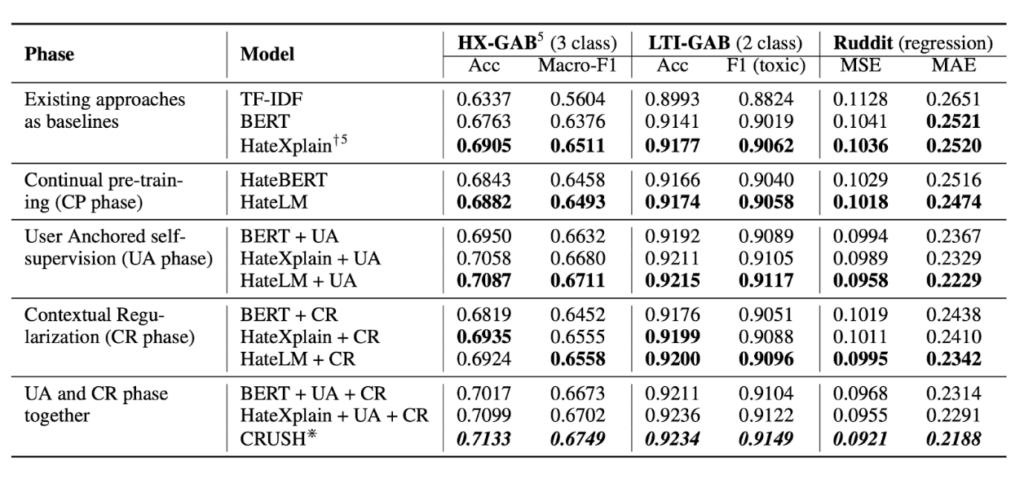
We see improvements in both UA and CR phases. In addition, pretraining on Masked Language Modelling loss has helped our model. Most importantly, our model has significantly outperformed BERT models with additional annotated data (HateXplain) without needing those annotations.
Fewshot improvements
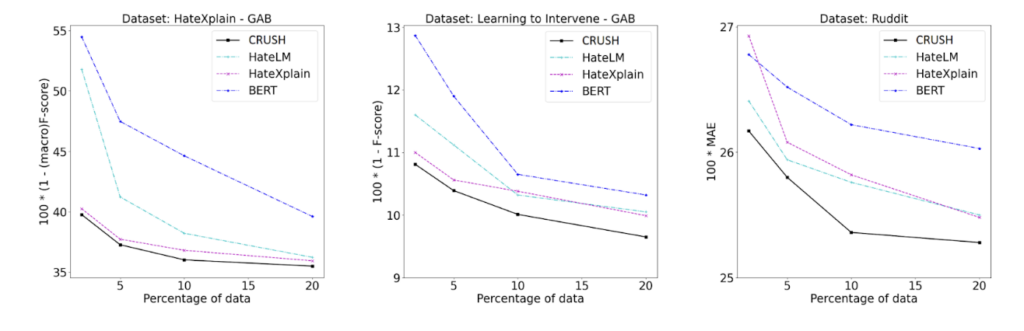
We repeat the experiments using only a part of the data in training for all competing algorithms. We see that our improvements are even more significant in a low-resource setting with only a few examples in hand. This shows the strength of our representation learning. Our pretraining method could cluster hateful sentences better than vanilla language models, commanding better accuracy with fewer annotated training samples in the finetuning stage for all three datasets.
Between the lines
- Self-supervised user attribution pre-training objective combined with the contextual regularization objective on top of traditional MLM for hate speech tasks. We empirically demonstrate the advantage of our methods by improving over existing competitive baselines in hate speech detection and scoring tasks across three different datasets.
- CRUSH performs superior in the low-data regime compared to existing approaches. Ablations show the benefits of each objective separately.
- Future works include
- exploiting the relations among users,
- using different base models capable of incorporating more extended contexts,
- address challenging problems like sarcasm and implicit hate speech detection in social networks.
Is the task solved?
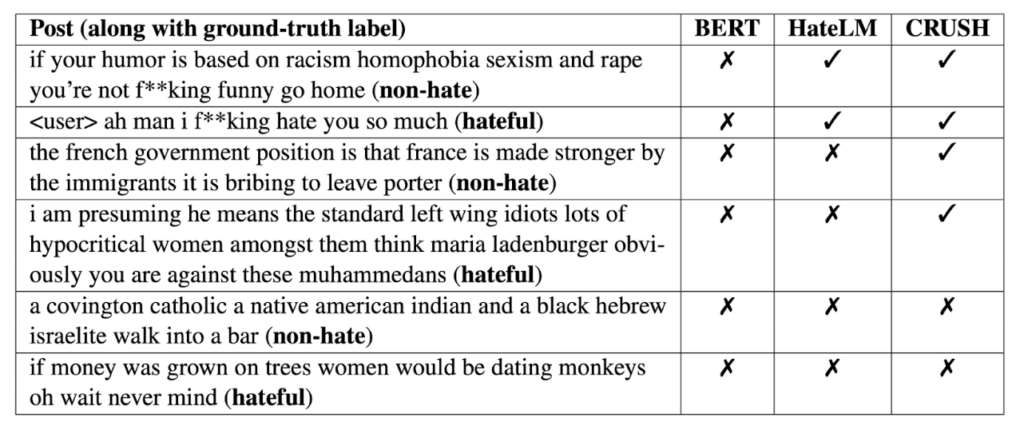
Our qualitative analysis shows that the task is yet far from solved despite using domain knowledge-based self-supervision on a large text corpus. While texts containing cuss words are easier to be classified, convoluted sentences and sarcastic utterances are still not always classified correctly.
Moreover, grouping texts by users may carry the inherent risk of grouping texts by communities/ethnicities, as some communities can share unique linguistic styles. This has the potential to introduce bias in hate speech classification. But this problem is present for any language model pretrained on social media corpus. So, we need to develop methods in the future to reduce that bias in the representation learning phase. So, the path to better hate speech classification is still full of challenges and excitement!
References
- Souvic Chakraborty, Parag Dutta, Sumegh Roychowdhury, and Animesh Mukherjee. 2022. CRUSH: Contextually Regularized and User anchored Self-supervised Hate speech Detection. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 1874–1886, Seattle, United States. Association for Computational Linguistics.
- Binny Mathew, Anurag Illendula, Punyajoy Saha, Soumya Sarkar, Pawan Goyal, and Animesh Mukherjee. 2020. Hate begets Hate: A Temporal Study of Hate Speech. Proc. ACM Hum.-Comput. Interact. 4, CSCW2, Article 92 (October 2020), 24 pages.
- Khosla, Prannay, et al. “Supervised contrastive learning.” Advances in Neural Information Processing Systems 33 (2020): 18661-18673.
- Kenton, Jacob Devlin Ming-Wei Chang, and Lee Kristina Toutanova. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” Proceedings of NAACL-HLT. 2019.