

🔬 Research Summary by Usman Gohar, a Ph.D. student in the Department of Computer Science at Iowa State University with a research focus on the safety and fairness of ML-based software.
[Original paper by Usman Gohar and Lu Cheng]
Overview: The increasing use of ML/AI in critical domains like criminal sentencing has sparked heightened concerns regarding fairness and ethical considerations. Many works have established metrics and mitigation techniques to handle such discrimination. However, a more nuanced form of discrimination, called intersectional bias, has recently been identified, which spans multiple axes of identity and poses unique challenges. In this work, we review recent advances in the fairness of ML systems from an intersectional perspective, identify key challenges, and provide researchers with clear future directions.
Introduction
The increasing adoption of Machine Learning (ML) in critical areas like loans, criminal sentencing, and hiring has raised concerns about fairness. Extensive research has focused on group and individual fairness, but predominantly along a single axis of identity, such as gender or race. This independent fairness approach fails to capture the discrimination at the intersection of these identities. Coded by Kimberlé Crenshaw, intersectional group fairness recognizes the nuanced experiences of individuals with overlapping social identities. Most notably, major tech companies faced public scrutiny for accuracy disparities for Black women exhibited by their facial recognition algorithms, leading to bad press and subsequent pullback of those systems.
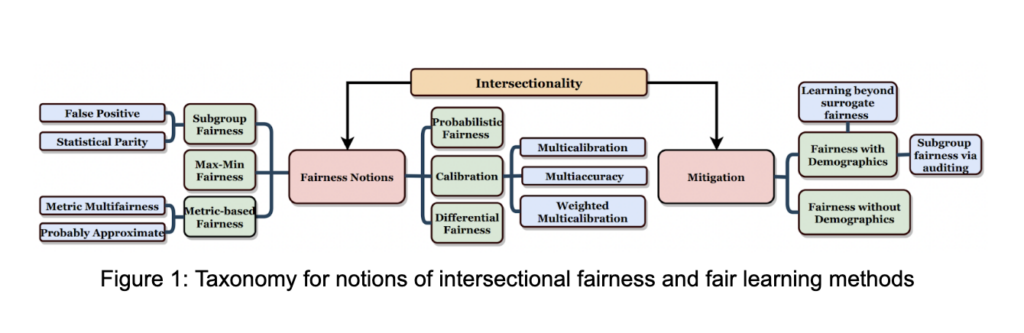
Intersectional group fairness presents unique challenges compared to the binary view of fairness in the independent case. Determining the level of granularity at which fairness should be ensured for intersectional groups is one such challenge. Additionally, smaller subgroups within intersectional identities suffer from higher data sparsity, leading to increased uncertainty and no representation. Moreover, intersectional identities can amplify biases not present in their constituent groups (e.g., Black woman vs. Black or Woman), rendering traditional mitigation techniques ineffective. In this work, we propose the first taxonomy (Figure 1) for notions of intersectional fairness and fair learning methods to mitigate such biases. Furthermore, we thoroughly review techniques across various domains of AI (NLP, RecSys, etc.), discuss their limitations, and highlight future research directions and challenges.
Key Insights
Notions of Intersectional Fairness:
Intersectionality challenges the notion of fairness based solely on independent protected groups, such as gender. It recognizes that the accumulation of discrimination experiences cannot be confined to individual groups alone. Predictors may seem fair when evaluated independently, but disparities can emerge at the intersections of these groups. However, ensuring fairness at all levels of intersectional groups is infeasible due to potentially infinite overlapping subgroups. To handle this computational challenge, we identified six different notions of intersectional fairness in literature: (1) Subgroup Fairness; (2) Max-Min Fairness; (3) Metric-based Fairness; (4) Calibration; (5) Probabilistic; and (6) Differential Fairness. We refer the reader to the full paper for detailed descriptions of these notions.
Limitations: Most of the notions identified above depend on the discrimination faced by the most disadvantaged group across the intersections. These notions only differ in their approaches for identifying and limiting the vast number of such subgroups to measure fairness efficiently. However, such approaches risk participating in the same fairness gerrymandering they seek to resolve due to the arbitrary nature of limiting subgroups based on computational methods. This highlights the need for a broader involvement of stakeholders to design notions and not simply rely on computational methods.
Fair Intersectional Learning:
Significant efforts have been made to tackle bias and enhance fairness in ML systems. However, comparatively fewer fair learning algorithms have been designed to address the distinct challenges of intersectional fairness. We identify two approaches; 1) Intersectional Fairness with Demographics and 2) Intersectional Fairness without Demographics. Simply, the former assumes access to demographic information, while the latter attempts to ensure fairness across intersectional groups without using any demographic information. Approaches to address bias in model learning typically target the training data (pre-processing), learning algorithm (in-processing), or predictions (post-processing). When considering intersectional fairness with demographics, the focus primarily lies in the latter two categories. In our work, we provide a detailed review of the techniques under these approaches.
Limitations: One of the main weaknesses of the reviewed approaches is that they rely on very specific surrogate notions of fairness we discussed above. This prevents broad adoption and evaluation of ML/AI systems with an intersectional lens. Again, these techniques are also susceptible to ignoring subgroups that do not conform to underlying statistical “efficiency” requirements. On the other hand, Intersectional Fair learning without demographics utilizes strong demographic signals in the data to ensure fairness across intersecting groups. These methods fail when these signals are absent or when a particular subgroup is underrepresented. Therefore, future work can explore leveraging common patterns shared with related groups to ensure fairness in such cases.
Applications in other AI Domains
Most of the work in the literature is focused on classification tasks on i.i.d data. However, more research is emerging in other AI domains, such as Natural Language Processing (NLP), Recommender Systems (RecSys), and Auditing & Visualization. Many studies have been conducted to benchmark NLP systems with respect to intersectional bias. These have identified biases mostly along the intersections of gender and race. More recently, these have been extended to other protected attributes such as religion, sexuality, political affiliation, etc. It has demonstrated the need for comprehensive evaluations of current algorithms and practices with an intersectional perspective. Furthermore, we review mitigation for RecSys and auditing techniques that can be utilized to test systems for intersectional bias rigorously. Given increasing regulatory and privacy concerns, more research is needed to understand potential correlations in data that can be leveraged to tackle intersectional biases without access to demographic data in these domains. Finally, data sparsity is a big challenge. To alleviate this, we have identified datasets across different domains. Our consolidated summary provides researchers convenient access to datasets with rich subgroup information.
Between the lines
This work examined recent developments in the fairness of ML systems with an intersectional lens. Intersectionality presents distinct challenges that conventional bias mitigation algorithms and metrics struggle to address effectively. The presence of intersectional bias in public-facing systems like facial algorithms, large language models (like GPT-3), etc., has underscored the importance of this problem. Still, numerous challenges need to be addressed. One such challenge is to develop generalized mitigation techniques to enable broad adoption in the ML community. More work is needed to develop test cases to audit predictors for intersectional biases and develop more inclusive datasets with diverse stakeholders. We hope this work serves as a call to attention for further research to tackle the challenges exhibited by intersectional fairness.